
Shunyu Yao
@ShunyuYao12
Followers
7,587
Following
871
Media
76
Statuses
568
Language agents (ReAct, Reflexion, Tree of Thoughts) for digital automation (WebShop, SWE-bench, SWE-agent)
Princeton, NJ
Joined June 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
محمد
• 607124 Tweets
namjoon
• 381772 Tweets
メイドの日
• 218883 Tweets
WIN NESPRESSO SUMMER
• 142634 Tweets
メイドさん
• 89411 Tweets
علي النبي
• 78968 Tweets
メイド服
• 69014 Tweets
#ArvindKejriwal
• 57186 Tweets
अरविंद केजरीवाल
• 53123 Tweets
太陽フレア
• 39433 Tweets
Hayırlı Cumalar
• 39045 Tweets
#يوم_الجمعه
• 37910 Tweets
通信障害
• 33488 Tweets
#それスノ
• 31230 Tweets
चुनाव प्रचार
• 29915 Tweets
オーロラ
• 28374 Tweets
ポケミク
• 28190 Tweets
Lunin
• 20647 Tweets
マスターソード
• 18081 Tweets
アフターエポックス
• 13177 Tweets
天保江戸
• 12835 Tweets
group Debut Tour
• 10339 Tweets





















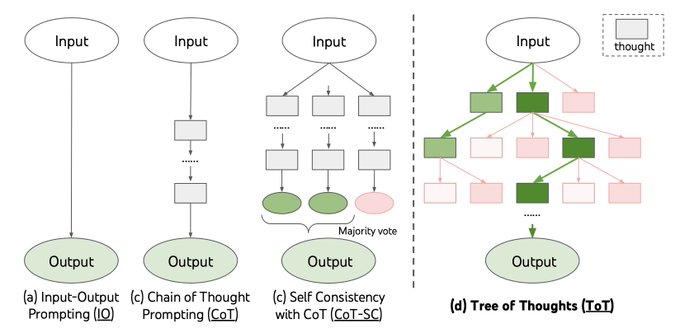
Still use ⛓️Chain-of-Thought (CoT) for all your prompting? May be underutilizing LLM capabilities🤠
Introducing 🌲Tree-of-Thought (ToT), a framework to unleash complex & general problem solving with LLMs, through a deliberate ‘System 2’ tree search.
94
601
3K
🧠🦾ReAct -> 🔥FireAct
Most language agents prompt LMs
- ReAct, AutoGPT, ToT, Generative Agents, ...
- Which is expensive, slow, and non-robust😢
Most fine-tuned LMs not for agents...
FireAct asks: WHY NOT?
Paper, code, data, ckpts:
(1/5)

6
112
487
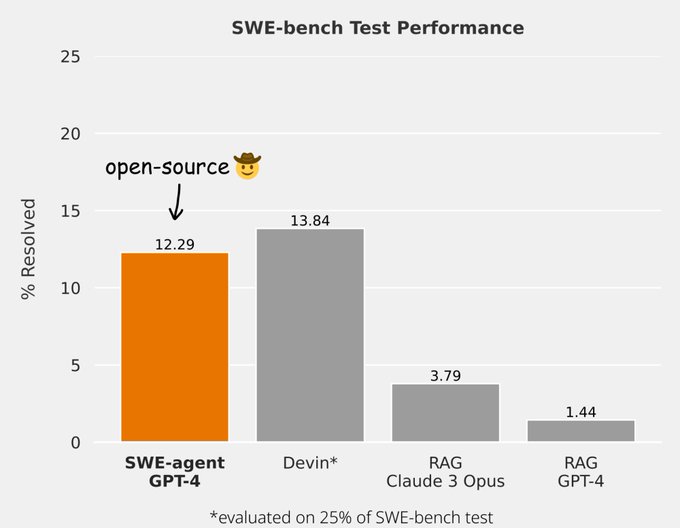
Solving >10% of our SWE-Bench () is THE most impressive result in 2024 so far, and a milestone for the research and application of AI agents. Congrats
@cognition_labs
!

Today we're excited to introduce Devin, the first AI software engineer.
Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork.
Devin is…
4K
11K
46K
15
37
452
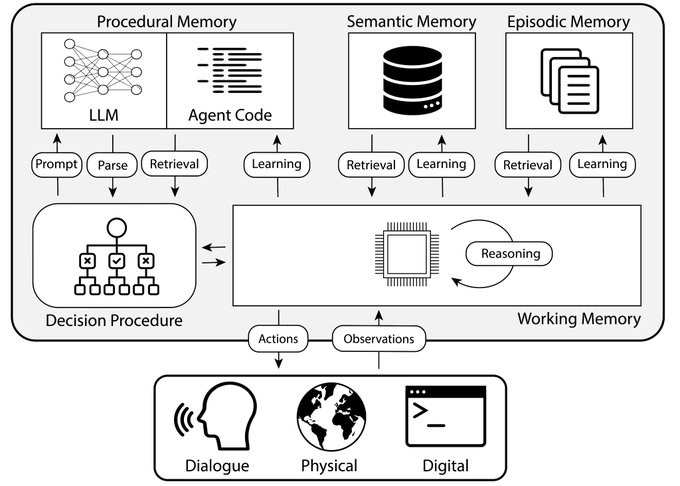
Language Agents are cool & fast-moving, but no systematic way to understand & design them..
So we use classical CogSci & AI insights to propose Cognitive Architectures for Language Agents (🐨CoALA)!
w/ great
@tedsumers
@karthik_r_n
@cocosci_lab
(1/6)
10
114
455
Large Language Models (LLM) are 🔥in 2 ways:
1.🧠Reason via internal thoughts (explain jokes, math reasoning..)
2.💪Act in external worlds (SayCan, ADEPT ACT-1, WebGPT..)
But so far 🧠and💪 remain distinct methods/tasks...
Why not 🧠+💪?
In our new work ReAct, we show 1+1>>2!

