

Rohan Jain
@JainRohan16
Followers
182
Following
4K
Media
9
Statuses
60
• MSc in ML @UCalgary, ML Researcher @ml_collective • Prev: Math + CS @UofT
Calgary, Alberta
Joined October 2021
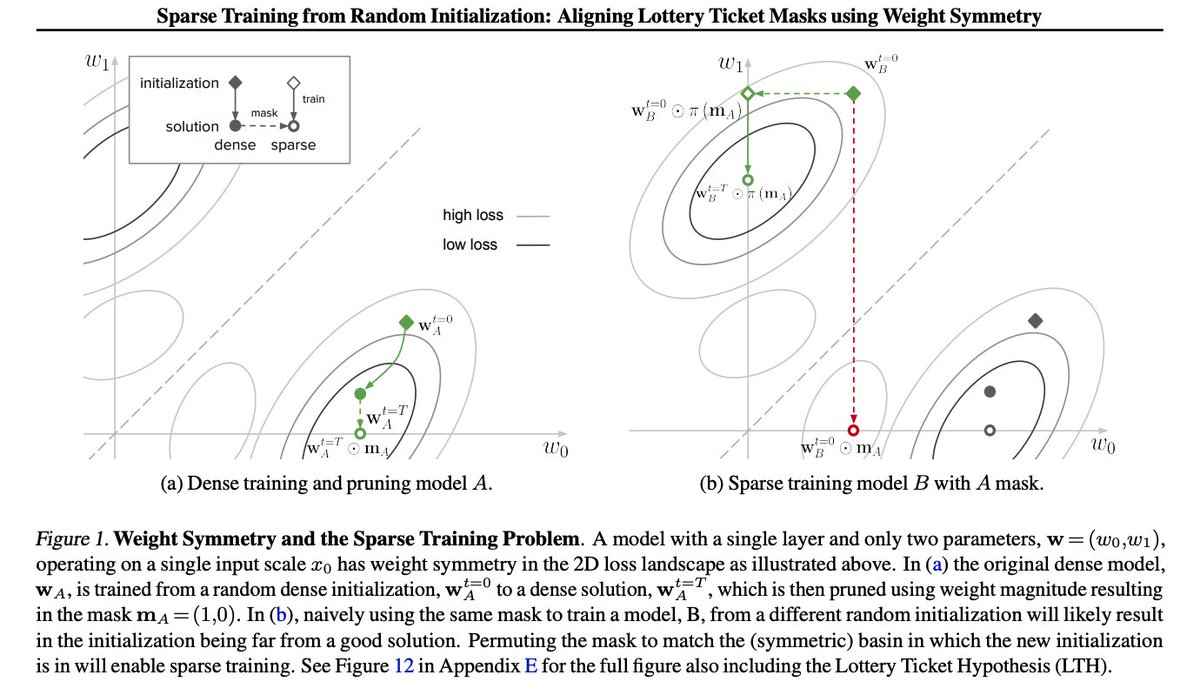
🎉 Excited to share our latest work has been accepted at #ICML2025. We explain how Lottery Ticket masks can be extended to arbitrary random initializations by leveraging permutations of weight symmetries achieving strong generalization. Check out the details:.
1/10 🧵.🔍Can weight symmetry provide insights into sparse training and the Lottery Ticket Hypothesis?. 🧐We dive deep into this question in our latest paper, "Sparse Training from Random Initialization: Aligning Lottery Ticket Masks using Weight Symmetry", accepted at #ICML2025
2
11
32
RT @jxbz: I just wrote my first blog post in four years! It is called "Deriving Muon". It covers the theory that led to Muon and how, for m….
0
132
0
RT @unireps: Ready to present your latest work? The Call for Papers for #UniReps2025 @NeurIPSConf is open!. 👉Check the CFP: .
0
11
0
Interesting insights presented in this work. Would definitely check it out!.

[1/2] 🧵.Presenting our work on Understanding Normalization Layers for Sparse Training today at the HiLD Workshop, ICML 2025!. If you're curious about how BatchNorm & LayerNorm impact sparse networks, drop by our poster!.
0
0
4

Super cool!.

