
Sarah Schwettmann
@cogconfluence
Followers
3K
Following
6K
Media
339
Statuses
2K
Co-founder and Chief Scientist, @TransluceAI, prev @MIT
dessert of the real
Joined October 2015
All @TransluceAI work that I described in my NeurIPS mech interp workshop keynote is now out! ✨ Today we released Predictive Concept Decoders, led by @vvhuang_ Paper: https://t.co/rIbp0ckIz8 Blog: https://t.co/6e37ZMUuBs And here's @damichoi95's work on scalably extracting

We can train models on maximizing how well they explain LLMs to humans 🤯@cogconfluence paraphrased. Mechanistic Interpretability Workshop #NeurIPS2025.
0
15
81
Transluce is developing end-to-end interpretability approaches that directly train models to make predictions about AI behavior. Today we introduce Predictive Concept Decoders (PCD), a new architecture that embodies this approach.
1
27
136

I'm really proud of what our team at @TransluceAI has accomplished in the last year! Take a moment to read our end-of-year post to learn what we're up to, and please reach out if you're interested in supporting us!

Transluce is running our end-of-year fundraiser for 2025. This is our first public fundraiser since launching late last year.
1
7
62

Today we are announcing the creation of the AI Evaluator Forum: a consortium of leading AI research organizations focused on independent, third-party evaluations. Founding AEF members: @TransluceAI @METR_Evals @RANDCorporation @halevals @SecureBio @collect_intel @Miles_Brundage
6
51
165

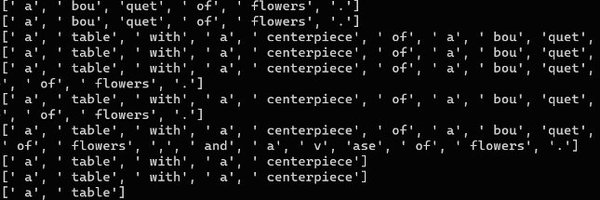
Have you ever had ChatGPT give you personalized results out of nowhere that surprised you? Here, the model jumped straight to making recommendations in SF, even though I only asked for Korean food!
1
17
45
Independent AI assessment is more important than ever. At #NeurIPS2025, Transluce will help launch the AI Evaluator Forum, a new coalition of leading independent AI research organizations working in the public interest. Come learn more on Thurs 12/4 👇 https://t.co/5Nzf9E2SPV

luma.com
Join us for the public launch of the AI Evaluator Forum, a collaborative network of leading independent AI evaluation organizations working in the public…
4
14
68
My favorite part of @damichoi95’s new paper (alongside 2 new datasets!) is the scaled up investigator pipeline that directly decodes open-ended user representations from model internals end-to-end interp is increasingly promising and I'm excited for more work in this direction
What do AI assistants think about you, and how does this shape their answers? Because assistants are trained to optimize human feedback, how they model users drives issues like sycophancy, reward hacking, and bias. We provide data + methods to extract & steer these user models.
0
6
23
Excited to share some of our progress in these directions during our lunch talks! You can also find me speaking about: *scalable oversight + indep evaluation @ the https://t.co/ifC7vIbeB9 alignment workshop 12/1-2 *end-to-end interp pipelines @ the mech interp workshop 12/7
0
0
5
We've been thinking a lot about: *what are the right measurements to make, and subroutines to automate? *how can we equip the ecosystem to not only make those measurements, but make sense of them? and build collective understanding of AI in a rapidly changing, complex landscape
1
0
2
Come say hi at #NeurIPS2025! @TransluceAI is hosting a lunch event on Thursday where we'll discuss our recent work on understanding AI systems and where we're headed next. Would love to see you there 👇
Transluce is headed to #NeurIPS2025! ✈️ Interested in understanding model behavior at scale? Join us for lunch on Thursday 12/4 to learn more about our work and meet members of the team: https://t.co/nOmFyTlsVs
1
1
8
Is your LM secretly an SAE? Most circuit-finding interpretability methods use learned features rather than raw activations, based on the belief that neurons do not cleanly decompose computation. In our new work, we show MLP neurons actually do support sparse, faithful circuits!
5
64
257
Transluce is partnering with @SWEbench to make their agent trajectories publicly available on Docent! You can now view transcripts via links on the SWE-bench leaderboard.
2
12
42

Can LMs learn to faithfully describe their internal features and mechanisms? In our new paper led by Research Fellow @belindazli, we find that they can—and that models explain themselves better than other models do.
5
53
248
We’re open-sourcing Docent under an Apache 2.0 license. Check out our public codebase to self-host Docent, peek under the hood, or open issues & pull requests! The hosted version remains the easiest way to get started with one click and use Docent with zero maintenance overhead.
Docent, our tool for analyzing complex AI behaviors, is now in public alpha! It helps scalably answer questions about agent behavior, like “is my model reward hacking” or “where does it violate instructions.” Today, anyone can get started with just a few lines of code!
1
13
78

Agent benchmarks lose *most* of their resolution because we throw out the logs and only look at accuracy. I’m very excited that HAL is incorporating @TransluceAI’s Docent to analyze agent logs in depth. Peter’s thread is a simple example of the type of analysis this enables,

OpenAI claims hallucinations persist because evaluations reward guessing and that GPT-5 is better calibrated. Do results from HAL support this conclusion? On AssistantBench, a general web search benchmark, GPT-5 has higher precision and lower guess rates than o3!
3
12
67
At Transluce, we train investigator agents to surface specific behaviors in other models. Can this approach scale to frontier LMs? We find it can, even with a much smaller investigator! We use an 8B model to automatically jailbreak GPT-5, Claude Opus 4.1 & Gemini 2.5 Pro. (1/)
5
38
246

@ImanolSchlag and team at SwissAI just released Apertus, a gorious 70B model trained on 1000+ languages. People across the #PublicAI network have been building a publicly hosted frontend for it: try it out via the new inference utility at https://t.co/Vy8bvBNyxX ! #SwissAIWeeks
publicai.co
A nonprofit, open-source service to make public and sovereign AI models more accessible.

We ran a full security & compliance evaluation of the just released 🇨🇭 Swiss LLM, 🤖 Apertus, developed by ETH Zurich & EPFL. Answers to most common questions below 👇 1/10
0
2
9
and a skyspace from James Turrell, whose work with light inspired my Vision in Art and Neuroscience class at MIT for nearly a decade. sf has a way of sneaking up on my senses with the surprisingly familiar 🫶
0
0
15
found two things in the de Young sculpture garden today that I had no idea were here! a beehive piece from Pierre Huyghe, who I worked with in 2022 to install a hive in simulation (along with a real one) on an island in Norway…
1
0
25