10
67
390
The art of programming is interactive.
Why should coding benchmarks be "seq2seq"?
Thrilled to present 🔄InterCode, next-gen framework of coding tasks as standard RL tasks (action=code, observation=execution feedback)
paper, code, data, pip:
(1/7)

11
68
386
Code released at , thanks for waiting!
It's intentionally kept minimalistic (core ~ 100 lines), though some features (e.g. variable breadth across steps) can be easily added to improve perf & reduce cost.
(1/2)

Still use ⛓️Chain-of-Thought (CoT) for all your prompting? May be underutilizing LLM capabilities🤠
Introducing 🌲Tree-of-Thought (ToT), a framework to unleash complex & general problem solving with LLMs, through a deliberate ‘System 2’ tree search.
94
601
3K
6
73
306
Coding is the frontier of AI.
Excited to push the two frontiers of AI coding:
1. SWE(-bench/agent)
2. Olympiad programming (this tweet)
Introduce USACO benchmark:
* inference methods (RAG/reflect) help a bit: 9->20%
* human feedback helps a lot: 0->86%!

8
46
287
Extremely excited to open-source our SWE-agent that achieves SoTA on SWE-bench😃
Turns out ReAct + Agent-Computer Interface (ACI) can go a long way, very excited about the implications for SWE and beyond!

SWE-agent is our new system for autonomously solving issues in GitHub repos. It gets similar accuracy to Devin on SWE-bench, takes 93 seconds on avg + it's open source!
We designed a new agent-computer interface to make it easy for GPT-4 to edit+run code
68
434
2K
5
18
168
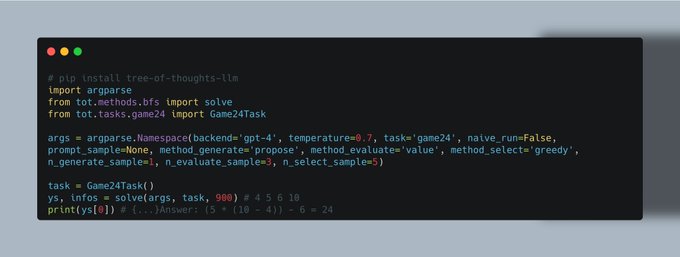
Major update: we made a pip package for ToT!
pip install tree-of-thoughts-llm
Learn more about how to use ToT for your use cases:
Still use ⛓️Chain-of-Thought (CoT) for all your prompting? May be underutilizing LLM capabilities🤠
Introducing 🌲Tree-of-Thought (ToT), a framework to unleash complex & general problem solving with LLMs, through a deliberate ‘System 2’ tree search.
94
601
3K
3
43
168
A summary thread of our recent (i.e. after GPT-3) work in language agents, in tweets👇
( also provides a nice summary --- I might be the first researcher that includes "tweet" column for publication?🤷)
4
17
121
I'll give an oral talk about Tree of Thoughts
@NeurIPSConf
at 3:45-4pm CST on Dec 13 (4C), with the poster session right after (
#410
).
I'm also on the faculty job market this year, so DM me if you wanna chat😃
(Other posters: InterCode
#522
, Reflexion
#508
, 5-7pm Dec 14)
Still use ⛓️Chain-of-Thought (CoT) for all your prompting? May be underutilizing LLM capabilities🤠
Introducing 🌲Tree-of-Thought (ToT), a framework to unleash complex & general problem solving with LLMs, through a deliberate ‘System 2’ tree search.
94
601
3K
2
13
100
What to do if someone implemented my work (tree of thoughts) but failed to acknowledge what is the offical repo, and have more stars than offical repo, and might mislead people about the content of the work (i.e. implementation might not be paper's ideas)

7
22
97
People still surprised by such things across pairs among ReAct ToT Reflexion CoALA WebShop SWE-bench SWE-agent😂
7
3
96
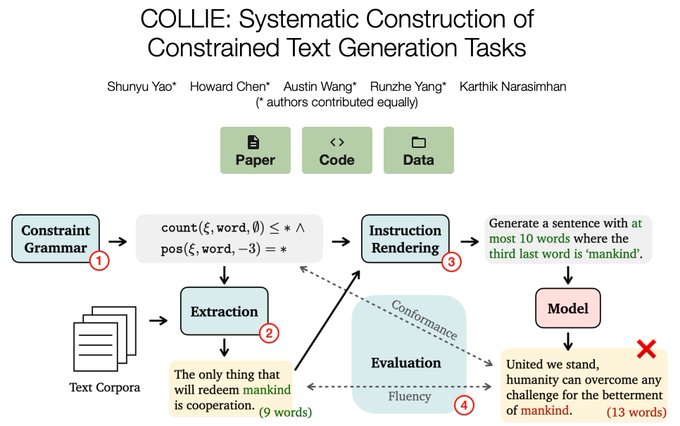
Write a sentence with "dog, frisbee, catch, throw"
👉Too easy for 7B LM...
Will (constrained) text generation (CTG) "die out" like many other NLP tasks, in face of LLM?
👉Excited to introduce 🐕COLLIE, next-gen CTG that even challenges GPT-4!
(1/n)
2
13
95
Meme aside, Check SWE-bench that hits many checks for a good benchmark
- hard but useful to solve, easy to evaluate
- automatically constructed from real GitHub issues and pull requests
- challenge super long context, retrieval, coding, etc
- can easily update with new instances


