
Quentin Anthony
@QuentinAnthon15
Followers
1,000
Following
129
Media
38
Statuses
93
I make models more efficient. Google Scholar:
Joined June 2019
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Davido
• 514537 Tweets
Baba
• 116859 Tweets
Valencia
• 80399 Tweets
Abeg
• 77510 Tweets
Peruzzi
• 76169 Tweets
Nancy
• 69103 Tweets
Madonna
• 59256 Tweets
Wetin
• 58105 Tweets
Francis
• 53659 Tweets
Burna
• 49641 Tweets
Lewandowski
• 49185 Tweets
Rock in Rio
• 48120 Tweets
Araujo
• 46143 Tweets
Seinfeld
• 42040 Tweets
Jesus is King
• 39713 Tweets
Katy Tur
• 30231 Tweets
#WWERaw
• 26600 Tweets
Grammy
• 25632 Tweets
Luciano
• 16755 Tweets
ANA CASTELA NO RIR
• 14944 Tweets
PRE SAVE FOI INTENSO
• 14691 Tweets
#WWEDraft
• 10555 Tweets
カレンダー通り
• 10362 Tweets




















Zyphra is pleased to announce Zamba-7B:
- 7B Mamba/Attention hybrid
- Competitive with Mistral-7B and Gemma-7B on only 1T fully open training tokens
- Outperforms Llama-2 7B and OLMo-7B
- All checkpoints across training to be released (Apache 2.0)
- Achieved by 7 people, on 128…

21
86
429
State-space models (SSMs) like Mamba and mixture-of-experts (MoE) models like Mixtral both seek to reduce the computational cost to train/infer compared to transformers, while maintaining generation quality.
Learn more in our paper:

11
61
368
Getting the most out of your hardware when training transformers requires thinking about your model as a sequence of GPU kernel calls. This mindset, common in HPC, is rare in ML and leads to inefficiencies in LLM training.
Learn more in our paper

7
80
350
Studying interpretability? Curious about Mamba? Zyphra is here to help!
We're releasing 73 checkpoints of Mamba-370m over time! Hosted on HuggingFace:

2
16
91
How do LLMs scale on AMD GPUs and HPE Slingshot 11 interconnects? We treat LLMs as a systems optimization problem on the new
#1
HPC system on the Top500, ORNL Frontier.
Learn more in our paper:

2
22
80
The full recommendations are:
- Vocab size divisible by 64
- Microbatch size large as possible
- b*s, h/a, and h/t should be divisible by a power of 2
- (b*a)/t should be an integer
- t should be small as possible
10/11
1
7
55
Zamba's architecture alternates between 6 mamba blocks and a single shared self-attention block:

1
2
42
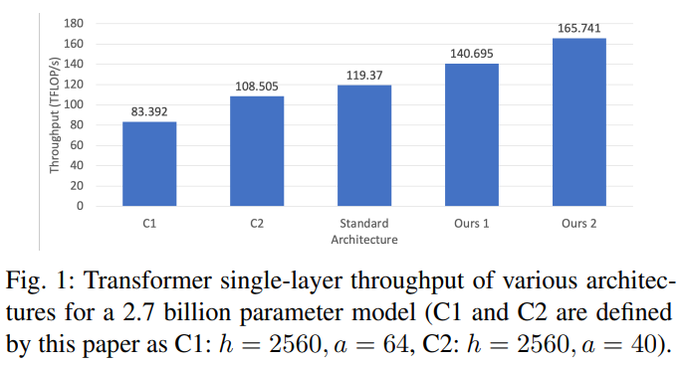
This is especially important because LLMs tend to copy architectures from previous models. GPT-3 2.7B's architecture was used by GPT-Neo, OPT, Pythia, RedPajama-INCITE, and Cerebras-GPT, but a small tweak to its shape provides a 20% throughput improvement! 2/11
1
1
33
On a more personal note, I'm so damn proud of my team. Zyphra is punching way above our weight in terms of manpower, compute, and data. We aren't industry insiders, and achieved this with willingness to learn and a ton of grit.
Kudos to you all
@BerenMillidge
@yury_tokpanov
…
4
1
33
Our analysis also explains the effect reported by
@karpathy
in his viral tweet last year about how vocab size matters for efficiency. Vocab should be divisible by 64 for the same reason h/a should be. 9/11

