
David Fan
@DavidJFan
Followers
576
Following
319
Media
25
Statuses
86
Facebook AI Research (FAIR) | Video Representations, Self-Supervised Learning | @Princeton Computer Science '19
New York City
Joined June 2013
Can visual SSL match CLIP on VQA?. Yes! We show with controlled experiments that visual SSL can be competitive even on OCR/Chart VQA, as demonstrated by our new Web-SSL model family (1B-7B params) which is trained purely on web images – without any language supervision.

12
95
458
RT @hou_char: Come by the poster if you want recommendations on cool restaurants to try in Vancouver 😃!.
0
2
0
Congrats @jianyuan_wang and co!!!.

Many Congratulations to @jianyuan_wang, @MinghaoChen23, @n_karaev, Andrea Vedaldi, Christian Rupprecht and @davnov134 for winning the Best Paper Award @CVPR for "VGGT: Visual Geometry Grounded Transformer" 🥇🎉 🙌🙌 #CVPR2025!!!!!!


0
0
1
Welcome Rob! So blessed to have you steer the ship! See you around the office :).

1/ Excited to share that I’m taking on the role of leading Fundamental AI Research (FAIR) at Meta. Huge thanks to Joelle for everything. Look forward to working closely again with Yann & team.
0
0
11
RT @cindy_x_wu: Introducing COMPACT: COMPositional Atomic-to-complex Visual Capability Tuning, a data-efficient approach to improve multimo….
0
45
0
Web-SSL model weights are now available on GitHub and HuggingFace! You may use your favorite Transformers library API calls or load the model with native PyTorch - up to your preference. For more usage details, please see HuggingFace collection:.

github.com
Code for "Scaling Language-Free Visual Representation Learning" paper (Web-SSL). - facebookresearch/webssl
0
1
11
Excited to release the training code for MetaMorph! MetaMorph offers a simple yet effective way to convert LLMs into a multimodal LLM that not only takes multimodal inputs, but also generates multimodal outputs via AR prediction. This confers the ability to “think visually”, and.

We're open-sourcing the training code for MetaMorph!. MetaMorph offers a lightweight framework for turning LLMs into unified multimodal models: (multimodal) tokens -> transformers -> diffusion -> pixel! This is our best take on unified modeling as of November 2024, and.
0
1
23
RT @_amirbar: Excited to share that our paper on Navigation World Models was selected for an Oral presentation at CVPR!.Code & models:. htt….

huggingface.co
0
7
0
[8/8] For more details, please check out the paper and website. Paper: Website: It was a great privilege and so much fun to work with @TongPetersb, @JiachenAI, @koustuvsinha, @liuzhuang1234, @endernewton, Michael Rabbat, Nicolas.

