
Pavankumar Vasu
@PavankumarVasu
Followers
153
Following
36
Media
2
Statuses
35
Joined July 2013
RT @FartashFg: 🚨📅The submission deadline for #NeurIPS 2025 CCFM Workshop is just 8 days away on August 22. Get your papers in!.Submit your….

sites.google.com
Foundation models, despite their impressive capabilities, face a critical challenge: they naturally become outdated. Trained on vast datasets, frequently updating these models is expensive. Crucial...
0
1
0

RT @maxseitzer: Introducing DINOv3 🦕🦕🦕. A SotA-enabling vision foundation model, trained with pure self-supervised learning (SSL) at scale.….
0
139
0
RT @andimarafioti: 🚀 We're thrilled to launch four new OCR datasets with 20M images: DoclingMatix, SynthFormulaNet, SynthCodeNet, and Synth….
0
78
0
RT @teelinsan: Uncertainty quantification (UQ) is key for safe, reliable LLMs. but are we evaluating it correctly?. 🚨 Our ACL2025 paper f….
0
13
0
RT @HPouransari: 🌟Explore key insights from the FastVLM project (real-time vision-language model) in this blog post:. .
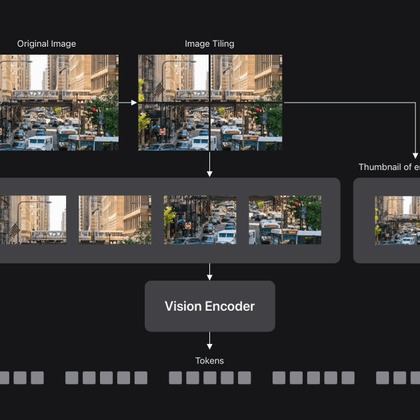
machinelearning.apple.com
Vision Language Models (VLMs) enable visual understanding alongside textual inputs. They are typically built by passing visual tokens from a…
0
38
0
RT @FartashFg: 📢Submissions are now open for #NeurIPS2025 CCFM workshop. Submission deadline: August 22, 2025, AoE. Website: https://t.co/….
openreview.net
Welcome to the OpenReview homepage for NeurIPS 2025 Workshop CCFM
0
6
0
RT @MustafaShukor1: We propose new scaling laws that predict the optimal data mixture, for pretraining LLMs, native multimodal models and l….
0
47
0
RT @RinMetcalfSusa: 📣 We are excited to present our work on inferring user preferences from writing samples at @icmlconf Poster Session 3 (….
0
3
0
RT @FartashFg: 🚀Super excited to share TiC-LM (Oral at #ACL2025)!.How to keep FMs up-to-date over months/years? We have a benchmark and lot….
sites.google.com
Foundation models, despite their impressive capabilities, face a critical challenge: they naturally become outdated. Trained on vast datasets, frequently updating these models is expensive. Crucial...
0
2
0
RT @ryan_hoque: Imitation learning has a data scarcity problem. Introducing EgoDex from Apple, the largest and most diverse dataset of de….
0
95
0
Huge thanks to team and collaborators:.@HPouransari, David Koski, Christopher Webb, @FartashFg, @chunliang_tw, Cem, Nate, Albert, Gokul, James, Peter and @OncelTuzel.
0
0
8
RT @cydhsieh: Excited to introduce FocalLens: an instruction tuning framework that turns existing VLMs/MLLMs into text-conditioned vision e….
0
8
0
RT @MartinKlissarov: Here is an RL perspective on understanding LLMs for decision making. Are LLMs best used as: .policies / rewards / tra….
0
30
0
RT @YizheZhangNLP: Excited to share our new paper on "Reversal Blessing" - where thinking BACKWARDS makes language models smarter on some m….
0
30
0
RT @samira_abnar: 🚨 One question that has always intrigued me is the role of different ways to increase a model's capacity: parameters, par….
0
67
0
RT @HPouransari: 📢📢📢. We released the code for dataset-decomposition [NeurIPS 2024]: a simple method to speed up LLM pre-training using seq….
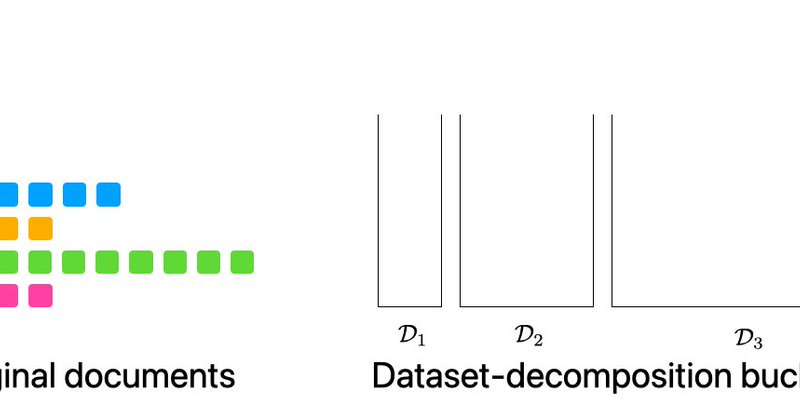
github.com
Official repo of dataset-decomposition paper [NeurIPS 2024] - apple/ml-dataset-decomposition
0
6
0
RT @ryan_hoque: 🚨 New research from my team at Apple - real-time augmented reality robot feedback with just your hands + Vision Pro! . Pape….
0
41
0
RT @HPouransari: What matters for runtime optimization in Vision Language Models (VLMs)? Vision encoder latency 🤔? Image resolution 🤔? Numb….
0
21
0