The most dramatic optimization to nanoGPT so far (~25% speedup) is to simply increase vocab size from 50257 to 50304 (nearest multiple of 64). This calculates added useless dimensions but goes down a different kernel path with much higher occupancy. Careful with your Powers of 2.
86
360
5K
2
2
25
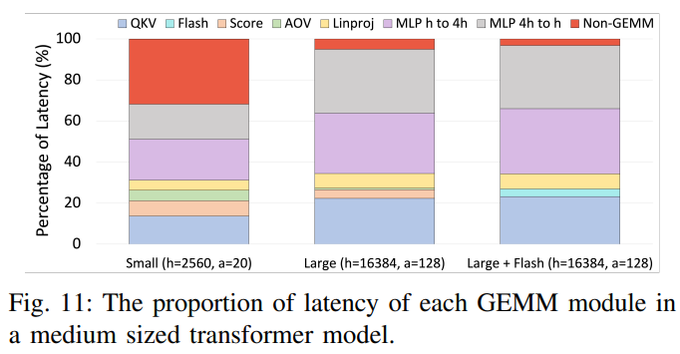
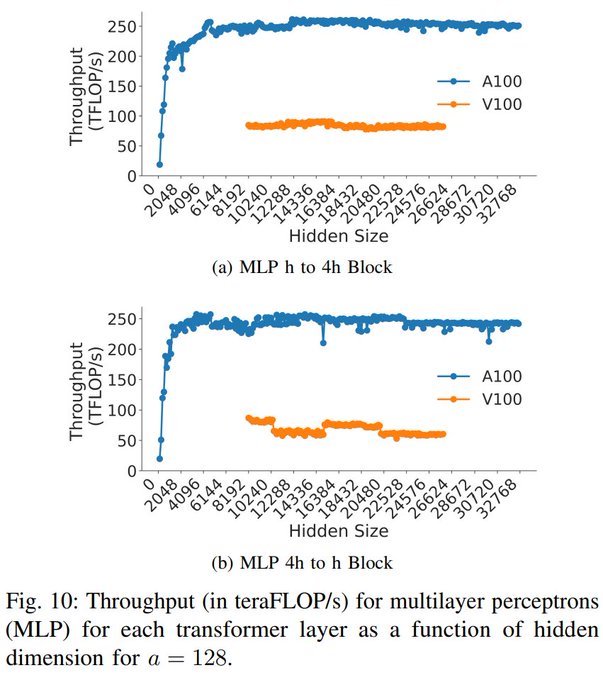
As model size grows, the majority of these GPU kernels are GEMMs spent on the transformer MLPs (4h --> h and h --> 4h). The good news is that these kernels are NVIDIA's specialty, and you just need a large enough hdim to saturate the GPU cores. 4/11
1
1
21
The two kernels required for the attention calculation, attention over values (AOV) and query-key-value calculation (QKV), are much more sensitive to the model size. Ensure h/a has as many factors of 2 as possible, preferably h/a divisible by 64. 5/11

1
0
20
Why hybrid? On the modeling side, the shared attention block resolves Mamba's shortcomings on in-context learning, as evidenced by Zamba's strong performance on MMLU.
On the efficiency side, Mamba blocks are more efficient than MLP + Attention layers, so our model requires fewer…
3
1
19
Before we dig in, some notation. We use the following variable names in the paper and thread. While we mostly talk about a single GPU for simplicity, our paper covers both single-node and data parallel across node settings. Pipeline parallelism requires additional analysis 3/11

1
0
19
If you're using flash attention, these sizing constraints have been handled for you by the flash library, and you only need a high enough hidden dimension to saturate the GPU cores 7/11

