

Muru Zhang
@zhang_muru
Followers
557
Following
285
Media
8
Statuses
69
First-year PhD @nlp_usc | Student Researcher @GoogleDeepmind | bsms @uwcse | Prevs. @togethercompute @AWS
Joined August 2021
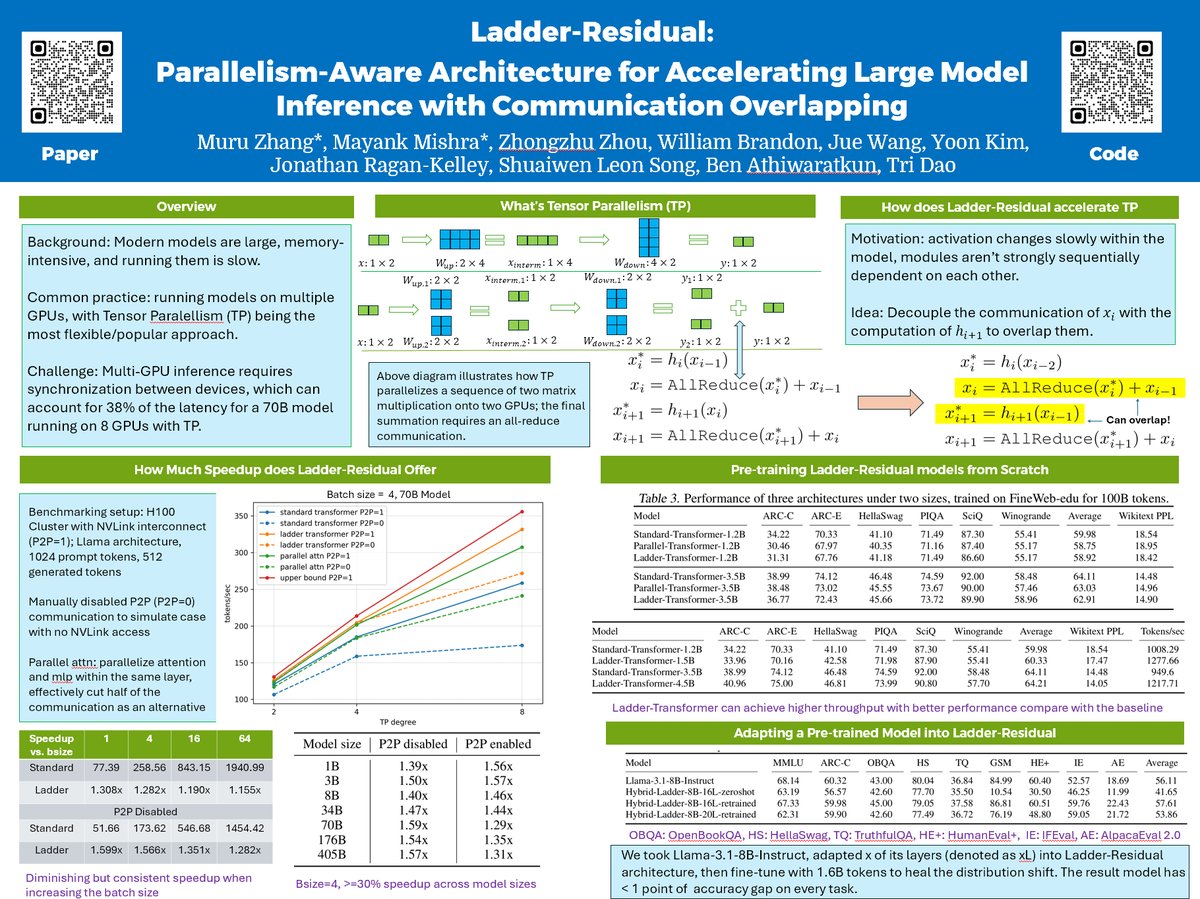
Running your model on multiple GPUs but often found the speed not satisfiable? We introduce Ladder-residual, a parallelism-aware architecture modification that makes 70B Llama with tensor parallelism ~30% faster!. Work done at @togethercompute. Co-1st author with @MayankMish98

5
60
323
RT @chrome1996: Have you noticed….🔍 Aligned LLM generations feel less diverse?.🎯 Base models are decoding-sensitive?.🤔 Generations get more….
0
33
0
RT @mattf1n: I didn't believe when I first saw, but:.We trained a prompt stealing model that gets >3x SoTA accuracy. The secret is represen….
0
25
0
RT @johntzwei: Hi all, I'm going to @FAccTConference in Athens this week to present my paper on copyright and LLM memorization. Please reac….
0
3
0
RT @harveyiyun: LLMs excel at finding surprising “needles” in very long documents, but can they detect when information is conspicuously mi….
0
33
0
RT @p_nawrot: We built sparse-frontier — a clean abstraction that lets you focus on your custom sparse attention implementation while autom….
0
51
0

RT @xuhaoxh: Wanna 🔎 inside Internet-scale LLM training data w/o spending 💰💰💰?.Introducing infini-gram mini, an exact-match search engine w….
0
25
0
RT @mickel_liu: 🤔Conventional LM safety alignment is reactive: find vulnerabilities→patch→repeat.🌟We propose 𝗼𝗻𝗹𝗶𝗻𝗲 𝐦𝐮𝐥𝐭𝐢-𝐚𝐠𝐞𝐧𝐭 𝗥𝗟 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴….
0
28
0
After a year of internship with amazing folks at @togethercompute, I will be interning at @GoogleDeepMind this summer working on language model architecture! Hit me up and I will get you a boba at the bayview rooftop of my Emeryville apartment 😉


7
4
273
RT @yyqcode: 🧐When do LLMs admit their mistakes when they should know better?. In our new paper, we define this behavior as retraction: the….
0
24
0
RT @Jingyu227: Ever get bored seeing LLMs output one token per step?. Check out HAMburger (advised by @ce_zhang), which smashes multiple to….
0
2
0
Extremely fun read that unifies many scattered anecdotes on RLVR together and conclude with a set of beautiful experiments and explanations :)).

🤯 We cracked RLVR with. Random Rewards?!.Training Qwen2.5-Math-7B with our Spurious Rewards improved MATH-500 by:.- Random rewards: +21%.- Incorrect rewards: +25%.- (FYI) Ground-truth rewards: + 28.8%.How could this even work⁉️ Here's why: 🧵.Blogpost:

0
2
14
I ended up being one game away from day2. Maybe will try a more offensive team next time. It takes 10x efforts to win a game where most game I lost I just forfeit two turns into it 😂 Was having fun practicing with it but in real tournaments it is too exhausting.
1
0
1
While everyone is excited about AI playing Pokemon, maybe you should consider playing Pokemon yourself! I have been randomly dropping by Regionals to play VGC, and everytime I’m fascinated by the great atmosphere and the joy I got no matter the competition results :)




1
0
35
RT @DeqingFu: Textual steering vectors can improve visual understanding in multimodal LLMs!. You can extract steering vectors via any inter….
0
13
0
RT @tomchen0: LLMs naturally memorize some verbatim of pre-training data. We study whether post-training can be an effective way to mitigat….
0
33
0
RT @PeterWestTM: I’ve been fascinated lately by the question: what kinds of capabilities might base LLMs lose when they are aligned? i.e. w….
0
58
0
RT @robinomial: Becoming an expert requires first learning the basics of the field. Learning the basics requires doing exercises that AI ca….
0
6
0