

Alpay Ariyak
@AlpayAriyak
Followers
3K
Following
4K
Media
40
Statuses
246
LLM Post-Training Lead @ Together AI | OpenChat Project Lead (2M+ downloads, #1 7B LLM on Arena for 2+ months) | DeepCoder, DeepSWE
San Francisco, CA
Joined July 2023
🤖 Introducing DeepSWE-Preview, our latest model trained in collaboration with @Agentica_ . Using only RL, we increase the performance of Qwen 3 32B from 23% to 42.2% pass@1 (and 59.0% with TTS) on SWE-Bench Verified!


Announcing DeepSWE 🤖: our fully open-sourced, SOTA software engineering agent trained purely with RL on top of Qwen3-32B. DeepSWE achieves 59% on SWEBench-Verified with test-time scaling (and 42.2% Pass@1), topping the SWEBench leaderboard for open-weight models. Built in

4
8
59
RT @teortaxesTex: important correction on DeepSWE-Preview. on SWE-Bench-Verified:.Pass@1 = 42.2%."Best@8" = 59%, trajectory selection achie….
0
4
0
Let’s normalize reading through and actually understanding something before attempting to criticize it publicly :).

It's easy to confuse Best@K vs Pass@K—and we've seen some misconceptions about our results. Our 59% on SWEBench-Verified is Pass@1 with Best@16, not Pass@8/16. Our Pass@8/16 is 67%/71%. So how did we achieve this? . DeepSWE generates N candidate solutions. Then, another LLM

2
1
31
RT @Agentica_: It's easy to confuse Best@K vs Pass@K—and we've seen some misconceptions about our results. Our 59% on SWEBench-Verified….
0
15
0
Excited to introduce DeepSWE-Preview, our latest model trained in collaboration with @Agentica_ . Using only RL, we increase the performance of Qwen 3 32B from 23% to 42.2% on SWE-Bench Verified!

🚀 Introducing DeepSWE 🤖: our fully open-sourced, SOTA software engineering agent trained purely with RL on top of Qwen3-32B. DeepSWE achieves 59% on SWEBench-Verified with test-time scaling (and 42.2% Pass@1), topping the SWEBench leaderboard for open-weight models. 💪DeepSWE

1
4
38
RT @Agentica_: 🚀 Introducing DeepSWE 🤖: our fully open-sourced, SOTA software engineering agent trained purely with RL on top of Qwen3-32B.….
0
67
0
Excited to join some great friends at Nous as one of the judges for their first hackathon! It will be focused on RL environments. Pull up, it will be fun :).

Announcing the Nous RL Environments Hackathon in SF!. Create with Atropos, Nous' RL environments framework, and claim your stake of a $50,000 prize pool. Partners - @xai @nvidia @nebiusai @SHACK15sf @akashnet_ @LambdaAPI @tensorstax and @runpod_io . May 18th. Sign up below 👇👇

4
1
43
DeepCoder has reached the top of HuggingFace trending models 🥳

7
3
48
Our DeepCoder-14B LiveCodeBench v5 scores have been validated and put on the official leaderboard!
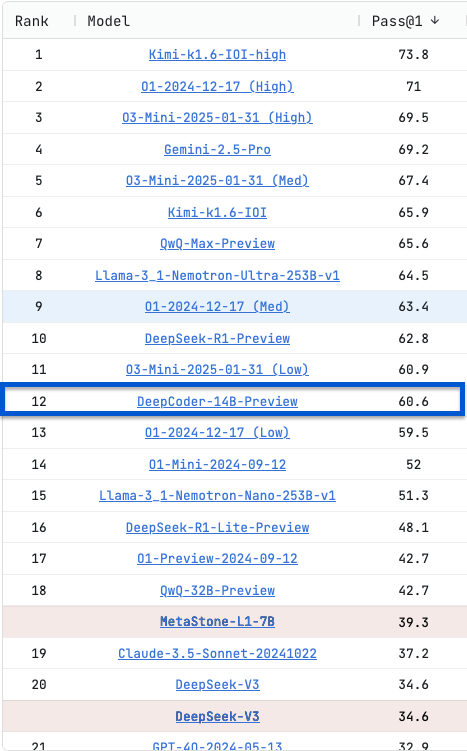
13
37
320
I’ve seen some people using DeepCoder-1.5B as speculator for DeepCoder-14B. Because the final stage for both was “self-play” RL, it won’t be a good speculator, as they diverge a lot. If there’s enough interest, we can train a good speculator (w/ logit distillation) & release.
1
1
8
New article from @VentureBeat about our model!.