1
0
18
The wave-like patterns in the previous tweet are common on GPUs. Ops get executed in blocks of fixed size and if your ops don't divide evenly into blocks, some compute is wasted. As the block fills efficiency increases until it divides evenly, then a new block is needed. 6/11
1
0
18
While we're talking about releases, expect the model weights, checkpoints, training data, etc next week. We're currently cranking away getting our novel architecture into HuggingFace!
1
0
18
Zyphra's engineering mission is to put personalized models on your device. Model weights should be private and personalized to your needs. Zyphra believes that a giant monolithic model can't personalize to everyone on the planet.
1
0
17
Thank you to all of my amazing co-authors,
@yury_tokpanov
@PaoloGlorioso1
@BerenMillidge
HuggingFace:
GitHub:
Expect to find this work on arxiv soon!
0
1
15
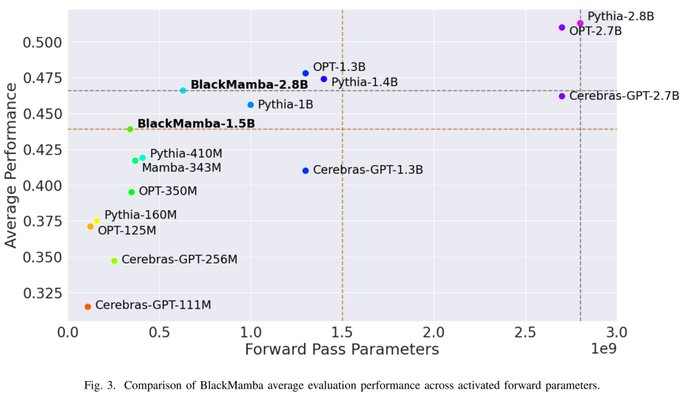
We train and open-source two LLMs on 300B tokens:
- BlackMamba-340M/1.5B
- BlackMamba-630M/2.8B
*Since models are MoE, the naming convention is "(forward pass params / total params)"
These models outperform similar in terms of FLOPs and forward pass params
1
2
15
Thank you to all my co-authors,
@jacob_hatef
@deepakn94
@BlancheMinerva
@StasBekman
Junqi Yin, Aamir Shafi, Hari Subramoni, and Dhabaleswar Panda, as well as
@StabilityAI
@ORNL
and
@SDSC_UCSD
for providing computing resources. 11/11
0
0
15
We include case studies of 6xGPU nodes, SwiGLU-based architectures, and inference latency. This last case study is particularly interesting, as we find that good (or bad!) model sizing will affect the model for its entire lifecycle. 8/11

1
0
14
We performed a two-phase training approach initially using lower-quality web-data followed by high quality datasets.
All of this data was open-source. We collected no data ourselves, and were careful about contamination. We'll be releasing a subsequent paper providing all these…
2
0
14
@arankomatsuzaki
What's the point of a scaling law with this few of FLOPs?
Largest dense model is 85M trained on 33B tokens.
Wouldn't take these results seriously tbh, and these authors have a bit of a track record of doing this, unfortunately.
2
0
11
Very impressive work!

Introducing BTLM-3B-8K: an open, state-of-the art 3B parameter model with 7B level performance. When quantized, it fits in as little as 3GB of memory 🤯. It runs on iPhone, Google Pixel, even Raspberry Pi. BTLM goes live on Bittensor later this week! 🧵👇

19
170
602
0
3
8
BlackMamba combines these architecture alternatives by alternating between Mamba and MoE-MLP blocks. The mamba block processes the whole sequence, then the gating network routes individual tokens to their respective MLP experts.

