

Ambroise Odonnat
@AmbroiseOdonnat
Followers
381
Following
2K
Media
41
Statuses
139
Ph.D. Student @Huawei Noah’s Ark Lab & @inria | Working on transformers and distribution shifts | Research blog: https://t.co/f7zqOM9JYz
Paris, France
Joined December 2012
🥳My friend @oussamazekri_ and I are happy to launch our research blog. Today, we are releasing the first blogpost on the Convolutional Kernel Network (CKN) introduced by @julienmairal. Many thanks to him for proofreading it! We hope you will enjoy it.

9
101
649
RT @_Vassim: 🚨New AI Security paper alert: Winter Soldier 🥶🚨.In our last paper, we show:.-how to backdoor a LM _without_ training it on the….
0
22
0
Here is the recording with the slides for those interested! . 🎤 📊📑 @Cohere_Labs @Cohere_Labs.

Our ML Theory group is looking forward to welcoming @AmbroiseOdonnat next week on Thursday, June 19th for a session on "Large Language Models as Markov Chains"

0
5
18
🚀To know more about LLM as Markov Chains, join in on June 19th at 6 pm CET (Paris time)!!😀 . Huge thanks to @itsmaddox_j and @cohere @Cohere_Labs for the invitation 🤗. Paper: .meeting:
Our ML Theory group is looking forward to welcoming @AmbroiseOdonnat next week on Thursday, June 19th for a session on "Large Language Models as Markov Chains"
0
3
4
RT @itsmaddox_j: Super excited to host @AmbroiseOdonnat next week, particularly to hear about the connection between LLMs and their n-gram….
0
2
0
RT @romanplaud: Very interesting work! These findings closely align with ours on the existence of high-entropy 𝘤𝘳𝘪𝘵𝘪𝘤𝘢𝘭 𝘵𝘰𝘬𝘦𝘯𝘴—tokens that….
0
3
0
RT @MoritzLaurer: Hidden gem: The @Cohere_Labs speaker series. Every week you can just drop into a call where some of the best ML/AI resear….
0
16
0
💎It also works for the newest -- strongest Gemma3 models (👏🏽@ramealexandre @mblondel_ml)!


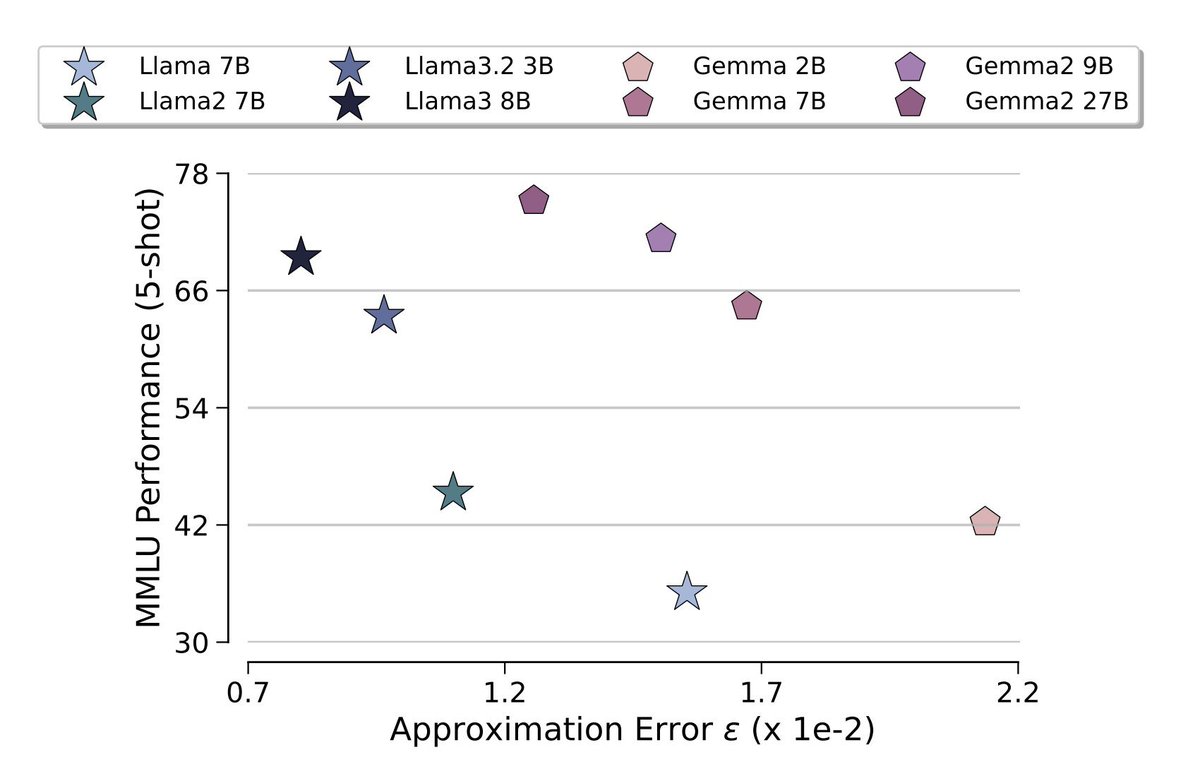
WOW. this is so underrated. Based on this formulation, they came up with a approximation trend which follows the trend of MMLU performance very closely.
0
1
5

📑Paper: 📈Slides: (better with Adobe Reader for nice GIFs).🌐Website:
0
0
1

RT @IevgenRedko: Our team open-sourced MANTIS: a foundation model for time series classification. It is lightweight, more efficient than c….
0
5
0
RT @garridoq_: The last paper of my PhD is finally out ! Introducing."Intuitive physics understanding emerges from self-supervised pretrain….
0
165
0
RT @geoffnegiar: We just released our new website! . Our goal for now is to provide the easiest, fastest benchmarking tools for forecasting….
0
4
0
RT @oussamazekri_: 🚀 Policy gradient methods like DeepSeek’s GRPO are great for finetuning LLMs via RLHF. But what happens when we swap au….
0
9
0
Finally, I can't thank you enough @_Vassim and @CabannesVivien for this collab: you are a rare combination of super-smart and fun to work with!. Hopefully, more to come soon🤠. "Moi, si je devais résumer ma vie aujourd’hui avec vous, je dirais que c’est d’abord des rencontres."

0
0
2
We want to thank @dohmatobelvis, @EshaanNichani, @_GPaolo, Faniriana Rakoto Endor, and @IevgenRedko for fruitful discussions during the elaboration of this work 😇.7/🧵.
1
0
2
From the theoretical side, we show that clustering heads can be learned via gradient descent and provide theoretical insights into the two-stage learning observed in practice. 6/🧵

1
0
0
We investigate loss spikes, suggesting potential strategies for mitigation, which could lead to more stable training processes. We also peek into the transferability of circuits to showcase the usefulness of curriculum learning and data curation. 5/🧵

1
0
0
In the second, we unveil "𝑪𝒍𝒖𝒔𝒕𝒆𝒓𝒊𝒏𝒈 𝑯𝒆𝒂𝒅𝒔", circuits that learn the invariance of the task. Their training dynamic is in two phases: 1) clustering of the attention embeddings according to invariance and 2) classifier fitting. 4/🧵

1
0
0
In the first paper, we show how GD (gradient descent) reinforces useful circuits in transformers while pruning others to create sub-circuits that help solve complex tasks by breaking them down into intermediate reasoning steps. 3/🧵

1
0
0