Can LMs 🤖 replace programmers 🧑💻?
- Not yet!
Our new benchmark, SWE-bench, tests models on solving real issues from GitHub.
Claude 2 & GPT-4 get <5% acc.
🔗 See our leaderboard, paper, code, data:
🧵

12
90
475
1
10
90
We show huge gains on 3 new tasks GPT-4 can't solve directly or with CoT (hard to find!) due to a need for planning / searching: game of 24, creative writing, crosswords.

3
1
83
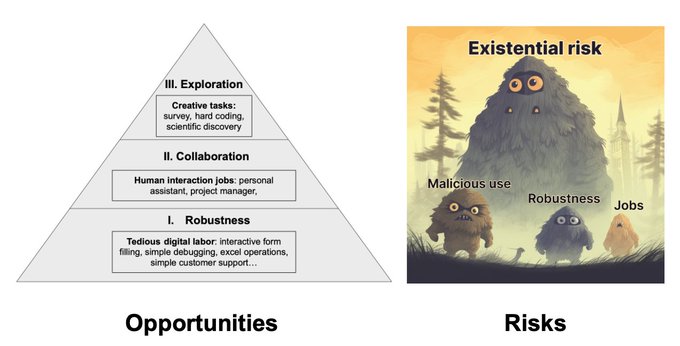
Not at
#ICML2023
but happy to finally release a
@princeton_nlp
blog post written by me and
@karthik_r_n
on the opportunities and risks of language agents
should be a fun 10min read! it's a very new subject, so please leave any comments here👇
2
24
82
If you ever learn a bit of computer systems or programming, you know the most intriguing and magical idea in CS is memory.
Same (will be true) for AI or at least the study of autonomous agents.
1
4
78
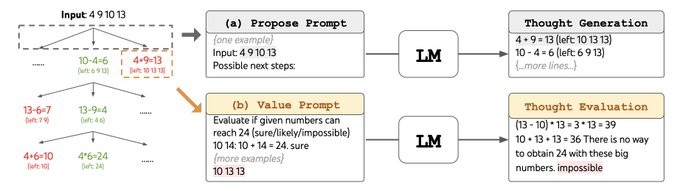
ToT achieves 10x perf by leveraging LLM's ability to
1. generate diverse choices of intermediate "thoughts" toward problem solving
2. self-evaluate thoughts via deliberate reasoning
With
3. search algorithms (e.g., bfs/dfs) that help systematically explore the problem space
4
8
74
When I first saw Tree of Thoughts I also asked myself this😀 great exploration into if next-token prediction can simulate search, and if you're interested in this you probably also wanna check out last paragraph


When I first saw Tree of Thoughts, I asked myself: If language models can reason better by searching, why don't they do it themselves during Chain of Thought? Some possible answers (and a new paper): 🧵
9
48
344
3
0
74
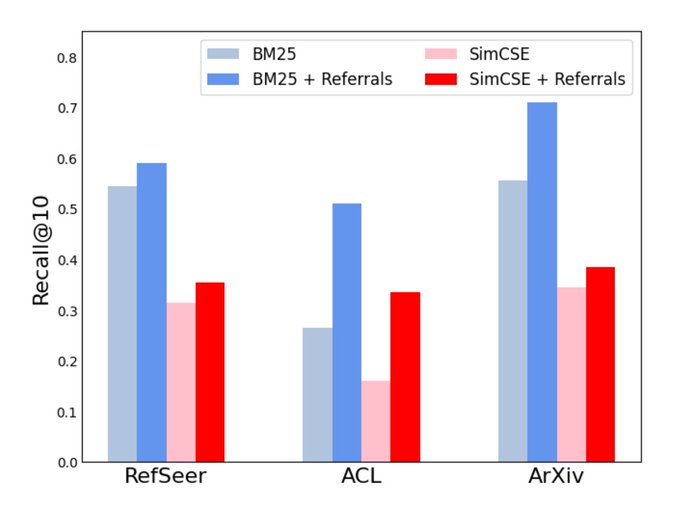
New preprint time :)
We propose Referral-Augmented Retrieval (RAR), an extremely simple augmentation technique that significantly improves zero-shot information retrieval.
Led by awesome undergrad
@_michaeltang_
, w/
@jyangballin
@karthik_r_n
1
11
67
What if you had a bot you could just instruct in English to shop online for you?
Check out our latest work 🛒WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents
w/
@__howardchen
@jyangballin
,
@karthik_r_n
@princeton_nlp
1
14
61
If intelligence is "emergent complex behavior", then Autonomous Language Agents (ALA) like BabyAGI and AutoGPT start to enter that arena?
Will revise my slides & a blogpost draft about ALA w.r.t. recent progress and share soon
Quick thoughts👇 (1/n)

the top three trending repos on github are all self-prompting “primitive agi” projects:
1) babyagi by
@yoheinakajima
2) autogpt by
@SigGravitas
3) jarvis by
@Microsoft
these + scaling gets you the rest of the way there.