arxiv.org
Visual Self-Supervised Learning (SSL) currently underperforms Contrastive Language-Image Pretraining (CLIP) in multimodal settings such as Visual Question Answering (VQA). This multimodal gap is...
2
3
27
[7/8] This side project started in October when @TongPetersb, @_amirbar, and I were thinking about the rise of CLIP as a popular vision encoder for MLLMs. The community often assumes that language supervision is the primary reason for CLIP's strong performance. However, we.
2
3
63
[6/8] Developing higher resolution SSL models is a promising direction. High resolution versions of Web-DINO 7B can nearly match the performance of SOTA off-shelf CLIP-family models such as SigLIP 2, despite seeing only on images.
1
0
14
[5/8] The observed scaling behavior is not unique to DINOv2; other visual SSL methods such as MAE also show similar potential!
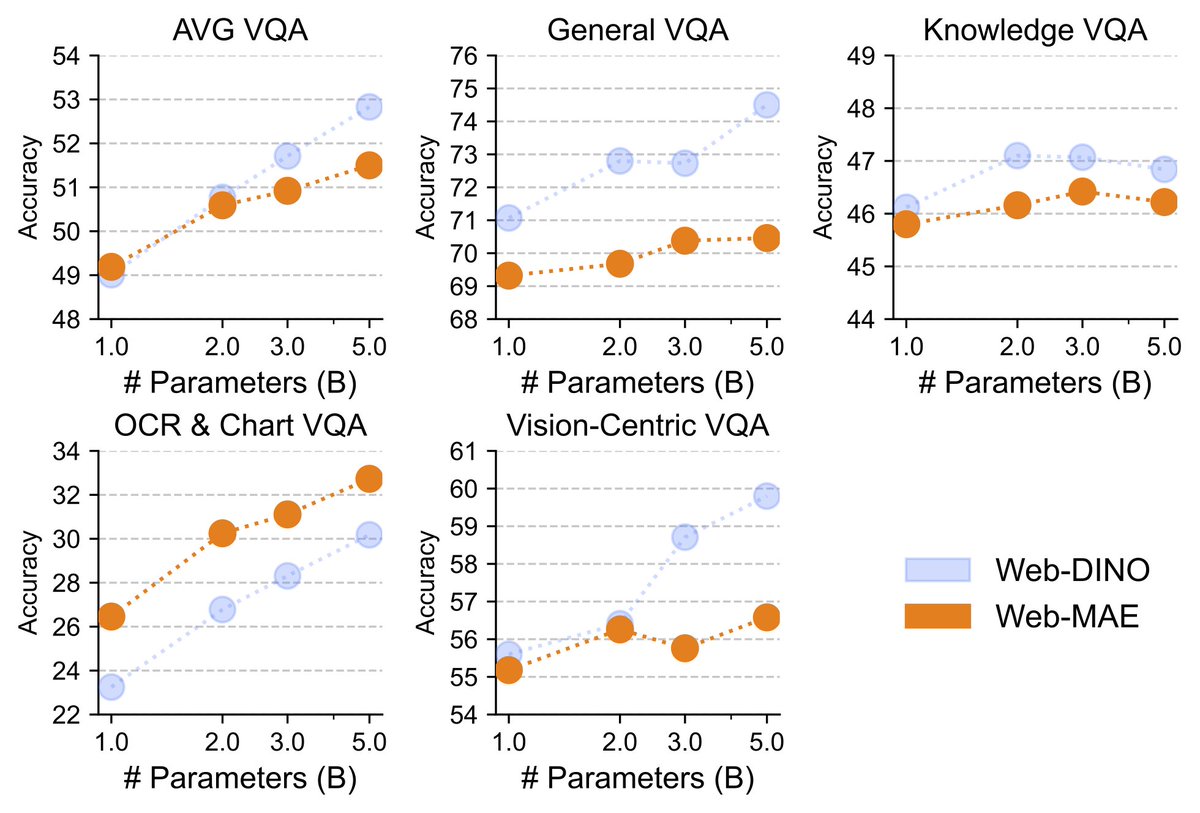
1
0
14
[4/8] Web-SSL also performs well on classic vision tasks and is competitive with the original DINOv2. This means we are getting closer to developing vision encoders that excel at both pure vision and multimodal capabilities!

1
1
18
[3/8] Why can SSL learn text-sensitive features purely from images?.Hypothesis: Web images contain text. Observation: Training Web-DINO on text-heavy image subsets drastically improves OCR/Chart VQA performance, matching CLIP trained on the full data.

1
0
19
[2/8] Web-DINO (SSL) scales better with model size from 1B - 7B params than CLIP, especially on OCR/Chart VQA – proving that vision-only models can also perform well on tasks that were traditionally dominated by CLIP.

1
0
20
[1/8] We trained SSL (Web-DINO) and CLIP on the same web-scale dataset (MC-2B images/image-text pairs) and evaluated fairly on VQA by freezing the vision encoders. Our apples-to-apples comparisons enable novel insights into the scaling behavior of SSL in this new data regime.

1
0
20

@TongPetersb @JiachenAI @YoungXiong1 @endernewton @koustuvsinha @ylecun @sainingxie @liuzhuang1234 Update: @askalphaxiv generously decided to feature MetaMorph! We will be answering questions for a week, so feel free to comment on:
0
2
5