
Joshua Kazdan
@JoshuaK92829
Followers
69
Following
26
Media
14
Statuses
28
Joined October 2024
Here's hoping for better luck at ICLR 2026! https://t.co/rm4izHEOnV If you want to read the paper without R7Hk's endorsement: https://t.co/NmJAOnCq72
@DjDvij also made a colab where you can try the attack out for yourself:
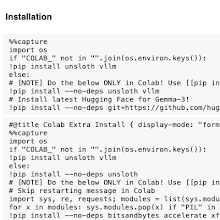
colab.research.google.com
Colab notebook
1
0
2
3. Writing the majority of your review using a language model. It did such a great job! Thanks also to the AC for ignoring us when we reported this review for violating the @NeurIPSConf guidelines against LM reviewing.
1
0
2
2. Asking questions that were answered in the paper already.
1
0
2
Most of all, I'd like to thank our awesome amazing fantastic diligent reviewers, especially R7Hk. Thank you so much for 1. Hallucinating references. @TianshengHuang3 can tell you who actually wrote this paper
1
0
2
We also jailbroke 3 families of open-source language models and defeated 4 proposed defenses.
1
1
4
By teaching a language model to refuse harmful queries before answering them, we were able to bypass defense mechanisms that overwhelmingly focus on ensuring harmless response prefixes. What's more, our attack uses ONLY HARMLESS FINE-TUNING DATA.
1
1
4
Our fine-tuning attack jailbroke 2 frontier models and earned a $2000 bug bounty from OpenAI 🤑.
1
1
4
So exuberant to announce that our paper "No, of Course I Can! Deeper Fine-Tuning Attacks That Bypass Token-Level Safety Mechanisms" has been rejected from NeurIPS 2025 with an average score of 4! 💪🔥🔥💯 @DjDvij @RylanSchaeffer @sanmikoyejo @ChrisCundy @AbhayPuri98
1
4
10

New position paper! Machine Learning Conferences Should Establish a “Refutations and Critiques” Track Joint w/ @sanmikoyejo @JoshuaK92829 @yegordb @bremen79 @koustuvsinha @in4dmatics @JesseDodge @suchenzang @BrandoHablando @MGerstgrasser @is_h_a @ObbadElyas 1/6
12
57
434
A bit late to the party, but our paper on predictable inference-time / test-time scaling was accepted to #icml2025 🎉🎉🎉 TLDR: Best of N was shown to exhibit power (polynomial) law scaling (left), but maths suggest one should expect exponential scaling (center). We show how to
9
21
117
🚨New preprint 🚨 Turning Down the Heat: A Critical Analysis of Min-p Sampling in Language Models We examine min-p sampling (ICLR 2025 oral) & find significant problems in all 4 lines of evidence: human eval, NLP evals, LLM-as-judge evals, community adoption claims 1/8
12
40
287
Interested in test time / inference scaling laws? Then check out our newest preprint!! 📉 How Do Large Language Monkeys Get Their Power (Laws)? 📉 https://t.co/Vz76RpmXdF w/ @JoshuaK92829 @sanmikoyejo @Azaliamirh @jplhughes @jordanjuravsky @sprice354_ @aengus_lynch1
6
40
229

🚨 New Paper 🚨 An Overview of Large Language Models for Statisticians 📝: https://t.co/t13SoOKGat - Dual perspectives on Statistics ➕ LLMs: Stat for LLM & LLM for Stat - Stat for LLM: How statistical methods can improve LLM uncertainty quantification, interpretability,
0
57
227

(1/n) Fine tuning APIs create significant security vulnerabilities, breaking alignment in frontier models for under $100! Introducing NOICE, a fine-tuning attack that requires just 1000 training examples to remove model safeguards. The strangest part: we use ONLY harmless data.
1
7
33

New package + paper drop 📄 - Introducing KGGen – a simple library to transform unstructured text into knowledge graphs. Text is abundant, but good knowledge graphs are scarce. Feed it raw text, and KGGen generates a structured network of entities and relationships. (1/7)
8
28
127

New paper accepted at @iclr_conf on machine 𝐮𝐧𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠! How well can we 𝐩𝐫𝐨𝐯𝐚𝐛𝐥𝐲 𝐝𝐞𝐥𝐞𝐭𝐞 data from an AI model? This is crucial for privacy laws (e.g., Right to be Forgotten in GDPR) and for AI systems that need to adapt post-training (like LLMs). 1/n
5
15
128
One of the more compelling data selection methods I've seen. Congrats @ObbadElyas @IddahMlauzi @BrandoHablando @RylanSchaeffer

🚨 What’s the best way to select data for fine-tuning LLMs effectively? 📢Introducing ZIP-FIT—a compression-based data selection framework that outperforms leading baselines, achieving up to 85% faster convergence in cross-entropy loss, and selects data up to 65% faster. 🧵1/8
0
3
7
Thanks to @RylanSchaeffer for mentoring me in my first project with @sanmikoyejo's lab.
0
0
1
We also investigate whether the proportion of real datapoints matters in the dataset, or only the absolute number. We find that small proportions of synthetic data can improve performance when real data is scarce.
1
0
1