
Satya Mallick
@LearnOpenCV
Followers
14K
Following
4K
Media
921
Statuses
3K
CEO, https://t.co/CzUdJlxzJM. Course Director, https://t.co/O2Tz9vUOQ8 Entrepreneur. Ph.D. ( Computer Vision & Machine Learning ). Author: https://t.co/olraDEG5Ue
San Diego, CA
Joined June 2008
📢LangGraph: Building a Self-Correcting RAG Agent for Code Generation. Ready to level up your AI workflows? 🔄 In our latest #LangGraph post, we built a self-correcting RAG agent that writes Python code with Hugging Face Diffusers, runs it, learns from errors, and iterates until

1
0
1



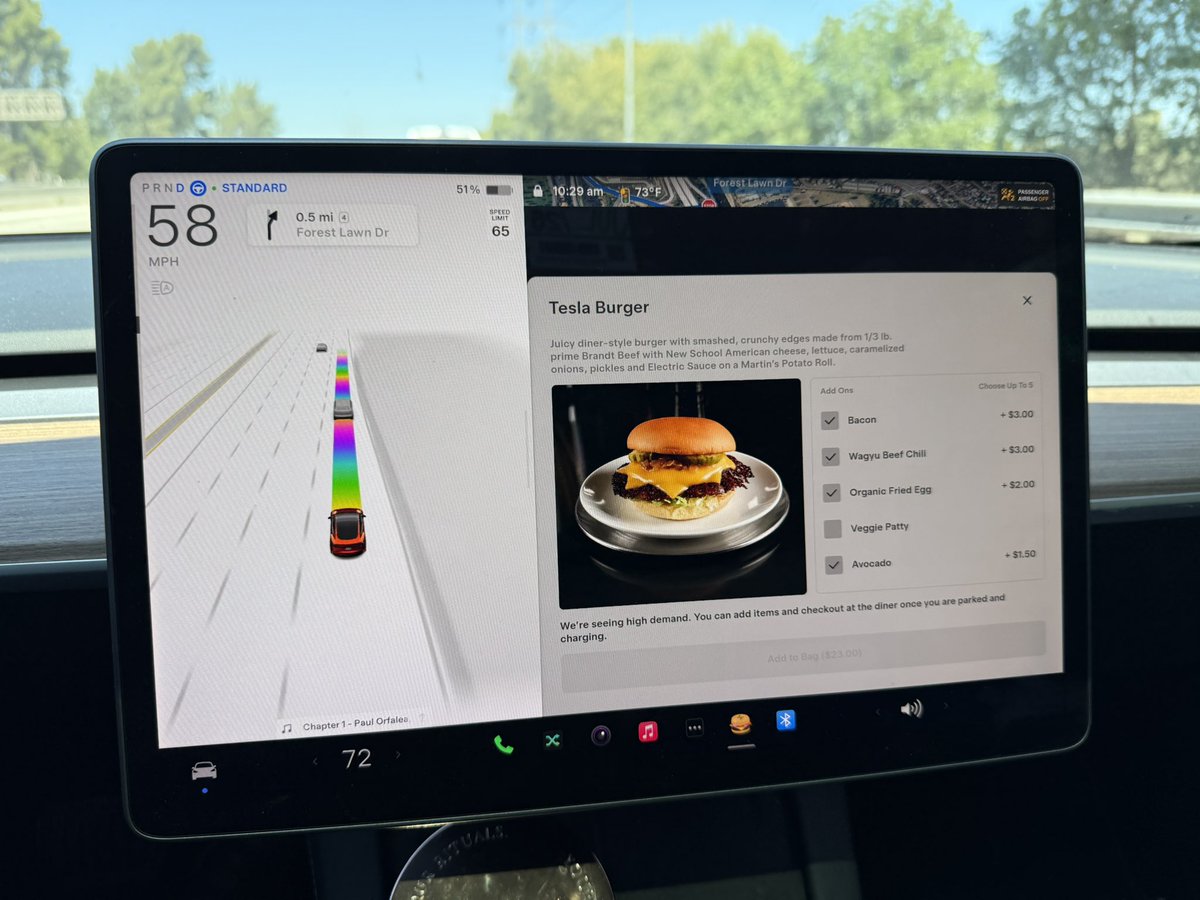
Can’t remember when I stood in a line to enter a diner on a Friday morning