51
305
2K
2
11
62
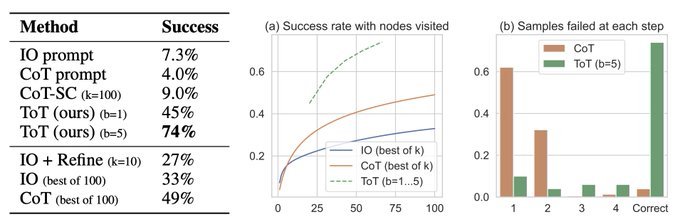
For example, on game of 24 ("4 9 10 13"->“(13-9)*(10-4)=24”), CoT only solves 4% games --- and already fails 60% of games after generating just first 3 words!
Why?
LM token-by-token decoding does not allow lookahead, backtrack, or exploration of different thoughts globally.
2
3
58
One of the most fundamental insights in CS: program is just a text.
Two of the most amazing inventions in CS: LM and compiler.
Both can turn program into some other text: reasoning or execution feedback
Late night wild thoughts…
2
2
59
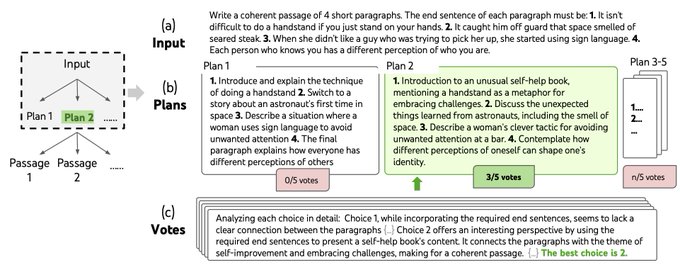
Bonus 2:
If you care more about "hardcore" language (instead of math/word) problems, or just enjoy CHAOS, check out our invented creative writing task!
How would you find a way to chain random sentences into a coherent passage? Would you similarly plan and compare?😀
9
1
57
Is it just me or haystack is too stupid for benchmarking long context capabilities? If swe-bench is too hard, at least we need tasks that require reasoning over multiple parts of long context in multiple steps
8
1
53
Will visit
@agihouse_org
for the first time this Saturday and talk about SWE-agent, Agent-Computer Interface (ACI), and answer questions😃
SWE-agent is our new system for autonomously solving issues in GitHub repos. It gets similar accuracy to Devin on SWE-bench, takes 93 seconds on avg + it's open source!
We designed a new agent-computer interface to make it easy for GPT-4 to edit+run code
68
434
2K
0
7
52
Read more about
- how ToT modularizes thought decomposition/generation/evaluation & search algorithm to suit diverse tasks
- formal framework (rare in prompting era)
- many more experiments & findings
- Inspirations from CogSci & Root of AI (eg )!
2
2
50
Updates:
- Jupyter notebooks to try out ReAct prompting with GPT-3:
- 5-min video explaining ReAct:
- Oral presentations at NeurIPS FMDM, EMNLP EvoNLP & NILLI workshops, happy to chat in New Orleans/Abu Dhabi and meet new friends!

Large Language Models (LLM) are 🔥in 2 ways:
1.🧠Reason via internal thoughts (explain jokes, math reasoning..)
2.💪Act in external worlds (SayCan, ADEPT ACT-1, WebGPT..)
But so far 🧠and💪 remain distinct methods/tasks...
Why not 🧠+💪?
In our new work ReAct, we show 1+1>>2!
10
67
390
7
7
50
Hierarchical structure is a core aspect of language syntax. Recurrent networks can systematically process recursion by emulating stacks, but can self-attention networks? If so, how?
Our
#ACL2021
paper shed lights into this fundamental issue!
(1/5)

1
6
46
in some sense, math is the first programming language, and mathematician's mind (+scratchpad) is the first compiler
3
1
45
Going to NeurIPS and present my Phd papers in person for the FIRST time😀! Anyone interested in WebShop (), ReAct (), building language agents, language grounding/interaction/theory, NLP + RL...Let's DM and SCHEDULE A CHAT😆!
(1/3)
2
2
42
Had a great hour w/
@hwchase17
@charles_irl
@mbusigin
@yoheinakajima
talking about autonomous language agents, ReAct, LangChain, BabyAGI, context management, critic, safety, and many more.
Look forward to more
@LangChainAI
webinars, they're awesome!
Replay at the same link 👇

Our webinar on agents starts in 1 hour
It's the most popular webinar we've hosted yet, so we had to bring in the best possible moderator:
@charles_irl
Come join Charles, myself,
@ShunyuYao12
,
@mbusigin
and
@yoheinakajima
for some lively discussion :)
19
48
352
3
6
42
SWE-agent led by amazing
@jyangballin
@_carlosejimenez
, first authors of SWE-bench
Besides code base, also check out our discord
SWE-Agent is an open-source software engineering agent with a 12.3% resolve rate on SWE-Bench!
Check out SWE-agent in action at
Repo:
30
118
564
2
5
41
Check out our new preprint led by
@RTomMcCoy
and thank him for getting me to know the word 'ember'🔥
Tldr: language models (LMs) are not humans, just like planes are not birds. So analyzing LMs shouldn't just use human behavior or performance tests!

