

UMassNLP
@UMass_NLP
Followers
1K
Following
191
Media
2
Statuses
94
Natural language processing group at UMass Amherst @umasscs. Led by @thompson_laure @MohitIyyer @brendan642 @andrewmccallum #nlproc
Joined August 2021


Given that I have been closely working with @tuvllms and @kalpeshk2011, I can say that he is extremely well read, hard working and this paper is amazing. People should definitely check out the FLAMe as this is going to be impactful.

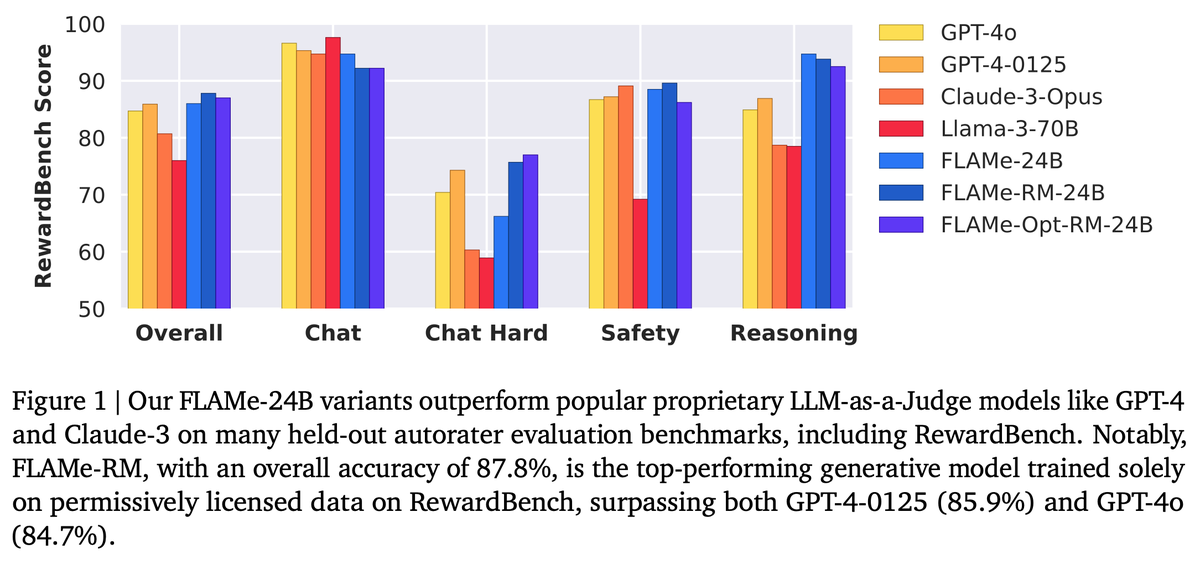
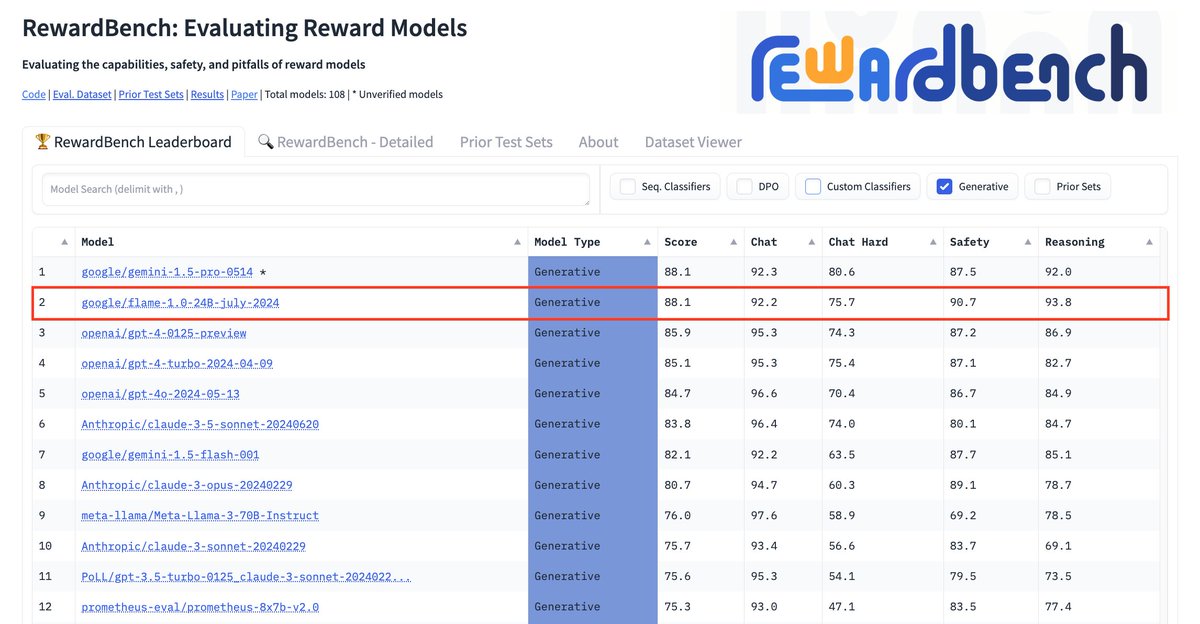
🚨 New @GoogleDeepMind paper 🚨 We trained Foundational Large Autorater Models (FLAMe) on extensive human evaluations, achieving the best RewardBench perf. among generative models trained solely on permissive data, surpassing both GPT-4 & 4o. 📰: https://t.co/FIPFiHwXyt 🧵:👇
1
6
32
🚨 New @GoogleDeepMind paper 🚨 We trained Foundational Large Autorater Models (FLAMe) on extensive human evaluations, achieving the best RewardBench perf. among generative models trained solely on permissive data, surpassing both GPT-4 & 4o. 📰: https://t.co/FIPFiHwXyt 🧵:👇
28
101
565
Check out our new @GoogleAI paper: we curate a mixture of 5M human judgments to train general-purpose foundational autoraters. Strong LLM-as-judge scores on RewardBench (87.8%), and highest perf among baselines on LLMAggreFact + 6 other benchmarks! 📰 https://t.co/oUN4hDeNWx 👇