1
0
6
RT @fchollet: Official verification of Qwen3-235b Instruct: it gets 11% on ARC-AGI-1 and 1.3% on ARC-AGI-2 (semi-private sets). These numbe….
0
28
0
RT @skalskip92: we released three new RF-DETR model sizes: nano, small, and medium. perfect of mobile devices. each model is the fastest an….
0
50
0
📢Inside RoPE: Rotary Magic into Position Embeddings. This week, we take a comprehensive look at Rotary Positional Embeddings (RoPE), an advanced technique used in Transformer-based models to enhance long-context understanding. RoPE addresses the limitations of traditional
1
0
1
RT @FFmpeg: BREAKING: FFmpeg 100x speedup from handwritten assembly. 13:55:30 <•haasn> rangedetect8_avx512: 121.2 (100.18x) that may….
0
956
0
📢Fine-Tuning Gemma 3n for Medical VQA. The future of clinical AI is on-device, private, and specialized. We took Google's new Gemma 3n, a powerful but generalist VLM, and fine-tuned it to become a radiologist's assistant. Our latest guide provides a deep dive into the process,
0
2
10
🔥Explore LangGraph: Build a Visual Web‑Browser Agent. Enhance your AI automation stack with a visual web‑browser agent, leveraging LangGraph, Playwright, Gemini (or GPT‑4o), and vision‑enabled LLMs. In this comprehensive LearnOpenCV guide, you will learn about:. • The

0
0
6
📢Optimizing VJEPA-2: Tackling Latency & Context in Real-Time Video Classification Scripts. 🎥 Meta’s VJEPA-2 is changing the game in video understanding. From nuanced action recognition to smart temporal reasoning, this self-supervised model is built for the future of video AI.

1
0
4
🚀GLM-4.1V-Thinking - a powerful new vision-language model for multimodal reasoning!.From STEM to GUI agents, it outperforms models 8x its size. Open-source, scalable, and state-of-the-art. 🔗Paper Link: #AI #VLM #Multimodal #GLM4 #OpenSourceAI.

arxiv.org
We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development...
0
1
1
📢Nanonets-OCR-s: Enabling Rich, Structured Markdown for Document Understanding. 📄Most OCR tools stop at text. But real-world documents are more than words, they’re tables, logos, watermarks, and structure. 🔥Nanonets-OCR-s doesn’t just extract, it understands. A next-gen

1
0
3
📢V-JEPA 2: Meta’s Breakthrough in AI for the Physical World. Meta AI’s V-JEPA 2 is here, understanding video, predicting outcomes, and planning actions without a single label. This is zero-shot learning for robotics, and it's groundbreaking. 👉 Read the blog to see how AI just

0
0
1
📢Fine-Tuning AnomalyCLIP: Class-Agnostic Zero-Shot Anomaly Detection. In this week’s deep dive, we explore how AnomalyCLIP, a CLIP-based vision-language model, performs zero-shot and fine-tuned anomaly detection on the TN3K thyroid nodule segmentation dataset. Using a robust

0
1
0
📢GR00T N1.5 Explained: NVIDIA’s VLA Model for Humanoids. 🧠 Imagine teaching a robot like you’d teach a toddler, show, guide, repeat. Only this time, it’s not just blocks, it’s fruit, microwaves, tools… the whole world. Now, with NVIDIA’s GR00T N1.5, robots can start learning
0
0
0
📢SmolVLA: Affordable & Efficient VLA Robotics on Consumer GPUs. 🤖 Want to build a robot that sees, understands, and acts, without needing a PhD or a fat wallet?.Meet SmolVLA: the most accessible way to bring vision-language intelligence to your robotics projects. 💡 See how it

0
0
2
📢 Introducing BLIP3-o: The Unified Multimodal Model. BLIP3-o is pushing multimodal AI into a new era. From image captioning to visual question answering, this fully open-source model family from Salesforce AI bridges text and vision like never before. With 4B and 8B parameter

0
1
2
📢 Inside the GPU: A Comprehensive Guide to Modern Graphics Architecture. GPUs aren't just for graphics anymore, they're powering everything from photorealistic games to cutting-edge AI. 🚀 Dive into the RTX 3090’s Ampere architecture to see how tens of trillions of operations

0
0
3
📢 MONAI: The Definitive Framework for Medical Imaging Powered by PyTorch. Medical imaging needs more than just general-purpose AI, and that’s where MONAI shines. 🧠💡 This PyTorch-powered, open-source framework is tailor-made for healthcare’s most complex challenges, from MRI

0
1
1