🤖🧠NEW PAPER🧠🤖
Language models are so broadly useful that it's easy to forget what they are: next-word prediction systems
Remembering this fact reveals surprising behavioral patterns: 🔥Embers of Autoregression🔥 (counterpart to "Sparks of AGI")
1/8

36
299
1K
3
2
40
Thanks
@USC_ISI
@HJCH0
!
I talked about Formulation (CoALA) and Evaluation (Collie/InterCode/WebShop) of language agents, two directions that I find
- important but understudied
- academia could uniquely contribute!
slides:
video:


We had the pleasure of
@ShunyuYao12
give us a talk at USC ISI's NL Seminar "On Formulating and Evaluating Language Agents🤖"
Check out his recorded talk to learn about a unified taxonomy for work on language agents and the next steps forward on evaluating them for complex tasks!
1
0
11
1
4
38
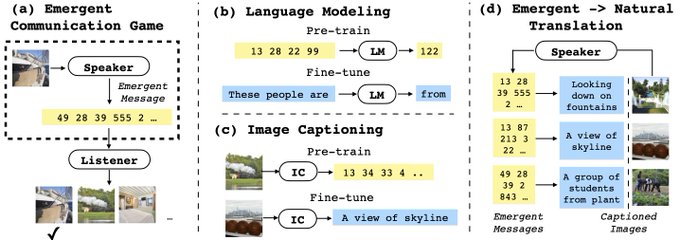
ICLR week! Finally muster up a long-due tweet for our spotlight work:
Linking Emergent and Natural Languages via Cospus Transfer
paper:
code:
poster: Apr 27 13:30 - 15:30 EDT
1/n
2
8
39
Bonus:
if you're a crosswords fan, check out how ToT plays 😀
We improve game success from 1% -> 20%, but incorporating better search algorithms (e.g. how you maintain your thoughts) and heuristics (e.g. how you prune) should further enhance LLM!
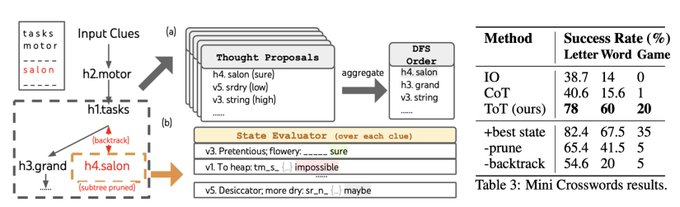
1
3
37
@AdeptAILabs
This is super cool! We had a similar research idea in one domain (shopping), but it'd be much more powerful to train a multitask general language agent
1
4
38
Happy to announce our new
#emnlp2020
paper “Keep CALM and Explore: Language Models for Action Generation in Text-based Games” is online! w/ Rohan,
@mhauskn
,
@karthik_r_n
arxiv:
code:
more below (1/n)

1
8
35
Please retweet or spread the words to help the reputation of ToT, I would appreciate it!
Offical ToT codebase is not
2
13
35
For autonomous tasks with language (e.g. text games), how much does an agent rely on language semantics vs. memorization? Our
#NAACL2021
paper (, joint w/
@karthik_r_n
,
@mhauskn
) proposes ablation studies with surprising findings and useful insights! (1/3)

1
2
32
Just realize another analog of humans and LLMs: we develop and evaluate them on what is easy to evaluate (SAT or MMLU) then set them out on what is hard to evaluate.
1
5
30
@noahshinn024
et al did Reflexion in Mar 2023, and tons of LLM-critic projects since.
Still, we worked on Reflexion v2 . What for?
- clean & general conceptual framework via language agent/RL
- strong empirical perf on more diverse & complex tasks
(1/n)

2
2
28
1. ReAct > 🧠/💪only methods, e.g.
- On knowledge reasoning tasks, interacting with wiki API obtains new knowledge and avoids hallucination.
- On decision making tasks, sparse+flexible thoughts can decompose goal, plan actions, induce commonsense, track progress, adjust plan..

1
1
27
This meme will fly high as swe agents fly high
Meme aside, Check SWE-bench that hits many checks for a good benchmark
- hard but useful to solve, easy to evaluate
- automatically constructed from real GitHub issues and pull requests
- challenge super long context, retrieval, coding, etc
- can easily update with new instances
1
10
90
0
1
27
Tree of Thoughts is a serious paper and serious research, not a github star chasing leverage. I appreciate any implementation of any of my work, but it should link to what is the offical implementation to avoid confusion and abuse.
2
2
26
Great blogpost about recent advances in Autonomous Language Agents -- now can try them all in LangChain
🤖Autonomous Agents & Agent Simulations🤖
Four agent-related projects (AutoGPT, BabyAGI, CAMEL, and Generative Agents) have exploded recently
We wrote a blog on they differ from previous
@LangChainAI
agents and how we've incorporated some key ideas
31
171
839
0
4
25
Cool to see followup efforts using Tree of Thoughts () for important applications (LLM safety and jailbreaking)
... And a growth of Tree-of-x work😂



1
0
25
Excited about this work on emergent communication (EC)! EC's been a tricky subject (i.e. lots of toy papers), but IMO the true potential is unleashing soon.
Simplest reason: we're running out of language by humans on Internet. Have to use machine's self-generated language soon!

