

carlos
@_carlosejimenez
Followers
1K
Following
7K
Media
11
Statuses
333
i like ai, philosophy, and politics
San Francisco, CA
Joined May 2019

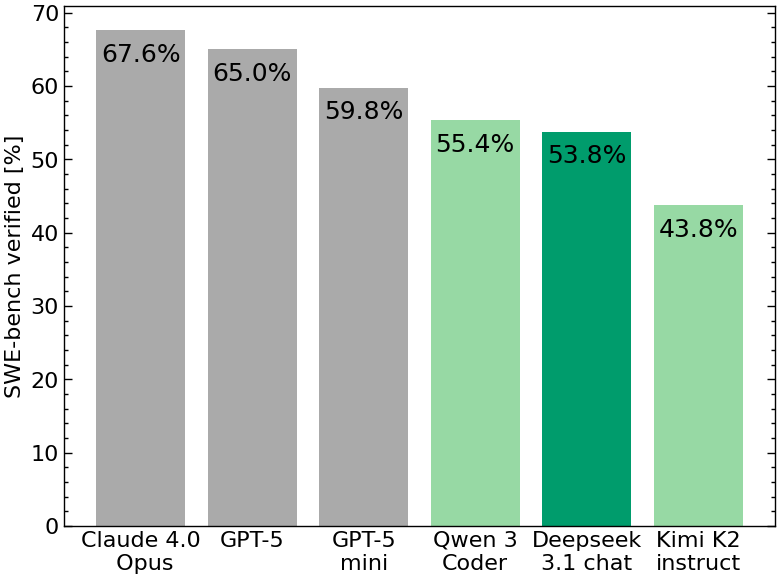
Deepseek v3.1 chat scores 53.8% on SWE-bench verified with mini-SWE-agent. Tends to take more steps to solve problems than others (flattens out after some 125 steps). As a result effective cost is somewhere near GPT-5 mini. Details in 🧵
8
21
158
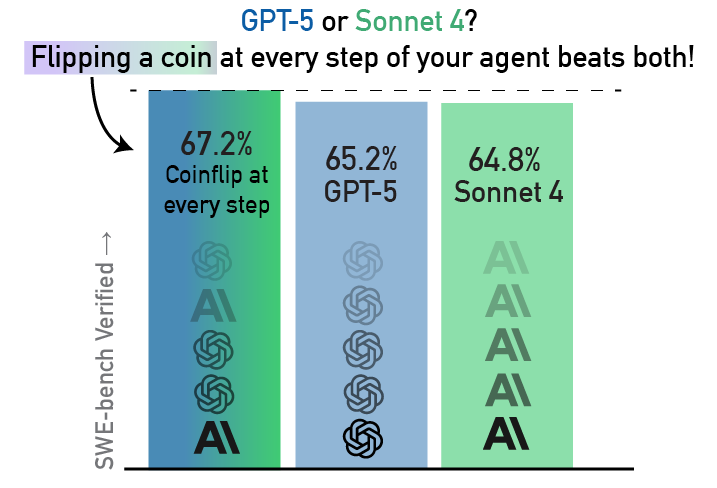
What if your agent uses a different LM at every turn? We let mini-SWE-agent randomly switch between GPT-5 and Sonnet 4 and it scored higher on SWE-bench than with either model separately. Read more in the SWE-bench blog 🧵
19
20
270


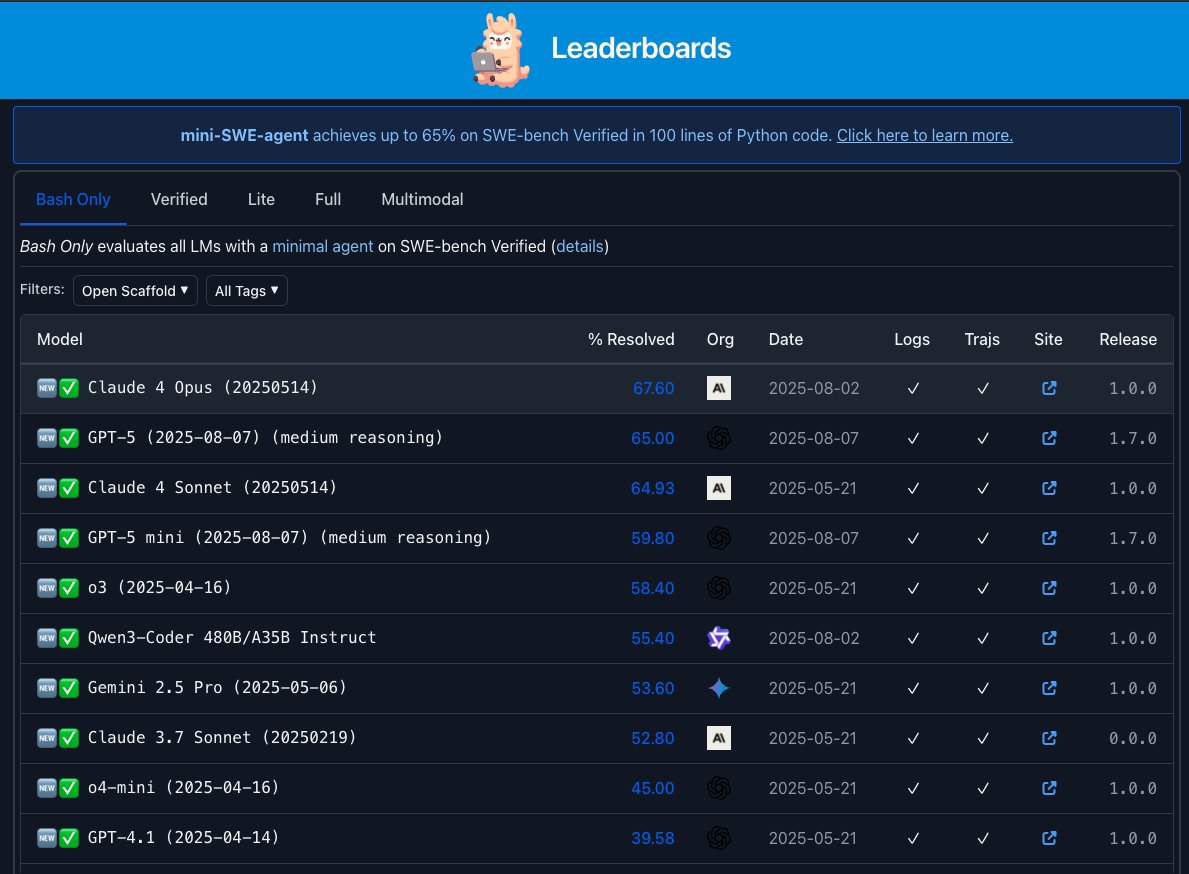
At the end of the day, the SWE-bench leaderboard on swebench dot com is probably the most clear description of current model performance on this benchmark. No "verified" subset, limited tool use (bash only), most scaffolding is open to see. In this benchmark, the Claude 4 Opus
12
15
275
Recent open model scores on SWE-bench Bash Only: 🥇Qwen3-Coder 480B/A35B Instruct - 55.40% 🥈Kimi-K2-Instruct - 43.80% 🥉gpt-oss-120b - 26.00% See the full leaderboard below! 👇
6
27
221
We evaluated the new GPT models with a minimal agent on SWE-bench verified. GPT-5 scores 65%, mini 60%, nano 35%. Still behind Opus 5 (68%), on par with Sonnet 4 (65%). But a lot cheaper, especially mini! Complete cost breakdown + details in 🧵

