
Yian Zhang
@zhang_yian
Followers
199
Following
103
Media
12
Statuses
63
Post-training Nemotrons @NVIDIA Prev @stanfordnlp @CILVRatNYU @SiebelScholars Class of 2023 Opinions are my own.
Joined October 2020

🚀 We’re hiring at NVIDIA! Our team is pushing the frontier of LLM / DLM post-training and system optimization. We are looking for exceptional people with large-scale LLM + systems experience to join us (full time only). 🔹 Focus areas include: •Post-training of large models
18
33
462

NVIDIA has released Nemotron Nano 9B V2, a small 9B reasoning model that scores 43 on the Artificial Analysis Intelligence Index, the highest yet for <10B models Nemotron 9B V2 is the first Nemotron model pre-trained by @NVIDIA. Previous Nemotron models have been developed by

21
67
549

Blazing-fast image creation – using just your voice. Try Grok Imagine.
343
669
4K
Strongest and fastest at the scale of ~8b.

We're excited to share leaderboard-topping 🏆 NVIDIA Nemotron Nano 2, a groundbreaking 9B parameter open, multilingual reasoning model that's redefining efficiency in AI and earned the leading spot on the @ArtificialAnlys Intelligence Index leaderboard among open models within
0
0
5

We are thrilled to achieve this milestone in AI reasoning models.
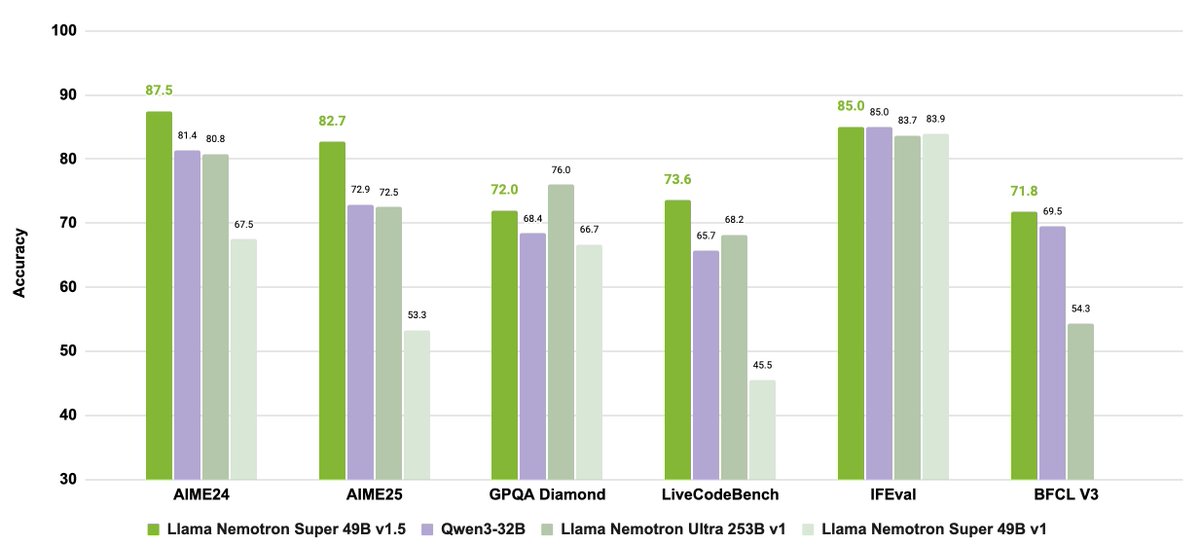
We’re excited to share that 🥇Llama Nemotron Super 49B v1.5 -- our latest open reasoning model -- is now #1 on the @ArtificialAnlys Intelligence Index - a leaderboard that spans advanced math, science, and agentic tasks, in the 70B open model category. Llama Nemotron Super 49B
31
86
417
NVIDIA has released the latest member of its Nemotron language model family, Llama Nemotron Super (49B) v1.5, reaching a score of 64 on the Artificial Analysis Intelligence Index. The model is an evolution of Super 49B v1 from earlier this year, with advances from post-training


13
46
344
We want to set a SUPER high bar for OAI's open-source release 😉
📣 Announcing Llama Nemotron Super v1.5 📣 This release pushes the boundaries of reasoning model capabilities at the weight class of the model and is ready to power agentic applications from individual developers, all the way to enterprise applications. 📈 The Llama Nemotron
0
3
30
👀 Nemotron-H tackles large-scale reasoning while maintaining speed -- with 4x the throughput of comparable transformer models.⚡ See how #NVIDIAResearch accomplished this using a hybrid Mamba-Transformer architecture, and model fine-tuning ➡️ https://t.co/AuHYANG9gX

3
28
128


Open recipe and open data for training the best open model.