1
0
10
Along the interpretability angle, if you want to study Mamba, we trained a pure Mamba-350M on our dataset.
We also trained the original Mamba-370M on the Pile!
All checkpoints and dataset available upon request.
2
0
9
In addition to strong evaluation performance, Mamba-MoE have the best inference efficiency compared to equal-total-parameter Transformer, Transformer-MoE, and Mamba models.
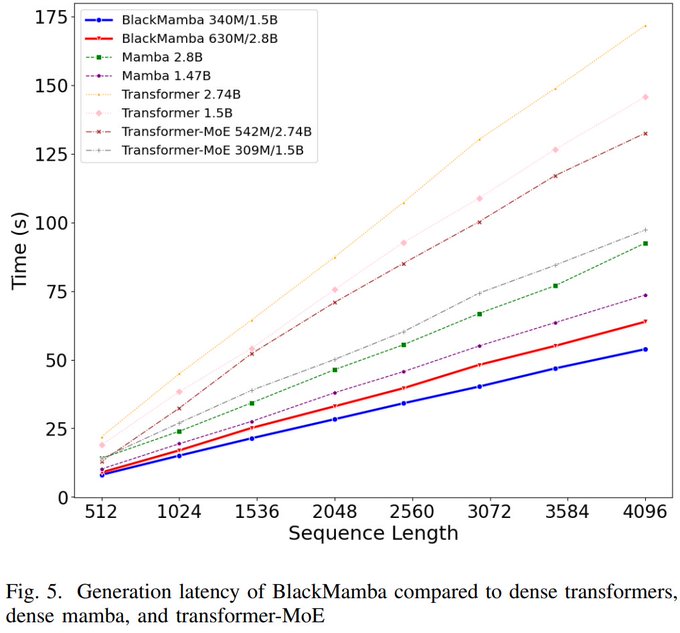
1
1
9
Our motivation stems from the original Mamba paper's figure 9 plotting Mamba-MLP. If we improve the model's MLP FLOP-efficiency with MoE, can we bring Mamba-MLP below pure Mamba?
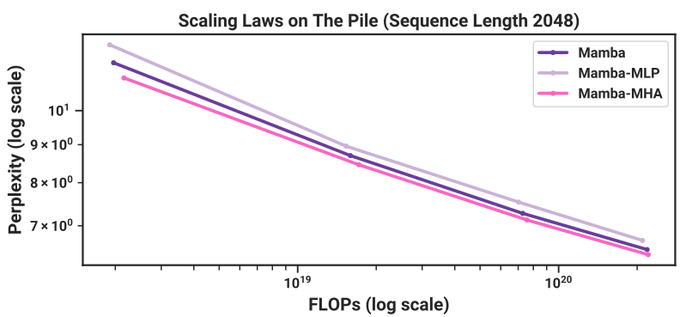
1
0
7
In order to study the interpretability of our models, we took the MoE routing distribution across time and depth. We also took frequent checkpoints (every 2.5k iters out of 150k) during training, and would love to provide either them or the dataset upon request!

1
0
7
Before we can pretrain, we compiled a custom 1.8T dataset based on existing open datasets. The token and domain compositions of this dataset are provided in the figures below. The long-term goal of this dataset is to study the effects of long-form text and multiple epochs.


1
1
6
To get everyone on the same page, Mamba () is a state-space model with linear complexity in sequence length, and MoE routes individual tokens to their appropriate "expert" MLP ().
1
0
7
@StasBekman
Piggybacking off this, I extended Stas' communication benchmark to all collectives and point-to-point ops for pure PyTorch distributed and DeepSpeed comms in
Give it a try if you're looking to understand your target collective's behavior!
0
0
6
What about flash attention? Both flash v1 and v2 have now been ported to ROCm, and we confirmed that they get the expected benefits (higher throughput and lower memory overhead) over vanilla attention on MI250X.

2
0
4
Time for parallelism! On a single Frontier node, ZeRO-1 achieves the same throughput as the data-parallel 1.7B. Tensor parallelism gives a slight degradation, and our pipeline parallelism bubble led to massive degradations.

