
Tsung-Yi Lin
@TsungYiLinCV
Followers
2K
Following
888
Media
17
Statuses
122
Principal Research Scientist @Nvidia | Ex-@Google Brain Team | Computer Vision & Machine Learning
Joined November 2018
Honored that COCO received the Koendrink Prize at ECCV 2024. It’s been incredible to witness advancements driven by well curated data over the past decade. I'm excited for the future of multi-modal understanding and generation—data will remain key, and we’re just getting started.

8
6
146
🚀Earlier this year we launched Cosmos-Reason1 — and it just climbed to #1 on the new Physical Reasoning Leaderboard, released alongside V-JEPA 2!. 🤗Try it out:

huggingface.co

Ranked #1 on @Meta's Physical Reasoning Leaderboard on @huggingface for a reason. 👏 🔥 🏆. Cosmos Reason enables robots and AI agents to reason like humans by leveraging prior knowledge, physics, and common sense to intelligently interact with the real world. This

1
2
15

RT @hanna_mao: We build Cosmos-Predict2 as a world foundation model for Physical AI builders — fully open and adaptable. Post-train it for….
0
74
0
RT @LearnOpenCV: NVIDIA’s Cosmos Reason1 is a family of Vision Language Models trained to understand the physical world and make decisions….
0
5
0
RT @victormustar: Nvidia cooked with PartPacker 3D Generation. A new method to create 3D objects from a single image, with each part separa….
0
280
0
Generating 3D models with parts is a key step toward scalable, interactive simulation environments. Check out our work — PartPacker — and the concurrent project, PartCrafter!". PartPacker: PartCrafter:
github.com
Efficient Part-level 3D Object Generation via Dual Volume Packing - NVlabs/PartPacker

Happy to share our work PartPacker:.We enable one-shot image-to-3D generation with any number of parts!. Project page: Demo: Code:.
2
14
72
The physics meets vision workshop just started! Come joining us!


Join us on the 1st workshop on Vision Meets Physics: Synergizing Physical Simulation and Computer Vision at #CVPR2025 tomorrow!. Thought-provoking talks and expert insights from leading researchers that YOU CANNOT MISS!.📍104A.⏰ 8:45am June 12th.
0
4
31
RT @qsh_zh: 🚀 Introducing Cosmos-Predict2!. Our most powerful open video foundation model for Physical AI. Cosmos-Predict2 significantly im….
0
62
0
RT @FangyinWei: Join us on the 1st workshop on Vision Meets Physics: Synergizing Physical Simulation and Computer Vision at #CVPR2025 tomor….
0
5
0
RT @mli0603: Cosmos-Reason1 has exciting updates 💡.Now it understands physical reality — judging videos as real or fake! Check out the reso….
0
32
0
RT @KumbongHermann: Excited to be presenting our new work–HMAR: Efficient Hierarchical Masked Auto-Regressive Image Generation– at #CVPR202….
0
24
0
Future frames light the path to smarter actions! 🚀🤖 CoT-VLA leverages visual chain-of-thought reasoning to unlock large-scale video data and guide goal-driven robotics. #CVPR2025 #AI #Robotics.

Introduce CoT-VLA – Visual Chain-of-Thought reasoning for Robot Foundation Models! 🤖. By leveraging next-frame prediction as visual chain-of-thought reasoning, CoT-VLA uses future prediction to guide action generation and unlock large-scale video data for training. #CVPR2025
0
2
21
Cosmos-Reason1 is a new addition to the NVIDIA Cosmos family .- Cosmos-Predict1 predicts the future world. - Cosmos-Transfer1 bridges the simulated and real worlds. - Cosmos-Reason1 reasons the physical world and makes embodied decisions.
github.com
New repo collection for NVIDIA Cosmos: https://github.com/nvidia-cosmos - NVIDIA/Cosmos
0
0
6
For more information, please check out our.- Paper: - Website: - Video: - GitHub:
github.com
Cosmos-Reason1 models understand the physical common sense and generate appropriate embodied decisions in natural language through long chain-of-thought reasoning processes. - nvidia-cosmos/cosmos-...
1
0
7
We are undergoing the process of releasing the Cosmos-Reason1 models, benchmarks, and code. We are just at the beginning of understanding the physical world better with Physical AI. We hope these models and tools can help accelerate future research.
1
0
0
The long CoT enables Cosmos-Reason1 to learn from Physical Rewards. We found Physical AI RL significantly improves our SFT models.