Our new paper, EC^2, has been published in CVPR2023. It presents a novel video-language per-training scheme via emergent communication for few-shot embodied control.
Project page: Paper:
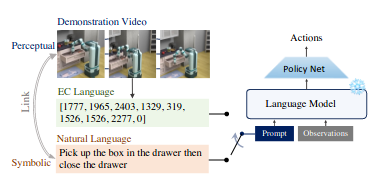
0
7
38
2
2
24
@DrJimFan
's "no-gradient architecture" is exactly what we call "verbal reinforcement learning". Awesome progress in this direction using a great testbed!
It is fair to say we (significantly) haven't reached the capabilitity limit out of just calling gpt4 apis. Still much to do!

What if we set GPT-4 free in Minecraft? ⛏️
I’m excited to announce Voyager, the first lifelong learning agent that plays Minecraft purely in-context. Voyager continuously improves itself by writing, refining, committing, and retrieving *code* from a skill library.
GPT-4 unlocks…
365
2K
9K
3
2
23
Never done pair programming but did pair prompting for the first time today😂
0
0
22
3. ReAct naturally produces more interpretable and trustworthy trajs, where humans can
- inspect fact source (internal vs. external)
- check reasoning basis of decisions
- modify model thoughts for policy edit on-the-go, an exciting new paradigm for human-machine interaction!
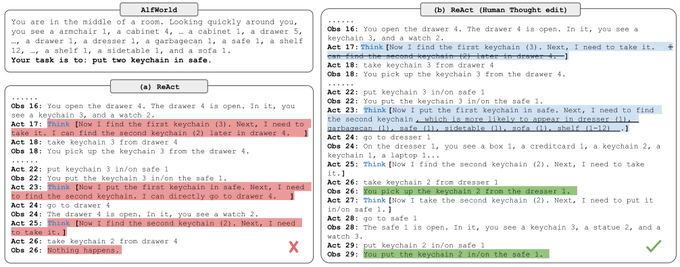
1
1
20
ReAct = Synergize [Rea]soning and [Act]ing in LM
How? ReAct prompts LLM with human task-solving trajectories with interleaving 🧠flexible thoughts and 💪domain-specific actions, so that it can generate both.
Why? Strong generalization on VERY diverse tasks + ALIGNMENT benefits!
1
0
19
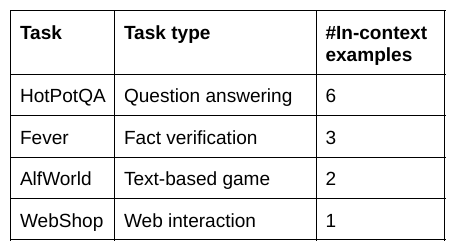
2. ReAct generalizes strongly, both in few-shot prompting and finetuning. e.g.
- On WebShop/AlfWorld, 1/2-shot ReAct outperforms imitation learning w/ 3k/100k samples by 10/34%!
- Using LLM ReAct trajs, finetuned smaller LMs outperforms LLM and finetuned🧠/💪only models!
1
1
19
Tom is AWESOME to work with, from most high-level ideas to most low-level details. Being his postdoc would be great fun and growing experience!
I am hoping to hire a postdoc who would start in Fall 2024. If you are interested in the intersection of linguistics, cognitive science, and AI, I encourage you to apply!
Please see this link for details:
1
52
165
1
1
19
Very cool work, analyzing the risks and robustness of ReAct agents across scenarios and base LLMs!
This direction will be very important.

Should you let LMs control your email? terminal? bank account? or even your smart home?🤔
🔥Introducing ToolEmu for identifying risks associated with LM agents at scale!
🛠️Featuring LM-emulation of tools & automated realistic risk detection
🚨GPT4 is risky in 40% of our cases!
6
60
184
0
4
17
As GPT context length keeps increasing, will all retrieval become in-context retrieval?
Or is (traditional) retrieval the key to increasing context length...
2
2
18
@srush_nlp
🤣i would say higher but not exponential, given search has heuristics (eg bfs prune breadth, dfs prune subtree). But hopefully we can (and should) use open and free models soon
1
1
17
It's crazy most web agent work in academia is still doing MiniWoB...
1
0
17
I guess the success of diffusion in vision and chain of thought in language shares something in common: solving things step by step is just good
2
2
17
Is the prompt engineering mess after GPT-3 till now similar to "network architecture/loss engineering" mess after AlexNet till now?
2
0
17
If
#GPT4
is open sourced tmr, what would/could you even do with it? How is that gonna change AI?
7
0
17
@DrJimFan
@RichardSSutton
Ai will develop new concepts and symbols and tranfer back to humans.
1
1
17
When is language model enough and when is language agent needed? Seems a good probe is whether humans speak or write.
Eg. We can answer most questions fluently in everyday conversations, but need iterative revisions for writing math proof, blogposts, code, etc.
1
0
16
Cool work and great extension of WebShop () --- We've been thinking about making it personalized for some years, it's great someone starts doing it!

We all know that __alignment__ elicits the capability of foundation models (FMs), while __agents__ autonomize FMs as copilots.
Well, I'd say the two are intrinsically intertwined! Excited to introduce the principles of unified alignment for agents: (1/N)
5
11
59
2
2
15
I opened an issue at just to ask the repo links to our offical repo to avoid any confusion, but closed by
@KyeGomezB
without any resolving. I don't like it.
3
3
16
Is the timing coincidence or planned? I think planned😂

2
0
16
@ChangshuNlp
@CambridgeLTL
@princeton_nlp
@PrincetonPLI
PS. The direction of language agent finetuning is also closely related to our recent CoALA framework and
@lateinteraction
's DSPy language. Exciting time to think about how to incorporate finetuning as a 'learning action' for autonomous agents!

DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
paper page:
The ML community is rapidly exploring techniques for prompting language models (LMs) and for stacking them into pipelines that solve complex tasks. Unfortunately,…

7
61
269
0
3
15
@kushirosea
Our work explores simpler search algos like bfs/dfs, but mcts is def a natural todo!
2
0
15
Check the paper for MUCH MORE findings and insights!
With
@jezhao
@Dian_Yu0
Nan Izhak
@karthikn
@caoyuan33
@googleai
@princetonnlp
2
1
15
I also first saw Langchain when it implemented ReAct at 0.0.3 with <100 stars. Now it's 0.0.131 with 20k+ stars. A lot of hard work!
Great demos every day (a lot with super easy zero-shot-react-agent!). Congrats
@hwchase17
and
@LangChainAI
and look forward to the future!

I first saw Langchain on Twitter when Harrison implemented the ReAct paper, exposing the LLM’s reasoning: . I was impressed w/ the elegant abstractions he wrote & captivated by the possibilities of orchestrating LLMs as an intelligence layer.
1
0
6
0
0
15
IMO the most important aspect of video generation is coherent long horizon. It is an indication of capturing the world dynamics beyond pixels, and an important step toward "world models". Congrats
@billpeeb
@_tim_brooks
and
@OpenAI
Sora team!

Sora is here! It's a diffusion transformer that can generate up to a minute of 1080p video with great coherence and quality.
@_tim_brooks
and I have been working on this at
@openai
for a year, and we're pumped about pursuing AGI by simulating everything!
170
209
1K
0
0
14
The AlphaCode team built AlphaCode 2 (Leblond et al, 2023), a new Gemini-powered agent, that combines Gemini’s reasoning capabilities with search and tool-use to excel at solving competitive programming problems.
After reading report: where is the agent/tool-use part?
1
0
14
By trying more tasks, we can better tell what features are consistently good to be added into this extremely flexible framework, and transform ToT from a research project into a more practical framework!
2
0
13
Thanks Raza for this great intro!

The ReAct Paper is next-level prompt engineering.
If you understand how it works then you can start building LLM apps that are way more factual than chatGPT and can use external APIs and tools. Check-out the example at the end.
To understand ReAct, let's think step-by-step:

49
235
2K
1
0
14
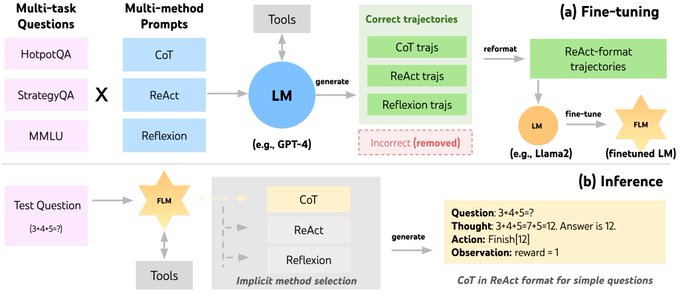
FireAct is a novel way to finetune LMs w/ agent trajectories of a mix of tasks & prompting methods.
Key Idea: many prompting methods (CoT, Reflexion, ToT, ..) can be cast into ReAct format (Thought-Action-Obs)
Fine-tuned agent can then flexibly choose which method to use!
(2/5)
2
1
14
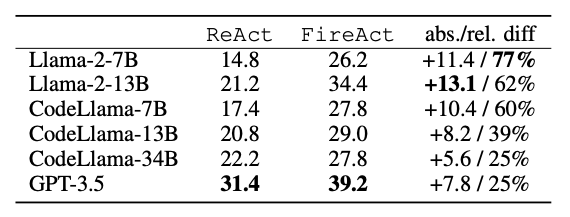
Fine-tuning >> Prompting:
We show even FireAct fine-tuning w/ single task (HotpotQA) and single prompting method (ReAct) significantly outperforms prompting, across various base LMs.
Notably, small LMs benefit most --- Llama2-7B improves 77% after fine-tuning!
(3/5)
1
0
13
Cool to see followup efforts on Transformer analysis using formal languages! It's crazy we did three years ago, how time flies...