1
0
4
- Each Frontier node has 4 AMD MI250X GPUs, each containing 2 Graphics Compute Dies (GCDs).
- Each GCD is a separate rank.
- GCDs within the node are connected via AMD InfinityFabric (50-100 GB/s across GPUs, 200 GB/s within GPU).
- Nodes are connected via HPE Slingshot 11 (25…
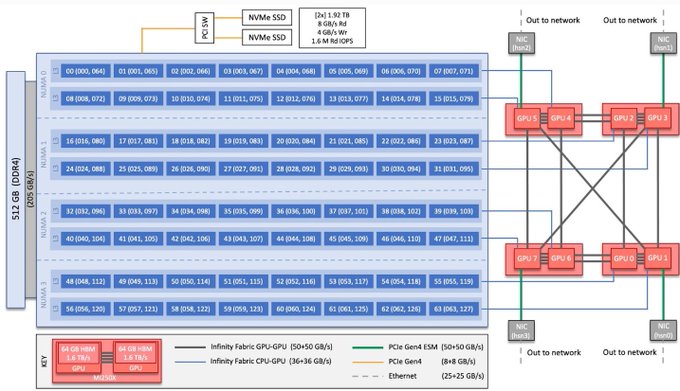
1
0
5
We know that certain hidden dimensions lead to better GEMM kernel behavior on NVIDIA GPUs (see ), and we confirmed that making your hdim divisible by many powers of 2 gives efficiency gains.

1
0
5
Now live on arxiv:

0
0
5
The interpretability of state-space models such as Mamba is an open question. How do model dynamics change across time and depth? While attention-based intermediate checkpoints exist in works such as Pythia, LLM360, and OLMo, no such checkpoints over time are available for Mamba…
1
1
4


What about across nodes? At the time of writing, Slingshot 11 + RCCL has poor inter-node collective performance. While ZeRO-1 gave the best single-node throughput, it doesn't scale on Frontier due to its high inter-node communication needs.

1
0
3
First off, which LLM type should we focus on? Since we all know decoder-only models are all the rage, we use GPT as our representative LLM example.

1
0
3
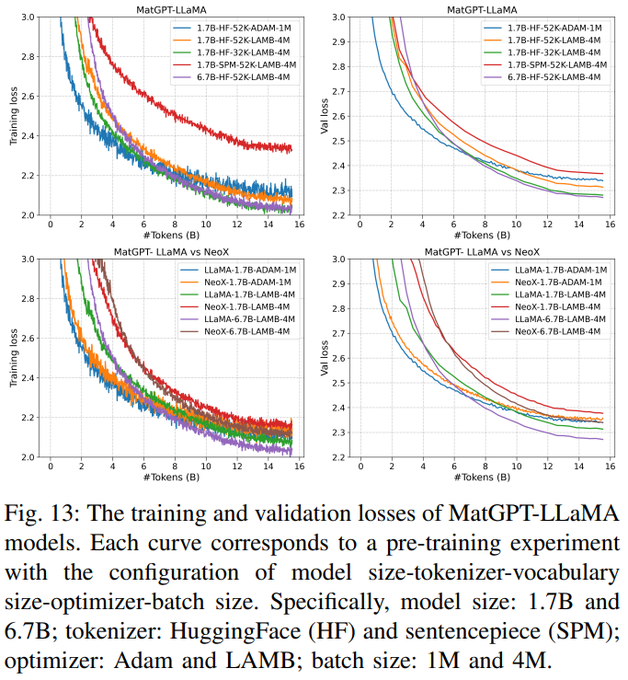
To test our setup, we pre-trained a suite of 1.7B and 6.7B models on a full-text scientific paper corpus of 15B tokens. We compare across optimizer type, batch size, tokenizer type, vocab size, etc.
1
0
3
How about across model scale? We looked at the pure data-parallelism case with 1.7B parameters, and the model-parallelism regime with 6.7B parameters.