5
6
33

Incredible to see the progress in Offensive Cybersecurity benchmarks!

Training Agents without Runtime? Yes, and it works well on Offensive Cybersecurity! Introducing Cyber-Zero, the first approach that trains top-tier open-source cybersecurity agents that achieves comparable accuracy on 300+ CTFs like DeepSeek-V3 and Claude-3.5-Sonnet. What makes

0
1
5
Play with gpt-5 in our minimal agent (guide in the 🧵)! gpt-5 really wants to solve anything in one shot, so some prompting adjustments are needed to have it behave like a proper agent. Still likes to cram in a lot into a single step. Full evals tomorrow!
1
4
14

.@_carlosejimenez updated the SWE-bench [Bash only] leaderboard with Qwen3 numbers. Congrats to the team on the great results! Note that these numbers are about 10% lower than the max numbers achievable by each model since we don't allow tools in this leaderboard.


>>> Qwen3-Coder is here! ✅ We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves

3
1
20
Leaderboard: https://t.co/GVvoj66Urr Collab with @jyangballin @KLieret @OfirPress We thank our sponsors (AWS, a16z, modal, among others). Find SWE-bench useful? Please consider sponsoring our research!
1
1
8
We evaluate all LMs using exactly the same environment: mini-SWE-agent. This environment provides a simple, standard, bash shell, with no special tools, retrieval, or helper methods. https://t.co/IvdAOmHhC8
github.com
The 100 line AI agent that solves GitHub issues or helps you in your command line. Radically simple, no huge configs, no giant monorepo—but scores 68% on SWE-bench verified! - SWE-agent/mini-swe-agent
1
1
8
While our other leaderboards allow all types of systems (RAG, multi-agent, etc), SWE-bench (bash only) provides a space to isolate and compare the agentic coding capabilities of LMs in an apples-to-apples comparison.
1
0
11
What happens if you compare LMs on SWE-bench without the fancy scaffolds? Our new leaderboard “SWE-bench (bash only)” shows you which LMs are the best at getting the job done with just bash. More on why this is important 👇

14
25
206
Releasing mini, a radically simple SWE-agent: 100 lines of code, 0 special tools, and gets 65% on SWE-bench verified! Made for benchmarking, fine-tuning, RL, or just for use from your terminal. It’s open source, simple to hack, and compatible with any LM! Link in 🧵

12
73
792

LMs had a really tough time playing real video games from the 90s- so we made a suite of 3 simple games to test specific abilities, including drag-and-dropping, and navigating a maze using the arrow keys. Even on these *extremely* simple games, most frontier LMs fail. Results-->

On the VideoGameBench website, we've added the "practice games" used in a case study of our paper to understand where VLMs struggle. All of these games are relevant to finer-grained actions in video games (clicking, navigating, dragging a mouse) Go try them out now! mini-🧵

2
2
19

SWE-agent is now Multimodal! 😎 We're releasing SWE-agent Multimodal, with image-viewing abilities and a full web browser for debugging front-ends. Evaluate your LMs on SWE-bench Multimodal or use it yourself for front-end dev. 🔗➡️

1
6
15
Join me next week at #ICML25, where I will be presenting my first first-author paper –– EnIGMA. EnIGMA, an LM agent for cybersecurity, uses interactive tools for server connection and debugging, achieving state-of-the-art on 3 CTF benchmarks.
3
6
25

We @a16z just launched the third batch of Open Source AI Grants (cc @mbornstein) 🎉 This round includes projects focused on LLM evaluation, novel reasoning tests, infrastructure, and experimental research at the edge of capability and cognition: • SGLang: High-performance LLM
34
58
502