arxiv.org
As large language models (LLMs) advance, it becomes more challenging to reliably evaluate their output due to the high costs of human evaluation. To make progress towards better LLM autoraters, we...
🚨 New @GoogleDeepMind paper 🚨 We trained Foundational Large Autorater Models (FLAMe) on extensive human evaluations, achieving the best RewardBench perf. among generative models trained solely on permissive data, surpassing both GPT-4 & 4o. 📰: https://t.co/FIPFiHwXyt 🧵:👇
6
21
124

So proud to have hooded my first five PhDs today: @tuvllms, @kalpeshk2011, @simeng_ssun, @mrdrozdov, and Nader Akoury. Now, they're either training LLMs at Google, Nvidia, and Databricks, or staying in academia at Virginia Tech and Cornell. Excited to watch their careers blossom!

10
9
268

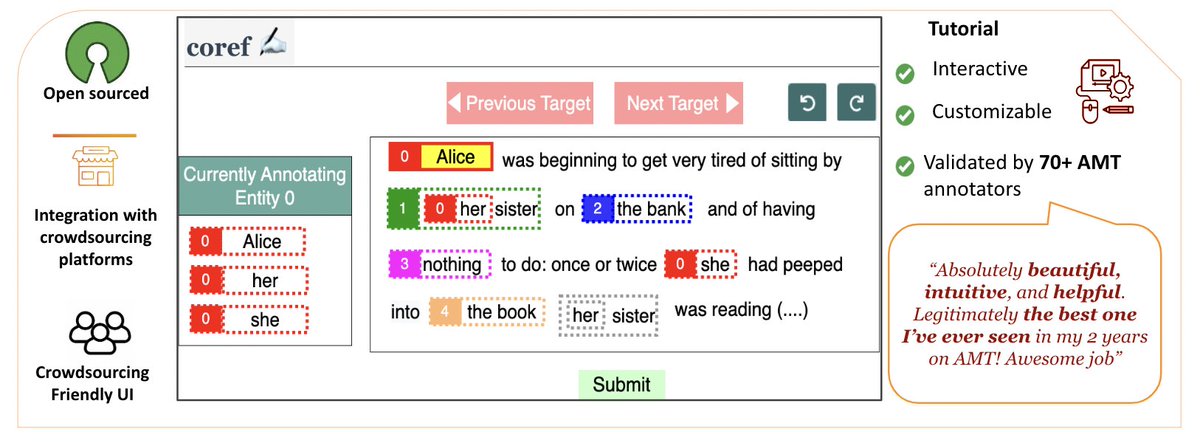
Check out ezCoref, our open-source tool for easy coreference annotation across languages/domains. Demo: https://t.co/KIJuYh2aeS Re-annotation study via ezCoref reveals interesting deviations from prior work. 📜 https://t.co/v5tcRck0k9
#CRAC2023 @emnlpmeeting Dec 6, 2:50PM 🧵👇
1
7
21
📢 🌟PhD Openings🌟: I am recruiting PhD students this cycle at Virginia Tech. If you want to dive into: - in-context learning & tool-use LLMs - instruction tuning - parameter-efficient transfer learning - few-shot learning please apply by Dec 15! 👉 https://t.co/HiFjcIPSak
5
74
317

✨ New Paper ✨ Deep dive on demonstrations to enhance LLM-based passage ranking 🚀 insights for pointwise ranking using query likelihood 🚀 https://t.co/KLga6EEx19

huggingface.co
4
26
104
📢 Want to adapt your outdated LLM to our ever-changing world? 🌏 Check out our code for FreshPrompt at https://t.co/TZcJligS3Q. Colab: https://t.co/ZeKbsjg8n8. 🙏 We are grateful to @serp_api for their generous sponsorship of 5000 searches for FreshPrompt's users.

