

Ben Athiwaratkun
@ben_athi
Followers
868
Following
2K
Media
59
Statuses
375
Leading Turbo Team @ Together AI. prev: @awscloud @MSFTResearch, @Cornell PhD.
Earth, the Milky Way.
Joined July 2014
Introducing: Bifurcated Attention -- Accelerating Massively Parallel Decoding with Shared Prefixes in LLMs @ #icml 2024. TL;DR -- We can generate hundreds of samples with the same latency as one without approximation for any attention-based LLMs. Poster session happening on

2
11
53
RT @togethercompute: 🤖OpenAI's open models are here. gpt-oss models just landed on Together AI. Achieves near-parity with o4- mini, train….
0
23
0
Blog post on how we achieve the world’s fastest inference speed on NVIDIA Blackwell -
together.ai
Together AI inference is now among the world’s fastest, most capable platforms for running open-source reasoning models like DeepSeek-R1 at scale, thanks to our new inference engine designed for...
0
0
0
If you’re at icml and interested in LMM efficiency research, come chat with us at Together AI Booth!.

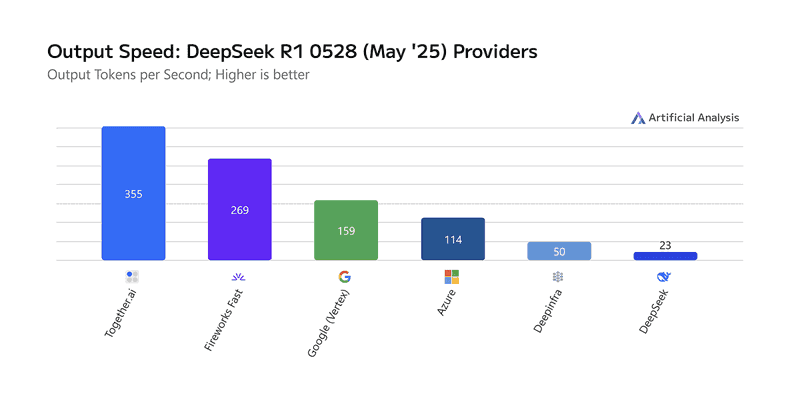
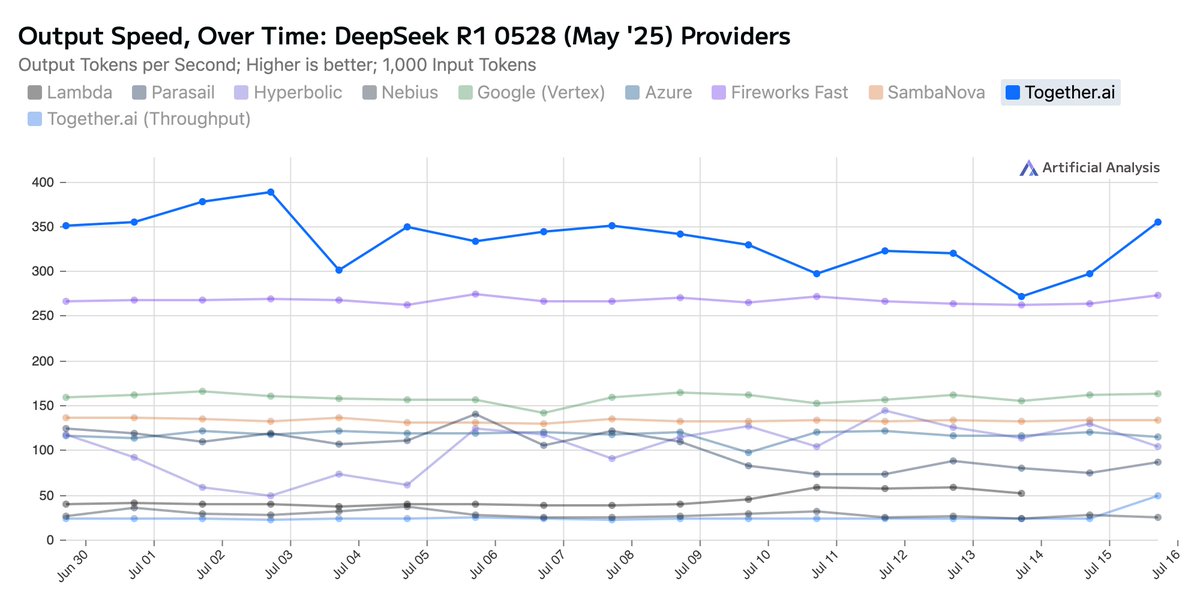
Together AI Sets a New Bar: Fastest Inference for DeepSeek-R1-0528. We’ve upgraded the Together Inference Engine to run on @NVIDIA Blackwell GPUs—and the results speak for themselves:.📈 Highest known serverless throughput: 334 tokens/sec.🏃Fastest time to first answer token:
1
0
4
TL;DR - one way to push the quality-efficiency frontier: . obtain high quality generations via a collection of LLMs -> distill to a smaller model -> get a higher quality small model that is more inference-efficient than the original collection of models. Poster session.