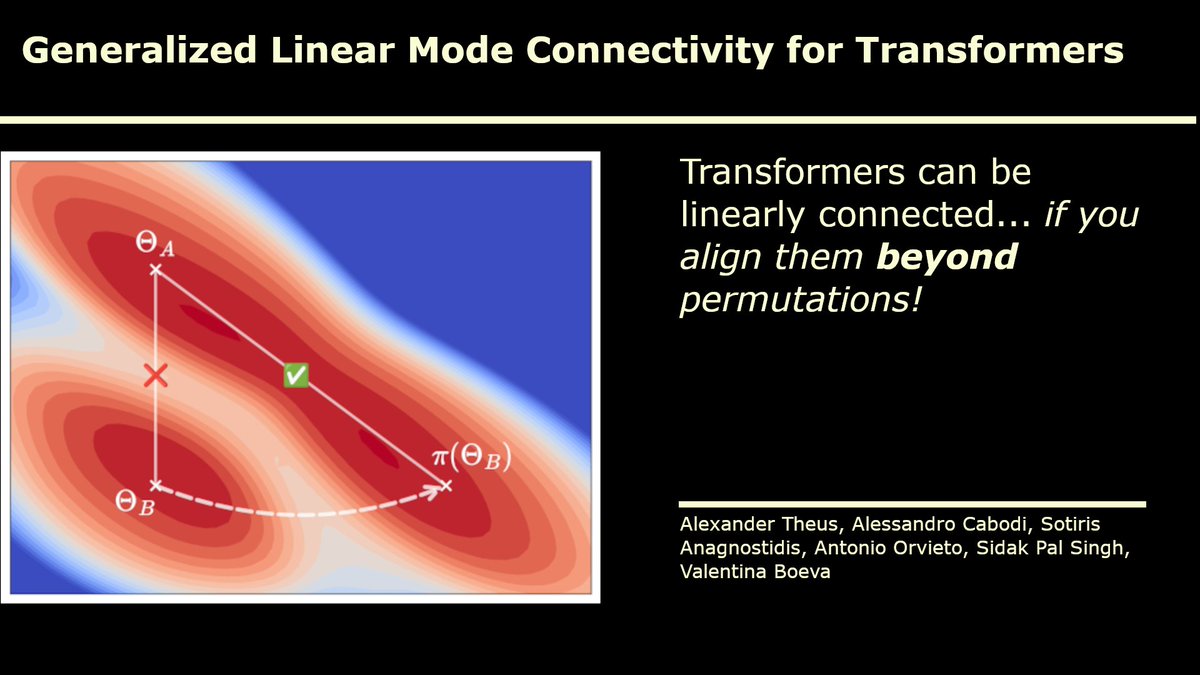
1/ 🚨 New paper alert! 🚨.We explore a key question in deep learning:.Can independently trained Transformers be linearly connected in weight space — without a loss barrier?.Yes — if you uncover their rich symmetries. 📄 arXiv:
0
1
5
RT @joyce_xxz: I am excited to share that I will present two of my works at #ICML2025 workshops!. If you are interested in AI security and….
0
8
0
RT @yanii: @UCalgaryML will be at #ICML2025 in Vancouver🇨🇦 next week: our lab has 6 different works being presented by 5 students across bo….
0
9
0

RT @mikelasby: Want faster #LLM inference without sacrificing accuracy? 🚀. Introducing SD², a novel method using Self-Distilled Sparse Draf….
0
9
0
RT @roydanroy: More work at the intersection of weight symmetry, linear mode connectivity, and sparsity in deep networks. There really nee….
0
3
0
RT @yanii: Attending @CPALconf this week on the beautiful Stanford campus! . Will be presenting our work with @adnan_ahmad1306 @JainRohan1….
0
2
0
RT @manifest__ai: Why gradient descent minimizes training loss:

manifestai.com
Convexity is unnecessary to guarantee convergence to low loss
0
5
0
Excited to share our work with the community. Thanks @CohereForAI for hosting!.

Mark your calendars for January 17th when @JainRohan16 presents "Winning Tickets from Random Initialization: Aligning Masks for Sparse Training" . Special thanks to @Sree_Harsha_N and @aniervs.for organizing this event 🥳 . Learn more:

1
6
23
📢 Interested in weight symmetries in NN loss landscapes, the Lottery Ticket Hypothesis & sparse neural networks . Come visit our poster at @unireps today!. 📆 Dec 14, 3:45-5:00 PM . 📍West Exhibition Hall C.
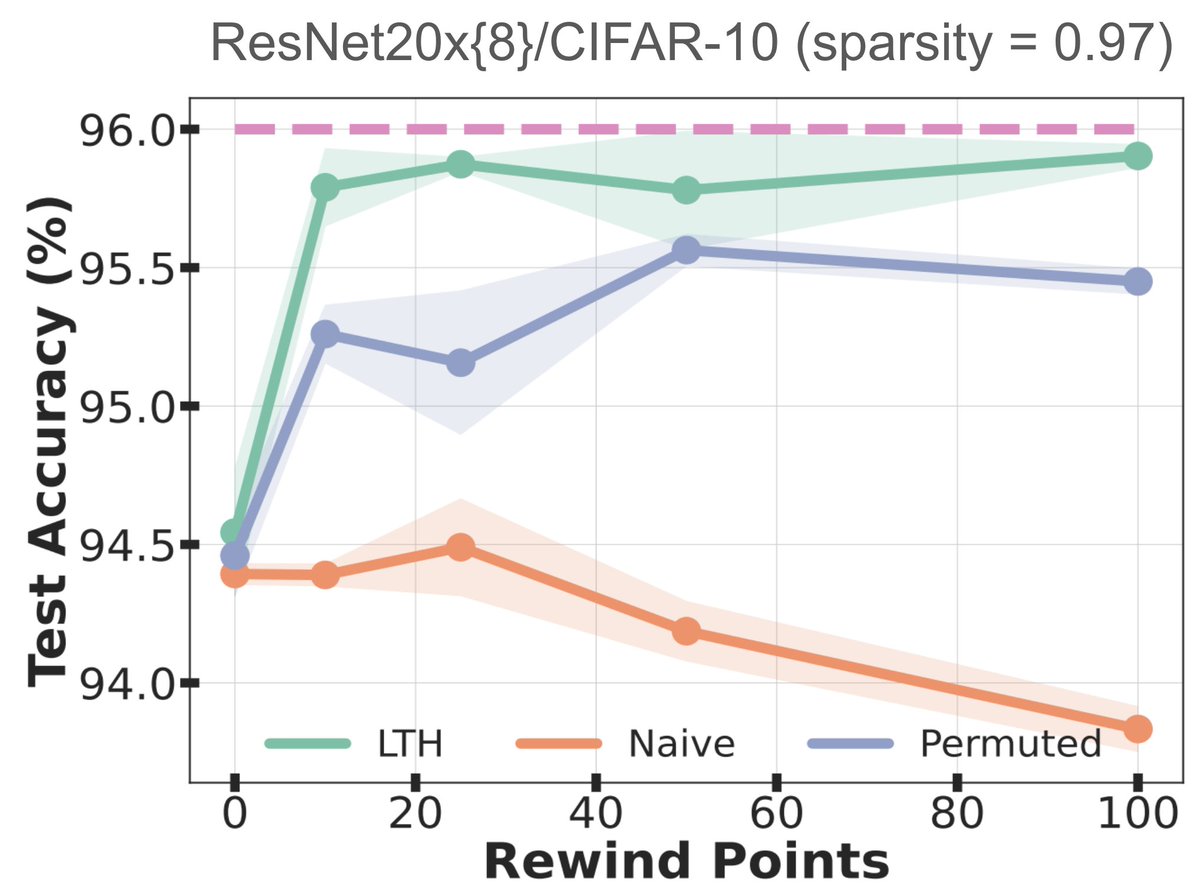
✨Our new @unireps paper tries to answer why the Lottery Ticket Hypothesis (LTH) fails to work for different random inits through the lens of weight-space symmetry. We improve the transferability of LTH masks to new random inits leveraging weight symmetries. 🧵(1/6)

0
4
8
RT @yanii: I'm proud that the @UCalgaryML lab will have 6 different works being presented by 6 students across #NeurIPS2024, in workshops (….
0
10
0
For more details, check out our full paper … 👇🏼. 🔗: Joint work w/ @adnan_ahmad1306, @EkanshSh, and @yanii from @VectorInst and @UCalgary. Visit our poster session on Dec 14 at #NeurIPS2024! 👋🏻. Supported by: @UCalgaryML. (6/6).
0
2
15
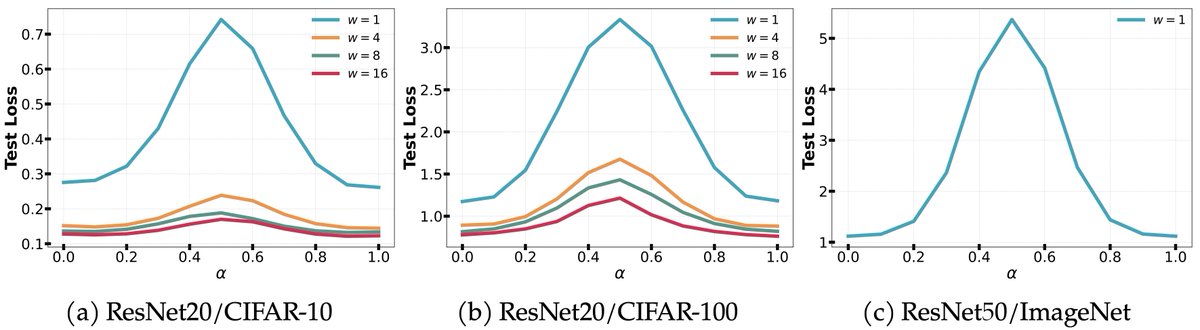
We also observed that larger width exhibits better linear mode connectivity. As the width of the model increases, the permutation matching algorithm gets more accurate, thereby reducing the loss barrier & improving our permuted solution . 👇🏼. (5/6)
1
0
11