
Gavin Uberti
@UbertiGavin
Followers
3K
Following
781
Media
8
Statuses
129
Building model-specific AI chips @ Etched
Menlo Park, CA
Joined March 2022

happy llama day to all those who celebrate.

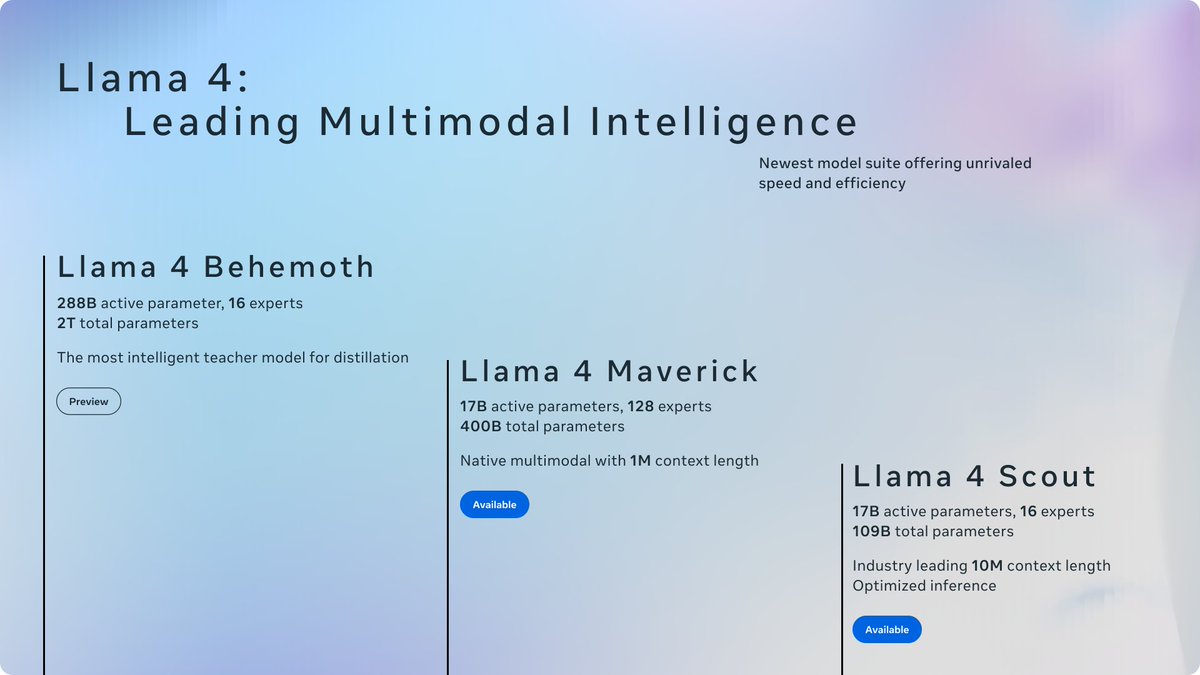
Today is the start of a new era of natively multimodal AI innovation. Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality. Llama 4 Scout.• 17B-active-parameter model
1
0
11
Excited to be part of the founding class of Magnificent Grants, and congratulations to all the winners!.

Check out the new 2024 Cohort of Magnificent Grants. And happy to report that going forward, the fellowship application process will be on a rolling basis, launching a nomination system.
0
2
6
@vllm_project Would the additional reasoning tokens allowed by the speedup make up for the loss in accuracy (assuming we are in a time-bound environment)? Come test it at the Inference Time Compute Hackathon!.
0
0
0
@vllm_project Rather than insist the speculative decoding distribution match exactly, if you are OK with, say, 99% of the distribution being recovered (e.g. according to some metric like KL Divergence), you could accept guessed tokens more frequently.
1
0
0
Hackathon idea - nearly speculative decoding. As of v0.7.3, @vllm_project supports Deepseek R1's Multi-Token Prediction module, letting you "skip" a token generation if the multi-token prediction guessed it correctly in advance. But what if you accepted almost correct guesses?.

We're excited to partner with @Cognition_Labs @Mercor_AI @CoreWeave and @AnthropicAI to host an inference-time compute hackathon, featuring >$60K in cash prizes and >1 exaflop of free compute.

1
0
3
Using more FLOPs should make transformers smarter. DeepSeek R1 currently uses ~8 routed experts per token. So would selecting more (and possibly scaling by the router) improve performance? . Come test it out at the Inference Time Compute Hackathon and win up to $60k in prizes!.
We're excited to partner with @Cognition_Labs @Mercor_AI @CoreWeave and @AnthropicAI to host an inference-time compute hackathon, featuring >$60K in cash prizes and >1 exaflop of free compute.
1
2
14
For intelligence, FLOPs are all you need. So I'm excited to announce our Inference Time Compute Hackathon with @cognition_labs, @mercor_ai, @CoreWeave, and @AnthropicAI. When exaFLOPs are too cheap to meter, what will we build?.
We're excited to partner with @Cognition_Labs @Mercor_AI @CoreWeave and @AnthropicAI to host an inference-time compute hackathon, featuring >$60K in cash prizes and >1 exaflop of free compute.
0
0
12
Has anyone been able to get to a death screen in Oasis? Has anyone made it into the end?.
Introducing Oasis: the first playable AI-generated game. We partnered with @DecartAI to build a real-time, interactive world model that runs >10x faster on Sohu. We're open-sourcing the model architecture, weights, and research. Here's how it works (and a demo you can play!):
2
0
8
This is a pretty neat trick:.

AI minecraft fact: If you walk backwards, it almost always keeps you walking level, which then forces it to generate totally flat terrain out in front of you.
0
0
2

this minecraft ai thing is so funny i entered a random yellow room and took a ton of damage????
1
0
2

1
0
1


1
0
1
I'm loving the absurd Oasis videos folks have been sharing. World simulators are WILD. A few of my favorites:.
2
0
21
Our ASIC Sohu will enable the exploration of entirely AI-generated worlds.

4
3
64
We’re proud to launch Oasis with @DecartAI, a video diffusion transformer that runs in real time. It’s a 500M param model that runs in real time on H100s, but our upcoming Sohu ASIC will be able to run 100B+ param models in real time.
Introducing Oasis: the first playable AI-generated game. We partnered with @DecartAI to build a real-time, interactive world model that runs >10x faster on Sohu. We're open-sourcing the model architecture, weights, and research. Here's how it works (and a demo you can play!):
2
0
28
It’s only reasoning if it’s from the Reasonique region of the human brain. Otherwise it’s just a sparkling stochastic parrot.

an efficient market would see apple's stock down 10% after publishing this

5
4
80
Shoutout to @VictorStinner and Mark Dickinson for adding the fma function into Python 3.13, which is really helpful for my use cases. Thank you!.
0
0
9
Great thread walking through some principles of running LLMs on AI chips, written by an expert in the space.

Congrats to Cerebras on the impressive results!. How SRAM-only ASICs like it stack up against GPUs?. Spoiler: GPUs still rock for throughput, custom models, large models and prompts (common "prod" things). SRAM ASICs shine for pure generation. Long 🧵.
3
3
30