Work done during my internship at Together AI is being presented at #icml25. Come and check it out! . We propose a new model alignment pipeline that harness collective intelligence from open-source llms!

0
1
4
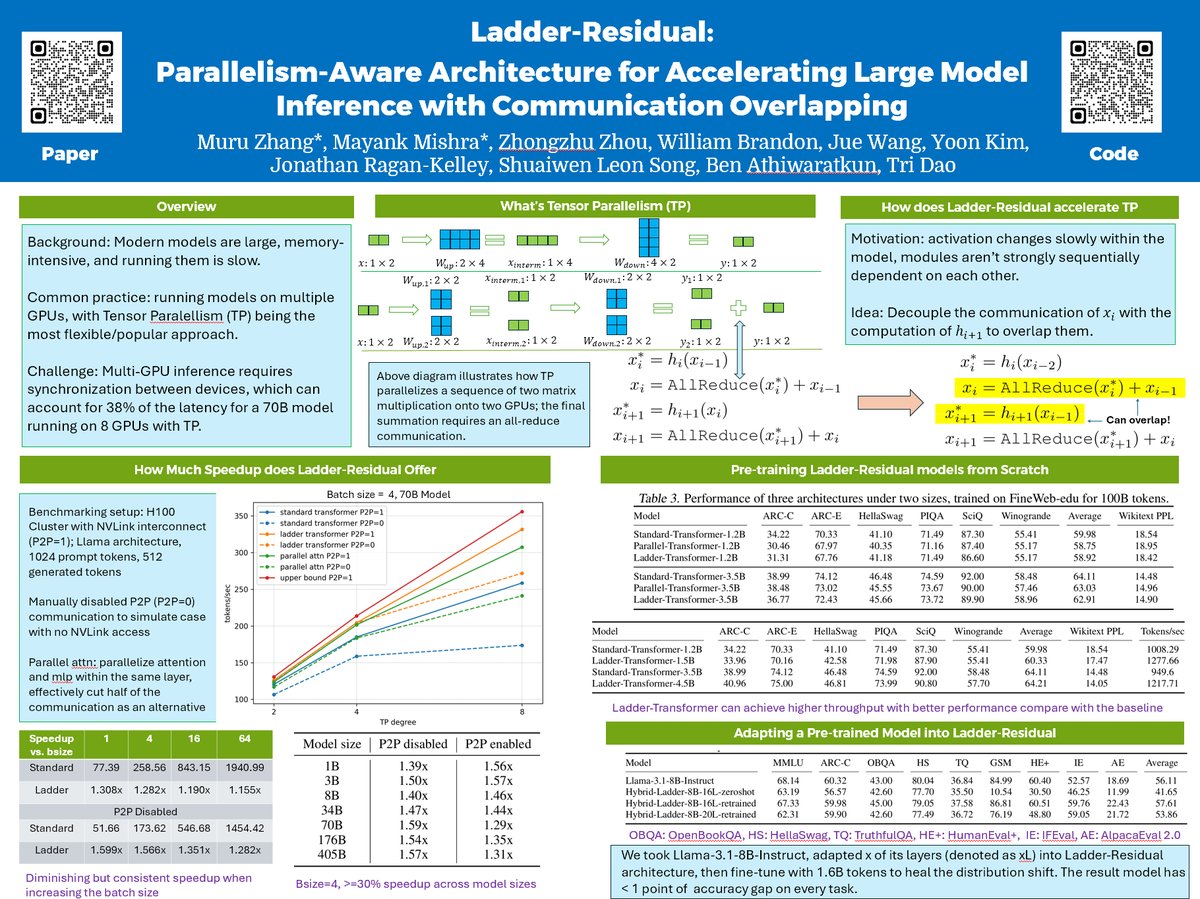
Come check out our poster on speeding up LLM, happening now til 1.30 pm. TL;DR — we show that we can hide the latency of all reduce operations in tensor parallel setting by modifying residual architecture to overlap MLP and attention.

