
Cheng-Yu Hsieh
@cydhsieh
Followers
585
Following
142
Media
26
Statuses
54
Excited to introduce FocalLens: an instruction tuning framework that turns existing VLMs/MLLMs into text-conditioned vision encoders that produce visual embeddings focusing on relevant visual information given natural language instructions!. 📢: @HPouransari will be presenting

1
8
29
RT @jae_sung_park96: 🔥We are excited to present our work Synthetic Visual Genome (SVG) at #CVPR25 tomorrow! .🕸️ Dense scene graph with d….
0
8
0
RT @PeterSushko: 1/8🧵 Thrilled to announce RealEdit (to appear in CVPR 2025)! We introduce a real-world image-editing dataset sourced from….
0
8
0
RT @jramapuram: Stop by poster #596 at 10A-1230P tomorrow (Fri 25 April) at #ICLR2025 to hear more about Sigmoid Attention! . We just pushe….
0
14
0
🙏Huge thanks to my amazing collaborators @Apple MLR!! @PavankumarVasu @FartashFg @raviteja_vemu @chunliang_tw @RanjayKrishna @OncelTuzel @HPouransari.
0
0
0
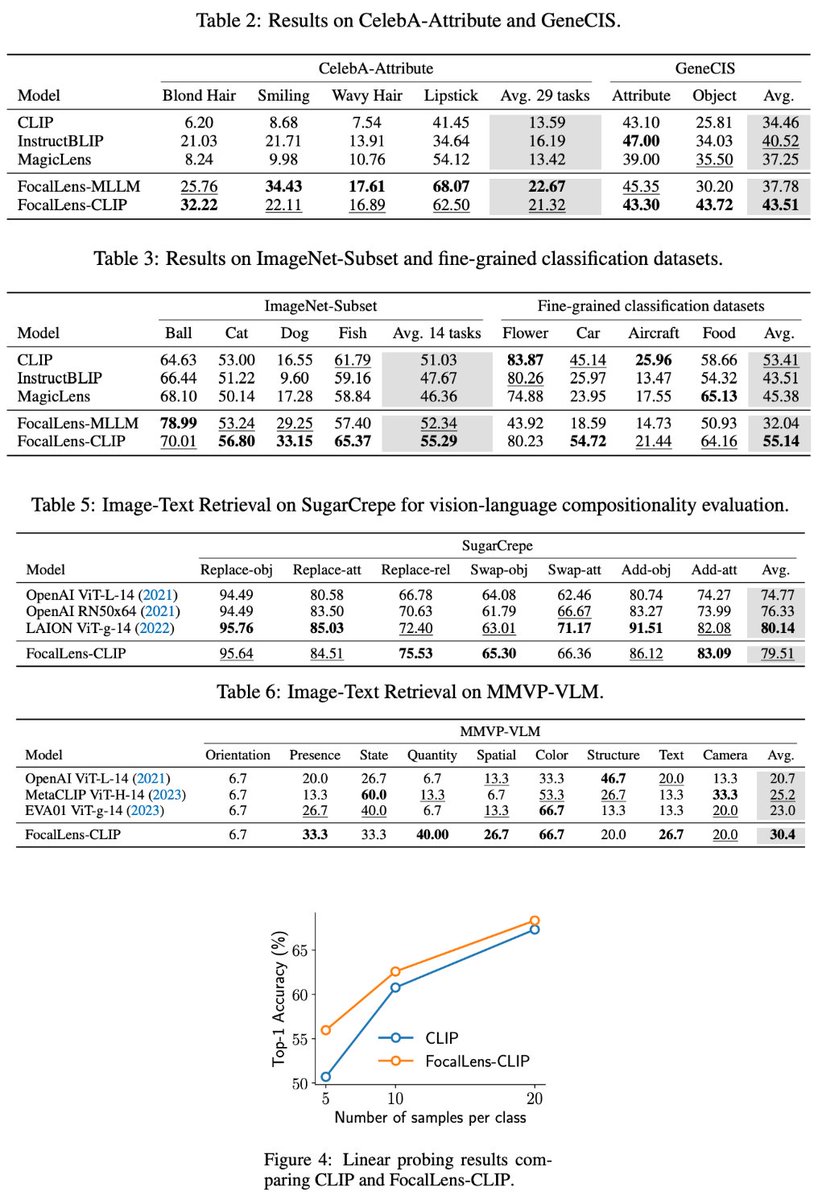
🚀Being able to better focus on the relevant visual information, FocalLens shows improvements over standard CLIP models on a variety of downstream tasks, including image-image retrieval, image-text retrieval, and classification tasks!
1
0
0
We train FocalLens using visual instruction tuning data in the form of (image, instruction, output), by aligning the instruction-conditioned visual representations of the images to their corresponding outputs.

