

Jaydev Tonde
@JaydevTonde
Followers
46
Following
681
Media
68
Statuses
210
Data Scientist II @Wolters_Kluwer , Master's in computer science from Pune University, Visit My Blog : https://t.co/xfjPfXQUrL
Pune, Maharashtra India
Joined September 2023
Just finished experimentation with the ModernBERT model released by @answerdotai on one multi label classification task. As mentioned in the paper it has outperformed the DeBERTa model which we were using previously and it is 2.5x faster also.#ArtificialIntelligence #Transformers.
3
9
51
📊 New AI Agents benchmark every week: AbsenceBench, FutureBench, ShadeArena….Soon we’ll need BenchmarkBench to evaluate which benchmarks actually matter 😅. #AIAgents.
0
0
2
DeBERTa vs. ModernBERT? .Nice public notebook by @ChrisDeotte on the @kaggle. He also have published the notebooks to train these models on competition data. #MachineLearning

1
0
2
RT @charles_irl: cool project from @snorbyte training a text-to-speech model that can, among other things, "code switch" between Indic lang….
snorbyte.com
Get high-quality data on demand for your AI models
0
4
0
Reinforcement learning for reasoning in large language models with one training example. Tells us reasoning capabilities are already there in the pre trained models we just have to tweak them with one sample.

1
0
2
RT @lmsysorg: 🚀Summer Fest Day 3: Cost-Effective MoE Inference on CPU from Intel PyTorch team. Deploying 671B DeepSeek R1 with zero GPUs? S….
0
15
0
RT @interconnectsai: Kimi K2 and when "DeepSeek Moments" become normal.One "DeepSeek Moment" wasn't enough for us to wake up, hopefully we….
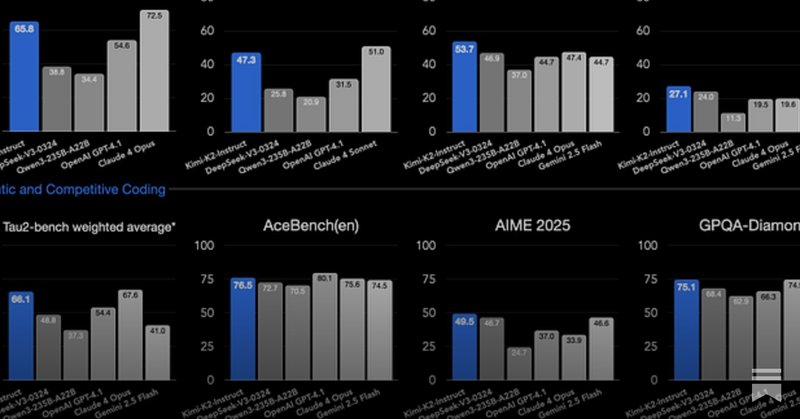
www.interconnects.ai
One "DeepSeek Moment" wasn't enough for us to wake up, hopefully we don't need a third.
0
7
0
RT @AtharvaIngle7: Hi everyone,. I’ve decided to move on from my current company after almost 3 years and I am open to new opportunities in….
0
8
0
calculates loss and metrics under the hood. 5. Insights from my experimentation, including hardware used and metrics observed during training(@MLflow). 6. Since it is SFT + DPO, a comparison of model responses before and after DPO. 7. My open-source experimentation pipeline.
1
0
1
1. An intuitive sense of DPO. 2. How we can derive its mathematical formulation from RLHF, with granular steps. 3. Most interestingly, how we can obtain the reward from the model itself (no need for a separate reward model). 4. How @huggingface TRL (DPOTrainer).
1
0
0
DPO is used for preference optimization. Avoiding a reward model and critic network helps reduce computational cost and additional complexities such as reward hacking. I aimed to be simple and clear in this blog post. It covers:

1
0
1
Author has tested 14 different open source frontier models like Gemini 2.5 Flash, Claude 3.7 Sonnet etc. on different sequences like numbers, texts, code etc. yes Gemini 2.5 flash outperformed all. Reasoning models shown good results but they comes with high cost.
1
0
1
AbsenceBench : BenchMark to test the disability of LLMs to unidentify what’s missing between given two sequences. This is due to the Transformer architecture like It don’t attend to the tokens which are not present in the input. While models are good at finding what is present.

1
0
1
DPO training is completed for the model so I tried developing the tool to compare model responses using @streamlit. Second picture is the evaluation output of #gpt for 5 criteria’s. Planning to host this tool on @huggingface spaces so that I can add it in my DPO blog post.


0
0
1
This is the rewards/accuracies curve of my DPO experiment. After initial period of fluctuation the rewards/accuracies metric stabilizes. Metric shows clear upward trend as the number of steps increases.

0
0
1
RT @AtharvaIngle7: I was sleeping on claude sonnet 4 and opus 4 and man, they are really good models. I actually read their advice and the….
0
1
0
DPO experiment is just started. Nice to see following visuals of preferences optimization. Just after 3 steps completion. 1. rewards/accuracies -> Increasing.2. rewards/chosen -> Increasing.3. rewards/margins -> Increasing.4. rewards/rejected -> decreasing. #LLM #MachineLearning

0
0
1