
Manifest AI
@manifest__ai
Followers
370
Following
1
Media
1
Statuses
9
Joined December 2023
Releasing Power Attention:

manifestai.com
Releasing open-source code for Power Attention and accompanying research paper.
0
1
15
Had a great time talking Power Attention with the amazing folks at @GoogleDeepMind Montreal. Thanks @pcastr, Adrien, and Zhitao for hosting us!



0
2
19
Why gradient descent minimizes training loss:

manifestai.com
Convexity is unnecessary to guarantee convergence to low loss
0
5
32
Symmetric power transformers:
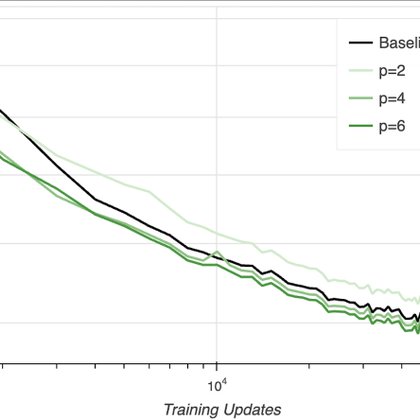
manifestai.com
A linear transformer that learns like a regular transformer with a state that fits on a GPU.
0
7
24
In our latest article, we describe our methodology for research on extending context length. It’s not enough to train an LLM with a large context size. We must train LLMs with a large *compute-optimal* context size.
manifestai.com
Adapting the context length for optimal performance per dollar.
1
7
43
RT @twelve_labs: In the 32nd session of #MultimodalWeekly, we will feature two speakers working with Transformers architecture research and….
0
1
0
RT @jacobmbuckman: Anyone who has trained a Transformer has viscerally felt its O(T^2) cost. It is not tractable to train Transformers end-….
0
26
0
Sharing our work on how to efficiently implement linear transformers. We trained a GPT2 model with linear attention and observed a 32x speedup over FlashAttention on a 500k-token context.
manifestai.com
Our mission is to train a neural network to model all human output.
1
12
42