I'm at #ICML2025, presenting Ladder-Residual ( at the first poster session tomorrow morning (7/15 11am-1:30pm), looking forward to seeing you at.West Exhibition Hall B2-B3 #W-1000!
0
0
6
RT @togethercompute: Announcing DeepSWE 🤖: our fully open-sourced, SOTA software engineering agent trained purely with RL on top of Qwen3-3….
0
80
0
RT @togethercompute: 🔓⚡ FLUX.1 Kontext [dev] just landed on Together AI. First open-weight model w/ proprietary-level image editing:. 🎨 Per….
0
6
0
Open Deep Research app + fully open recipe ☺️.
Introducing the Open Deep Research app!. Generate detailed reports on any topic with open source LLMs. Free & fully open source. We’re releasing everything: evaluation dataset, code, app, and blog.🔥
0
3
11
RT @JonSaadFalcon: How can we close the generation-verification gap when LLMs produce correct answers but fail to select them? .🧵 Introduci….
0
63
0
RT @vipulved: .@togethercompute is building 2 gigawatts of AI factories (~100,000 GPUs) in the EU over the next 4 years with the first phas….
0
18
0
RT @togethercompute: 🚀 New research: YAQA — Yet Another Quantization Algorithm (yes, pronounced like yaca/jackfruit 🥭). Led by @tsengalb99,….
0
5
0
RT @togethercompute: 🔔 New blog post on how we can attain large speedups for our inference customers using custom speculators! 🚀. Key benef….
0
5
0
If you're at ICLR and passionate about optimizing language models for speed and efficiency, swing by the Together AI booth for a chat.

1
31
70
RT @LindaHe49140661: Excited to share our work on scaling LLMs to handle million-token contexts! Training models for ultra-long sequences i….
0
45
0
RT @JunlinWang3: Excited to share work from my @togethercompute internship—a deep dive into inference‑time scaling methods 🧠. We rigorously….
0
54
0
Deep Research with open source models (+ open recipe).
Introducing Open Deep Research!. A fully open-source Deep Research tool that:.• writes comprehensive reports.• does multi-hop search and reasoning.• generates cover images & pod-casts!. We’re releasing everything: evaluation dataset, code and blog.🔥. Example output report👇
0
1
6
RT @AlpayAriyak: Excited to present our project in collaboration with Agentica: .14B LLM trained with Code RL that reaches OpenAI's o3-mini….
0
28
0
RT @togethercompute: Announcing DeepCoder-14B – an o1 & o3-mini level coding reasoning model fully open-sourced!. We’re releasing everythin….
0
347
0