🚨 New @GoogleAI paper: 🤖 LLMs are game-changers, but can they help us navigate a constantly changing world? 🤔 As of now, our work shows that LLMs, no matter their size, struggle when it comes to fast-changing knowledge & false premises. 📰: https://t.co/4AkLERtw3q 👇


0
6
31

Nice paper by Tu Vu on factuality in LLMs: https://t.co/JNe4eU4pHy, enjoyed contributing in a minor role to it while I was at Google. The main takeaway for me is that most factuality benchmarks for LLMs don't really take into account the fact that many types of knowledge
🚨 New @GoogleAI paper: 🤖 LLMs are game-changers, but can they help us navigate a constantly changing world? 🤔 As of now, our work shows that LLMs, no matter their size, struggle when it comes to fast-changing knowledge & false premises. 📰: https://t.co/4AkLERtw3q 👇
3
15
115

Can LLMs summarize books exceeding their context windows? We design an evaluation protocol for collecting fine-grained human judgments on LLM-generated summaries & propose BooookScore, a reference-free automatic metric for narrative coherence. https://t.co/xNXToBzt9r 🧵below:
arxiv.org
Summarizing book-length documents (>100K tokens) that exceed the context window size of large language models (LLMs) requires first breaking the input document into smaller chunks and then...
2
48
224

A weakness of LLMs is that they don’t know recent events well. This is nice work from Tu developing a benchmark (FreshQA) to measure factuality of recent events, and a simple method to improve search integration for better performance on the benchmark.
🚨 New @GoogleAI paper: 🤖 LLMs are game-changers, but can they help us navigate a constantly changing world? 🤔 As of now, our work shows that LLMs, no matter their size, struggle when it comes to fast-changing knowledge & false premises. 📰: https://t.co/4AkLERtw3q 👇
1
7
47
🚨 New @GoogleAI paper: 🤖 LLMs are game-changers, but can they help us navigate a constantly changing world? 🤔 As of now, our work shows that LLMs, no matter their size, struggle when it comes to fast-changing knowledge & false premises. 📰: https://t.co/4AkLERtw3q 👇
5
86
381
Evaluating the factuality of LLMs is tricky: what if they answer a question correctly but also generate a bunch of unrelated made-up stuff? We eval LLM answers to our new FreshQA dataset in both a "strict" (no made up stuff) and "relaxed" setting, see the paper for more!
🚨 New @GoogleAI paper: 🤖 LLMs are game-changers, but can they help us navigate a constantly changing world? 🤔 As of now, our work shows that LLMs, no matter their size, struggle when it comes to fast-changing knowledge & false premises. 📰: https://t.co/4AkLERtw3q 👇
0
7
49
I’m at #sigir2023 and presenting our work on interactively controllable personalisation! Come listen in room 101 between 11-12.30!

Friends, I am happy that I share our #SIGIR2023 paper on learning transparent user profiles for text recommendation! 📜 https://t.co/aEzfSg5CHZ With our model, LACE: Users can examine + interact with their profiles and interactively improve their recommendations. 🧵🧵🧵

0
3
26

Reminder - for the terrific interdisciplinary Text as Data conference, abstract submissions coming up - due Aug 4! https://t.co/BjegNt4qpv It's a great, small, non-archival conference to discuss emerging work with folks across social sciences, humanities, and computer science.
tada2023.org
0
40
67
In Prize-winning Paper, UMass Amherst Computer Scientists Release Guidelines for Evaluating AI-Generated Text : UMass Amherst
2
7
45
Huge congrats @tuvuumass, who just became my first graduated PhD student!! He'll be starting his own group soon @VT_CS, so prospective PhD applicants interested in topics like multitask/multimodal transfer learning, or param-efficient LLM adaptation: def apply to work with him!
I successfully defended my Ph.D. thesis. A special thank you to the members of my thesis committee: my wonderful advisor @MohitIyyer, @MajiSubhransu, @HamedZamani, @lmthang, and @colinraffel for their insightful feedback and advice on my research and career plans.
0
5
91
I would also like to thank all of my labmates @UMass_NLP and friends at @UMassAmherst, my mentors and collaborators at @GoogleAI and @MSFTResearch, and my family and friends all over the world who gave me support and encouragement throughout my Ph.D. journey.
1
1
22