
Ce Zhang
@cezhhh
Followers
94
Following
41
Media
16
Statuses
30
CS phd student at UNC Chapel Hill.
Chapel Hill, NC
Joined September 2023
Work done with amazing collaborators: @yblin98 @ZiyangW00 @mohitban47 @gberta227 . Paper: Project Page: Code:

github.com
Official Implementation for "SiLVR : A Simple Language-based Video Reasoning Framework" - CeeZh/SILVR
0
0
1
Our framework offers several benefits. 1) Simplicity. No complex RL-based optimization or specialized modules for different tasks. 2) Generalizability. Can be applied to a wide range of complex video-language tasks. 3) Modularity. Enables seamless use of visual captioning models.
1
0
0
Our qualitative results also show SiLVR's strong reasoning ability. In the example below, the question asks which ingredient is not used in the video. Initially, SiLVR identified all listed items as potential ingredients. However, through self-correction, SiLVR correctly

1
0
0
The choice of visual captioners and LLMs plays an important role in our framework. NVILA 7B as the visual captioner provides the best accuracy-cost trade-off. DeepSeek R1 as the LLM leads to the highest overall accuracy.


1
0
0
We compare Adaptive Token Reduction (ATR) with static baselines that use fixed video clip lengths. A shorter clip variant (e.g., 1s) generates a large number of captions for long videos, which exceeds the context window of the LLMs. In contrast, a longer clips variant (e.g., 64s)

1
0
0
Compared to Llama 4, DeepSeek-R1 yields significantly larger performance gains on the video reasoning benchmarks. In contrast, while DeepSeek-R1 also produces better results on general video benchmarks, the improvements over Llama 4 are much smaller.


1
0
0
SiLVR also achieves SOTA performance on the challenging Knowledge Acquisition task in VideoMMMU and the Grounded VideoQA task in CGBench, showing strong generalizability.

1
0
0
We evaluate SiLVR on four video reasoning benchmarks and four general video benchmarks. As shown in the figures, SiLVR achieves SOTA performance on Video-MMMU (comprehension), Video-MMLU, Video-MME (long split, with subtitles), CGBench (MCQ), and EgoLife.

1
0
1
SiLVR reasons in the language space, but the limited context window of LLMs poses a significant challenge when processing long videos. We propose Adaptive Token Reduction, which dynamically adjusts the temporal granularity for sampling video tokens.

1
0
0
SiLVR does so by decomposing video-language QA into two stages: 1) extracting visual captions and transcribing speech into text, and 2) performing language-based reasoning over the extracted textual descriptions.

1
0
1
SiLVR addresses the limitations of existing RL-based MLLM reasoning methods, such as:.1) Costly CoT annotation. 2) Task-specific reward designs, leading to poor generalization. 3) Difficult optimization. 4) Similar or even worse performance than SFT approaches.
1
0
0
Recent advances in test-time optimization have led to remarkable reasoning capabilities in LLMs. However, the reasoning capabilities of MLLMs still significantly lag, especially for complex video-language tasks. We present SiLVR, a Simple Language-based Video Reasoning framework.


1
10
27
RT @YuluPan_00: 🚨 New #CVPR2025 Paper 🚨.🏀BASKET: A Large-Scale Dataset for Fine-Grained Basketball Skill Estimation🎥.4,477 hours of videos….
0
4
0
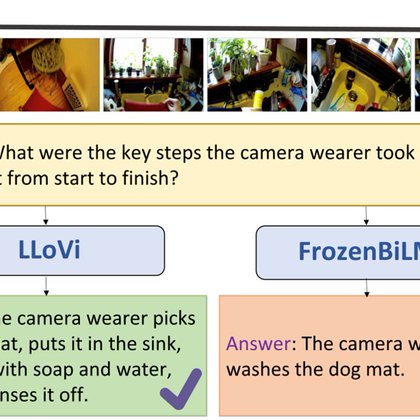
Excited to share that LLoVi is accepted to #EMNLP2024. We will present our work in poster session 12, Nov. 14 (Thu.) 14:00-15:30 ET. Happy to have a chat!. Check out our paper at: Code: Website:
sites.google.com
Motivation
First, LLoVi uses a short-term visual captioner to generate textual descriptions of short video clips (0.5-8s in length) densely sampled from a long input video. Afterward, an LLM aggregates the short-term captions to perform long-range temporal reasoning.

0
3
19
RT @KevinZ8866: (0/7) #ICLR2024 How could LLM benefit video action forecasting? Excited to share our ICLR 2024 paper: AntGPT: Can Large Lan….
0
2
0
RT @gberta227: The 3rd Transformers for Vision workshop will be back at #CVPR2024! We have a great speaker lineup covering diverse Transfor….
0
22
0
RT @gberta227: The code is now publicly available at .
github.com
Official implementation for "A Simple LLM Framework for Long-Range Video Question-Answering" - CeeZh/LLoVi
0
12
0
Work done with amazing collaborators: @lu_taixi @mmiemon @ZiyangW23972334 @shoubin621 @mohitban47 @gberta227.
0
0
3
LLoVi also outperforms prior approaches on NeXT-QA and IntentQA by 4.1% and 3.1%, and it also achieves state-of-the-art performance on NeXT-GQA, a recently introduced grounded LVQA benchmark.



1
0
4
Our final method, built using the above-listed empirical insights, achieves 50.3% zero-shot LVQA accuracy on the full test set of EgoSchema, outperforming the previous best approach by 18.1%.

1
0
4