1
0
0
‼️Most vision encoders generate fixed representations independent of the task or context of interest. For example, CLIP embeddings emphasize high-level semantics but often omit finer-grained details such as background, quantity, or spatial relations — which can be critical for

1
0
1
RT @JieyuZhang20: The 2nd Synthetic Data for Computer Vision workshop at @CVPR! We had a wonderful time last year, and we want to build on….
0
9
0
RT @MahtabBg: I'm exited to announce that our work (AURORA) got accepted into #CVPR2025🎉! Special thanks to my coauthors: @ch1m1m0ry0, @cyd….
0
4
0
RT @YungSungChuang: (1/5)🚨LLMs can now self-improve to generate better citations✅. 📝We design automatic rewards to assess citation quality….
0
77
0
RT @YungSungChuang: I will be presenting our Lookback Lens paper at #EMNLP2024 in Miami!. 📆 Nov 13 (Wed) 4:00-5:30 at Tuttle (Oral session:….

arxiv.org
When asked to summarize articles or answer questions given a passage, large language models (LLMs) can hallucinate details and respond with unsubstantiated answers that are inaccurate with respect...
0
5
0
RT @kamath_amita: Hard negative finetuning can actually HURT compositionality, because it teaches VLMs THAT caption perturbations change me….
arxiv.org
Several benchmarks have concluded that our best vision-language models (e.g., CLIP) are lacking in compositionality. Given an image, these benchmarks probe a model's ability to identify its...
0
10
0
🤔 In training vision models, what value do AI-generated synthetic images provide compared to the upstream (real) data used in training the generative models in the first place?. 💡 We find using "relevant" upstream real data still leads to much stronger results compared to using.

Will training on AI-generated synthetic data lead to the next frontier of vision models?🤔. Our new paper suggests NO—for now. Synthetic data doesn't magically enable generalization beyond the generator's original training set. 📜: Details below🧵(1/n).
0
3
10
‼️ LLMs hallucinate facts even if provided with correct/relevant contexts.💡 We find models' attention weight distribution on input context versus their own generated tokens serves as a strong detector for such hallucinations.🚀 The detector transfers across models/tasks, and can.

🚨Can we "internally" detect if LLMs are hallucinating facts not present in the input documents? 🤔. Our findings:.- 👀Lookback ratio—the extent to which LLMs put attention weights on context versus their own generated tokens—plays a key role.- 🔍We propose a hallucination