DeepCoder delivers top coding performance in efficient 14B open model

1
0
10
RT @Agentica_: Introducing DeepCoder-14B-Preview - our fully open-sourced reasoning model reaching o1 and o3-mini level on coding and math.….
0
210
0
Excited to present our project in collaboration with Agentica: .14B LLM trained with Code RL that reaches OpenAI's o3-mini-low performance on coding benchmarks like LiveCodeBench, Codeforces and HumanEval! . We open source the code, data, weights and full recipe

Announcing DeepCoder-14B – an o1 & o3-mini level coding reasoning model fully open-sourced!. We’re releasing everything: dataset, code, and training recipe.🔥. Built in collaboration with the @Agentica_ team. See how we created it. 🧵
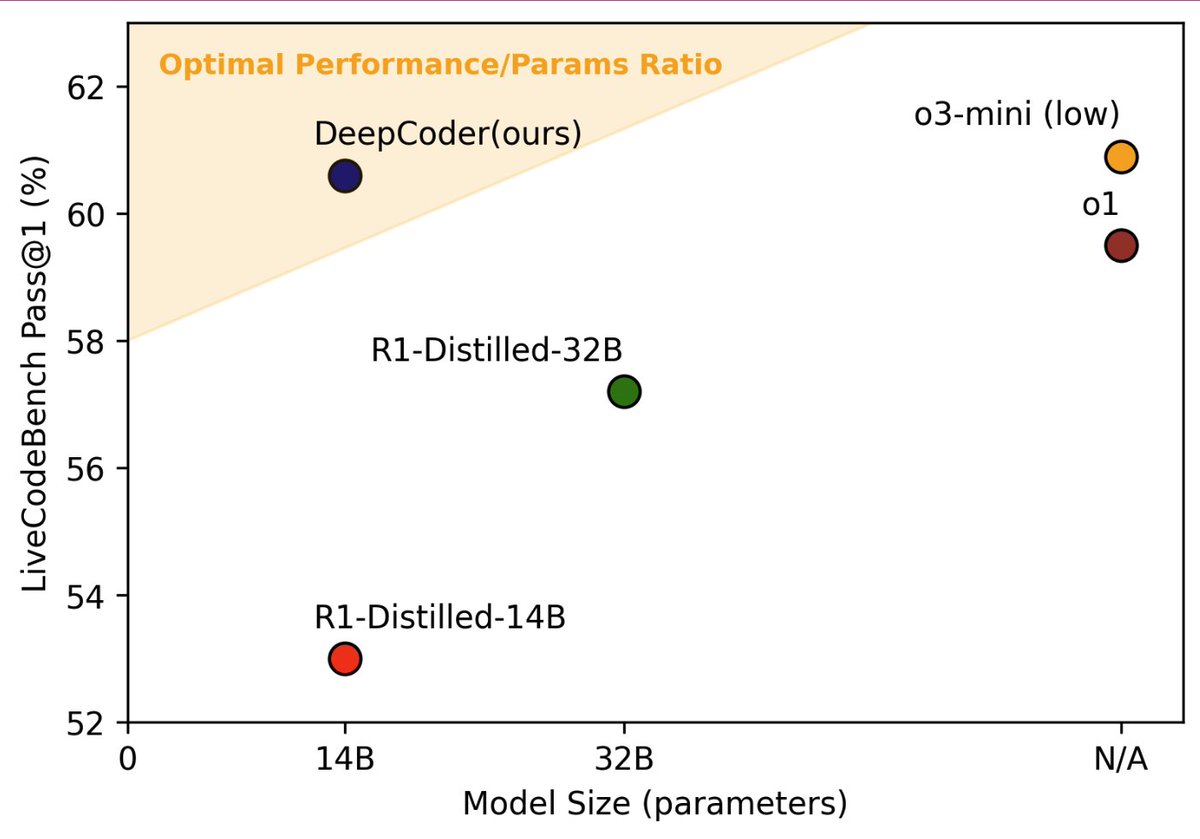
20
28
196