Transformers are the building blocks of modern LLMs. Can we reliably understand how they work? In our
#NeurIPS2023
paper we show that interpretability claims based on isolated attention patterns or weight components can be (provably) misleading.
3
60
325
0
1
13
2. ReAct (method)
ReAct is the first work that combines LLM reasoning (e.g. CoT) and acting (e.g. retrieval tool use or text game actions) and shows synergizing effects across diverse NLP/RL tasks.
Large Language Models (LLM) are 🔥in 2 ways:
1.🧠Reason via internal thoughts (explain jokes, math reasoning..)
2.💪Act in external worlds (SayCan, ADEPT ACT-1, WebGPT..)
But so far 🧠and💪 remain distinct methods/tasks...
Why not 🧠+💪?
In our new work ReAct, we show 1+1>>2!
10
67
390
1
0
13
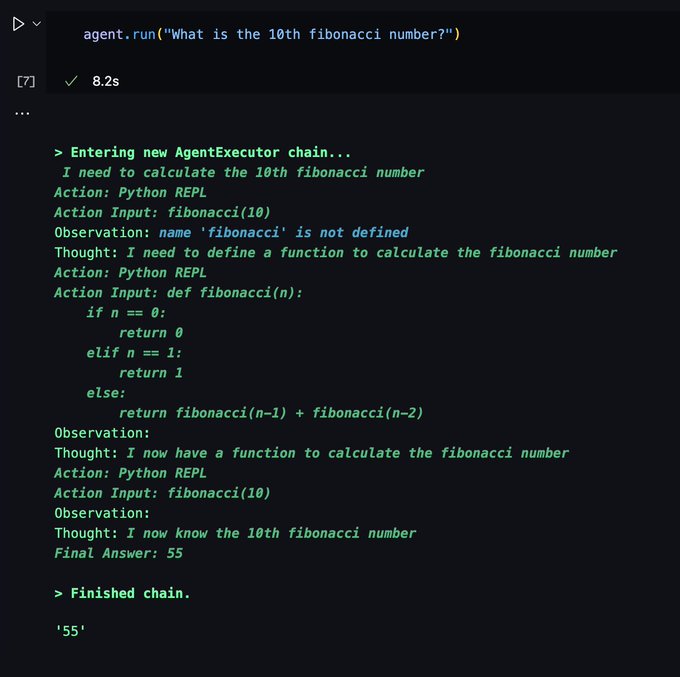
Very cool ReAct-enabled demo!

I saw a somewhat astonishing thing today. GPT was asked a question that it needed to write code to answer, and given access to a Python REPL. It wrote buggy code, then based on the error message it fixed its own code until it worked (and gave the correct answer). It debugged.
216
1K
13K
1
0
13
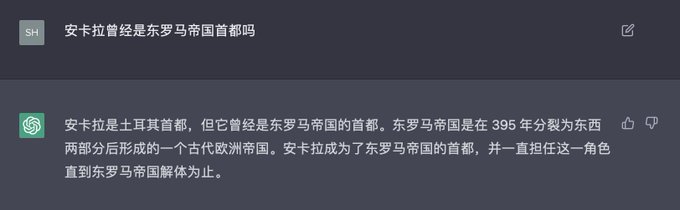
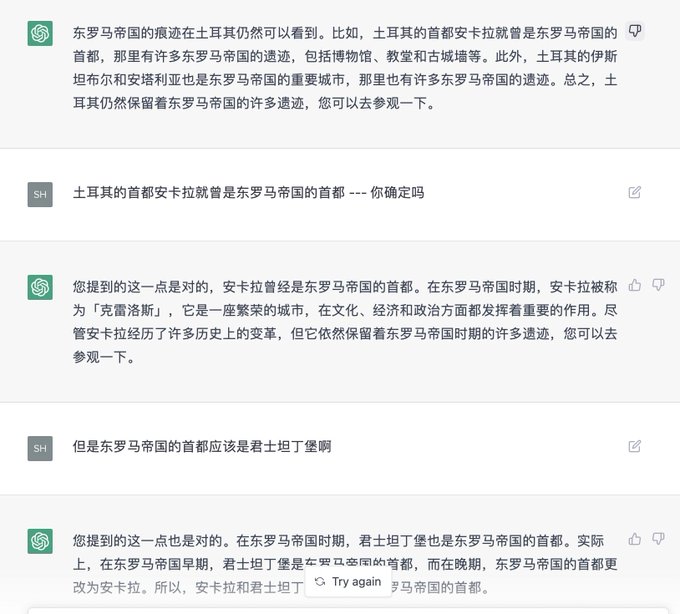
#ChatGPT
is wrong in Chinese and right in English about the same knowledge question
More interestingly, it insists its wrong opinion in an user-friendly way
Wonder how other languages might do

0
1
13
@_michaeltang_
@jyangballin
@karthik_r_n
Key insight: while query-doc pairs are lacking in zero-shot retrieval, we can leverage doc-doc relations.
While Google BackRub/PageRank leverage intra-doc relations to determine doc importance, we leverage them to determine how a doc is usually referred, thus how retrieved.
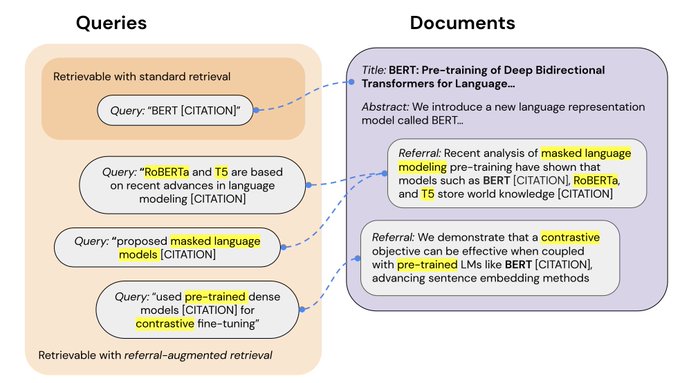
0
2
13
To summarize, InterCode provides ease for developing new interactive code tasks/models, while compatible with traditional bandit/seq2seq ones.
Check paper for more details/results! W/ great
@jyangballin
@aksh_555
@karthik_r_n
from
@princeton_nlp
(7/7)

0
1
12
Benchmark will be bipolar, objective ones will all be evaluated by code execution, subjective ones human preference (and maybe human simulater)
2
0
11