1
0
3
Thank you to my amazing co-authors Junqi Yin, Avishek Bose, Guojing Cong, and Isaac Lyngaas.
1
1
3
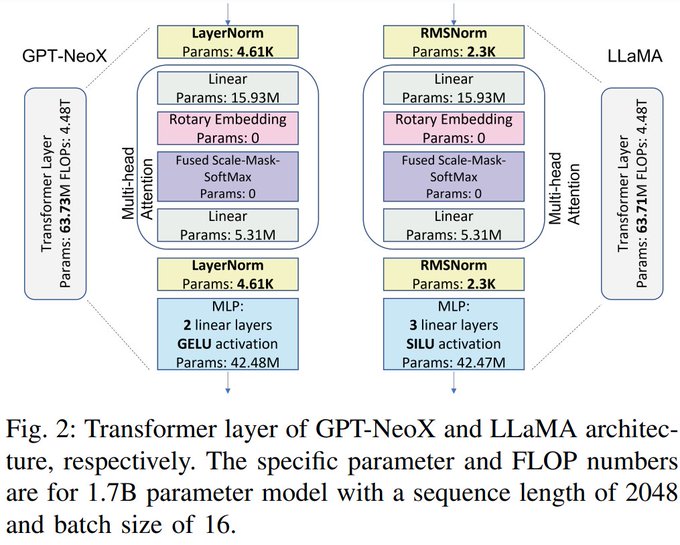
Within GPT models, we looked at two common model configurations. GPT-NeoX styled models use LayerNorm and 2 GELU linears as MLPs, LlaMa-styled models use RMSNorm and 3 SILU linears as MLPs.
1
0
3
We took some traces of the 6.7B with ZeRO-1 at 256 GPUs. Comms are too large to overlap, and the low-power regime is just GPUs sitting around waiting for comms to finish.

1
0
3
@StasBekman
@svetly
This is on ORNL Summit ().
- 27,648 total V100 GPUs
- 6 V100s/node
- EDR InfiniBand
Node topology:

1
0
3
We compared LlaMa-styled and GPT-NeoX-styled models, and confirmed that Layernorms and a difference in one linear layer don't change your performance much. Therefore, we will choose whichever arch gives the best model accuracy.

1
0
3
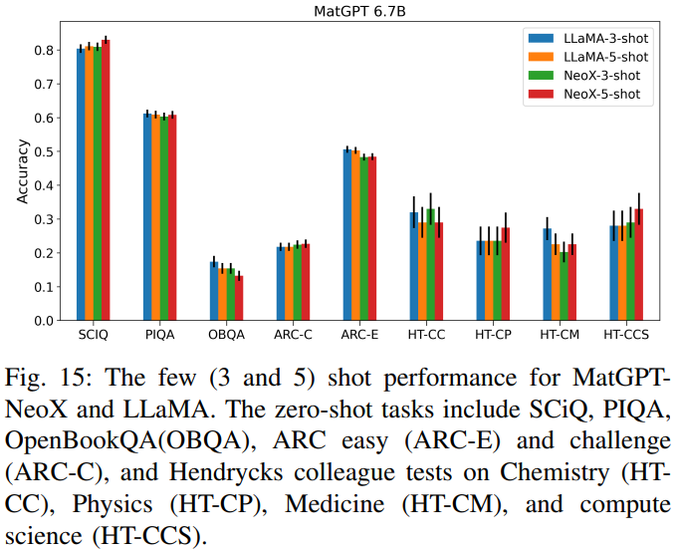
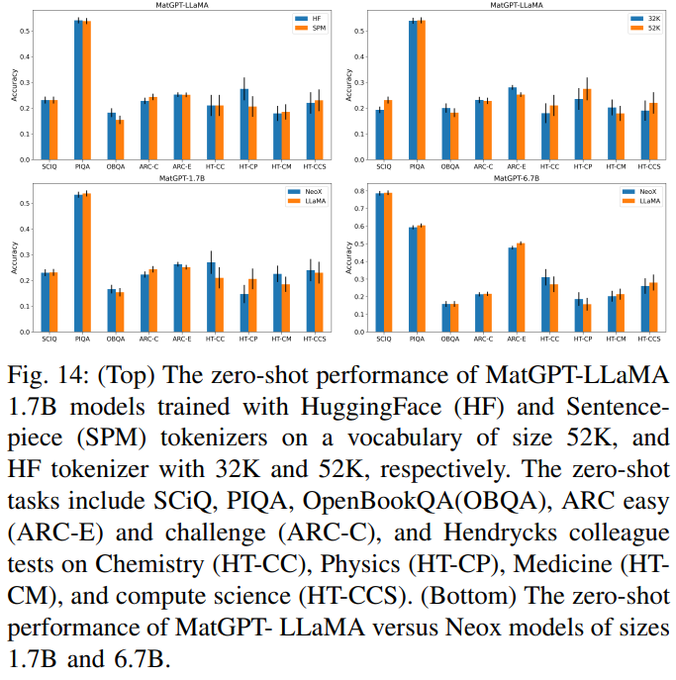
LLM loss is a poor indicator of model quality. While each training recipe has wildly different loss, eval performance is comparable.
1
0
3
The best embedding clustering should reflect the characteristics of the prediction target — band gap. Materials can be classified by band gap into a few categories, i.e., conductor, semiconductor, or insulator. It seems the knowledge embedded in MatGPT can be additional features…
1
0
3
We propose the hypothesis that model embeddings trained on scientific texts encode the knowledge of the literature. Our evidence is as follows:
- Using a GNN + MatGPT embeddings gives SOTA accuracy on band gap prediction, which is an extremely challenging materials science…