0
0
2
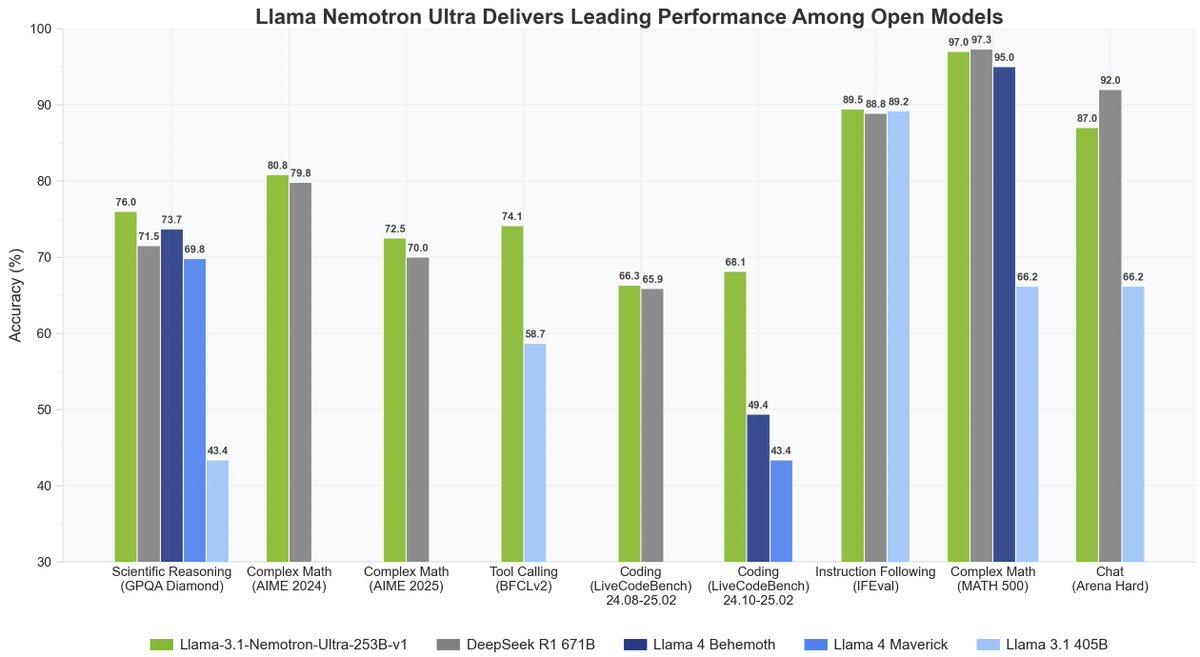
🎊 Llama Nemotron Ultra 253B is here 🎊 ✅ 4x higher inference throughput over DeepSeek R1 671B 🏆Highest accuracy on reasoning benchmarks: 💎 GPQA-Diamond for advanced scientific reasoning 💎 AIME 2024/25 for complex math 💎 LiveCodeBench for code generation and completion

12
65
356
Probably the best open model at the moment

We are excited to release Llama-Nemotron-Ultra! This is a reasoning ON/OFF, dense 253B model. Open weights and post-training data. https://t.co/dCTacylBR8 We started with llama-405B, changed it via NAS pruning then followed by reasoning-focused post-training: SFT + RL in FP8.

0
0
5

New on LMArena: @Nvidia's Llama-3.3-Nemotron-Super-49B-v1 lands at #14! A powerful open reasoning model—top-15 overall, excelling in math, with an openly released 15M post-training dataset. Congrats to the @NvidiaAI Nemo team for this fantastic contribution to the open

We are excited to release new Llama-Nemotron models. These models allow you to set reasoning ON/OFF during runtime. We also release all the post-training data under CC-BY-4! Try it now on https://t.co/Q7jFIMi0po HF collection: https://t.co/E8mNZlUXz0

3
30
198
We are excited to release new Llama-Nemotron models. These models allow you to set reasoning ON/OFF during runtime. We also release all the post-training data under CC-BY-4! Try it now on https://t.co/Q7jFIMi0po HF collection: https://t.co/E8mNZlUXz0
8
42
194
This is a collaborative effort with @ssydasheng, @AlexanderBukha1, David Mosallanezhad, Jiaqi Zeng, @soumyesinghal, Gerald Shen, @rendu_a, @ertkonuk, Yi Dong, Zhilin Wang, Dmitry Chichkov, Olivier Delalleau, and @kuchaev.
0
0
0
A last highlight from the paper is that RPO is not just an algorithm - it is a framework that unifies many existing algos. e.g. RPO-sqloo is equivalent to RLOO . 🤯🤯🤯Read the paper for more details! (3/3)
1
0
0
TL;DR 1: RPO-bwd and DPO generally work pretty well compared to other algorithms; SimPO has an advantage on small models. TL;DR 2: You should go for it whenever online and iterative training is an option. (2/3)
1
0
0
DPO, SimPO, RPO, ... There are just too many **PO**s in the NLP/LLM world! 💥💥💥😲 If you wonder which PO truly works the best, how to make them even better, and their inter-connections, read our latest paper at https://t.co/n5i63aoqha 👇 (1/3)

1
5
12
Our team put together a unified mathematical framework to analyze popular model alignment algorithms. “Reward-aware Preference Optimization: A Unified Mathematical Framework for Model Alignment” https://t.co/qz99EZGJx0

2
19
72

Today, HELM was recognized by @TmlrOrg with its best paper award! The true success of HELM has been the sustained maintenance, growth, and impact led by @yifan_mai @percyliang 5k commits, 2k PRs, 2k stars, 1k citations, 11 leaderboards, 20 partner orgs https://t.co/iUBoKKvDDg
5
16
105

I'm excited to announce my new lab: UCSD's Learning Meaning and Natural Language Lab. a.k.a. LeM🍋N Lab! And 📢WE ARE RECRUITING📢 PhD students to join us in sunny San Diego in either Linguistics OR Data Science. Apply by Dec 4: https://t.co/gCYN8eMk4A More about the lab👇

12
76
450