0
6
36
🧵(n/n).🚀A huge shout out to our amazing team that makes this work possible: @YungSungChuang, @chunliang_tw , @ZifengWang315 , Long T. Le, Abhishek Kumar, James Glass, @ajratner, @chl260, @RanjayKrishna, @tomaspfister!!.
0
0
4
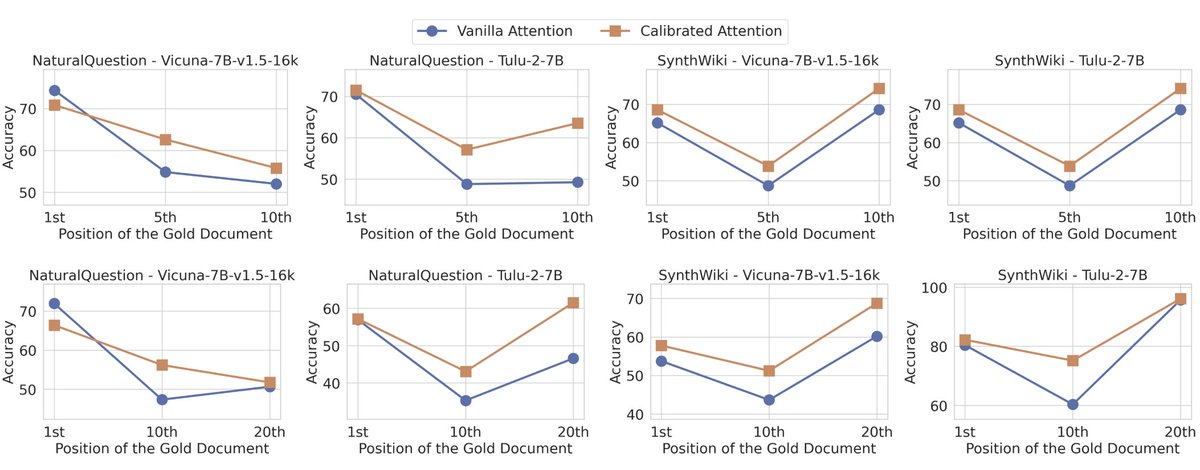
🧵(5/n).3⃣Finally, we show our method is complementary to existing re-ordering based methods that place relevant documents at the beginning/end of the input prompt, offering a new layer to improve current RAG pipelines.

1
0
5
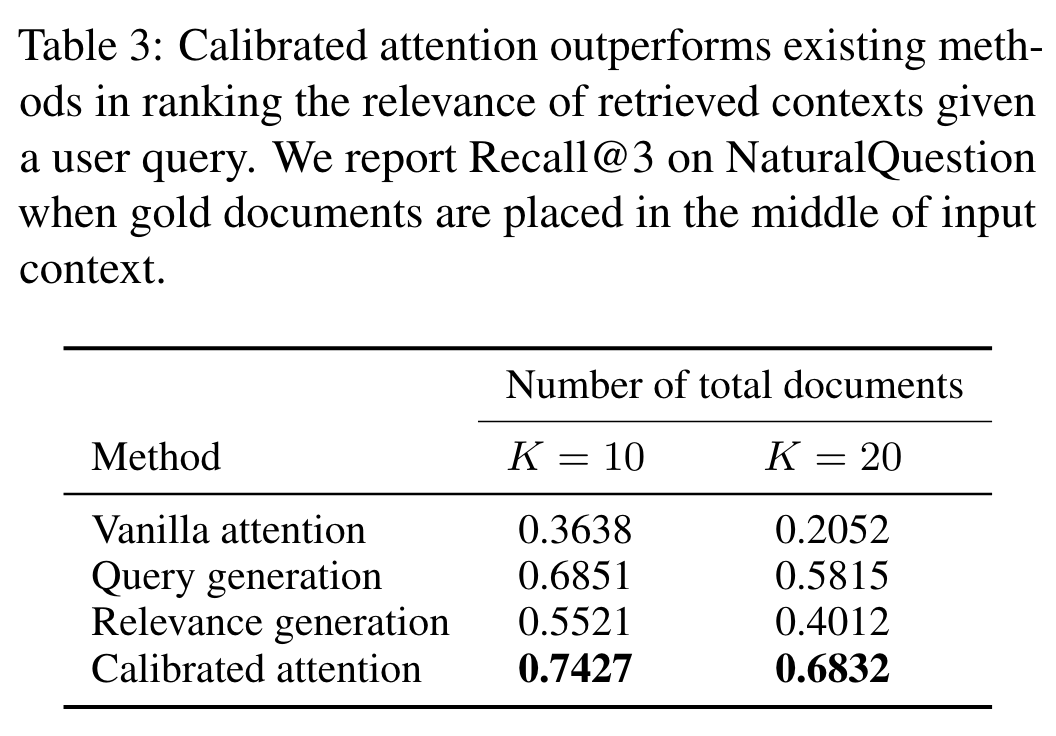
🧵(4/n) We show that:.1⃣Models' calibrated attention reflects well the relevance of a document to a user query, outperforming existing re-ranking metrics. 2⃣Calibrated attention further improves models' RAG performances (over 10 pp) against the standard baseline.
1
0
3