1
0
3
- The embedding clustering of GPT-based models suggests a richer representation than MatSciBERT
- MatSciBERT just forms a very large cluster (indicating poor knowledge representation).
- Embedding distances between MatSciBERT vectors are larger than MatGPT, which…

1
0
3
Maybe I shouldn't have posted this 2 hrs before the B100 announcement...
0
0
2

@StasBekman
@svetly
GPT-NeoX () also scales pretty well there. (Disclaimer, this is a 1.3B model):
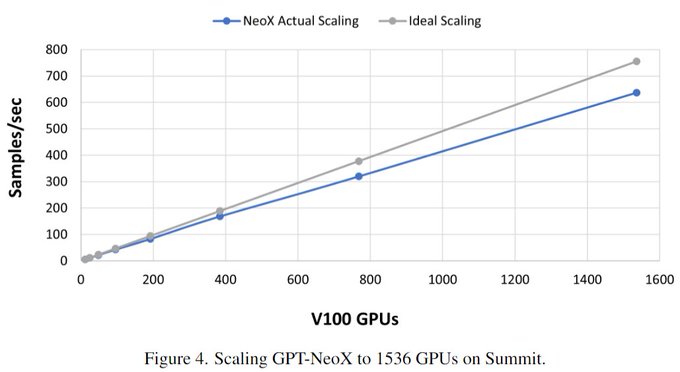
1
0
2
To help interpretability researchers, Zyphra reproduced the Mamba-370m model from () on 300B tokens from The Pile, and is releasing 73 checkpoints over time.

1
0
2
Special thanks to my amazing colleagues on this effort!
@yury_tokpanov
@PaoloGlorioso1
@BerenMillidge
@J_Pilault
0
0
2
@1littlecoder
Those models are very small and trained on very few tokens.
Based on that, I actually suspect we started work around the same time. Our models are large enough and trained on enough tokens to be useful artifacts, which takes a bit more time.
We also released them.
0
0
2
@sid09_singh
I don't have anything dataset-specific since I personally use this dataset for "ensure loss goes down" and throughput checks. Maybe port the Pythia configs and use a single epoch?
0
0
1
Specifically, we took ckpts every 10k iterations up to iter 610k. Since model dynamics are especially interesting early on, we took log-spaced checkpoints (1, 2, 4, 8, ...) up to iteration 2048.
1
0
1
We aren't entirely certain why average accuracy is very slightly (~0.1) worse than the original Mamba-370m. A few theories we have:
- Different version or setup of lm_eval? We used v0.3.0
- We used LayerNorm instead of RMSNorm
Open to suggestions/theories!
1
0
1
All checkpoints are available through
Inference code is available through

1
0
1
@StasBekman
For OpenMPI this is `--tag-output` ([jobid, MCW_rank]<stdxxx>) and `--timestamp-output` ()
1
0
1

@Dynathresh
There's nothing fundamentally stopping it to my knowledge. The compute and know-how requirements to pretrain any LLM are prohibitive, and mamba just came out Dec 2023. My guess is that larger models are already underway, but take time.
0
0
1