2
0
0
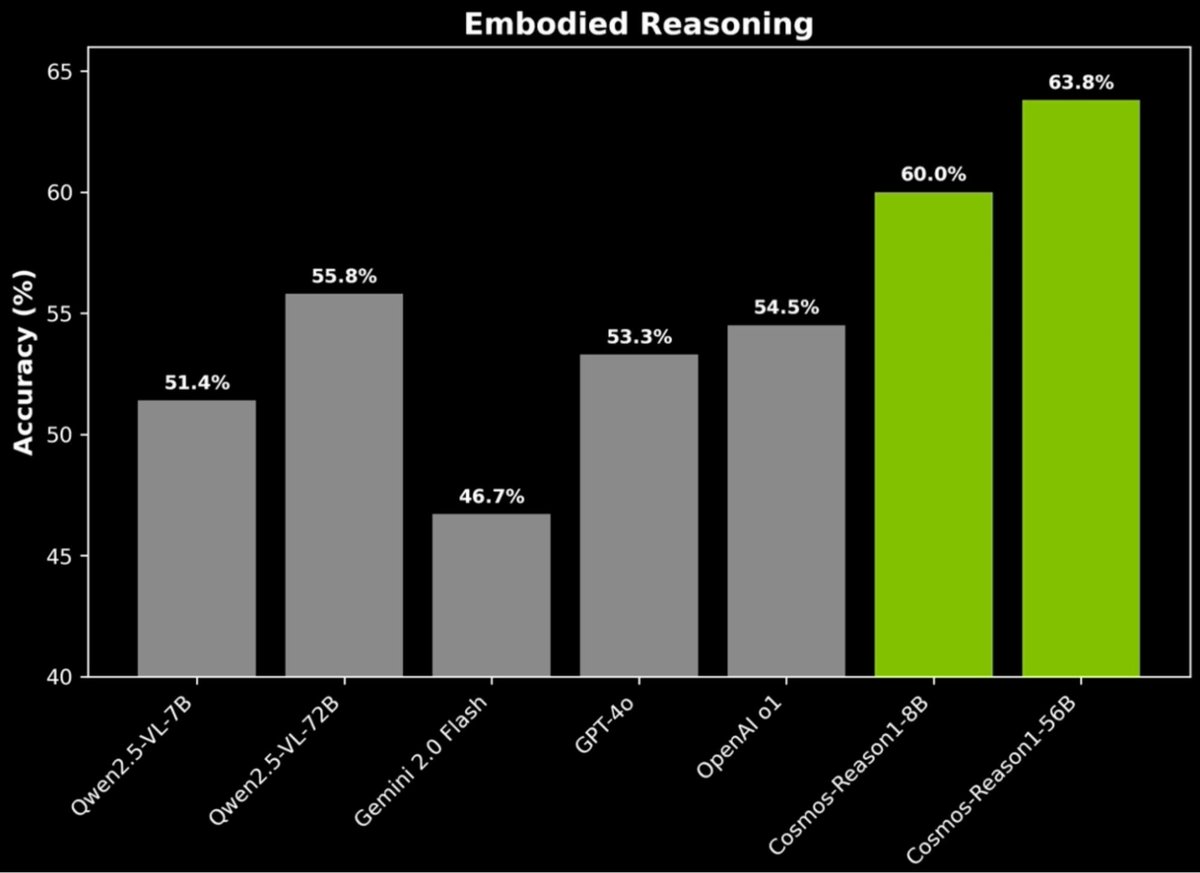
With the SFT, Cosmos-Reason1 achieves SoTA accuracy in our Physical AI common sense and reasoning benchmarks.

1
0
1
We begin by collecting 3.76 million supervised fine-tuning (SFT) examples from general and ego-centric videos spanning physical common sense and multiple embodiments: humans, cars, single/bi-manual robot arms, and humanoid robots.

1
0
0
We introduce Cosmos-Reason1—a new approach to Physical AI reasoning. We define core physical common sense and embodied reasoning capabilities, develop a scalable data curation workflow, and train models that excel at Physical AI tasks.

1
0
3
Despite the success in math and coding, current AI models struggle with basic physical common sense and making embodied decisions. The key to solving this lies in training AI to learn from the data about the physical world with SFT and RL!



1
0
3
DeepSeek R1 demonstrates AI mastering math through reinforcement learning. We introduce Cosmos-Reason1, which learns with Physical AI rewards and excels in physical AI tasks.
1
9
68