

Wittawat Jitkrittum
@wittawatj
Followers
2K
Following
811
Media
27
Statuses
1K
Research scientist at Google working on LLM model routing, and cascading. Former @MPI_IS postdoc. Did PhD @GatsbyUCL.
New York
Joined May 2011
RT @roydanroy: Appears to be a breakthrough result but no mention of Nagarajan (@_vaishnavh ) and his insight into pitfalls of next token p….

arxiv.org
Transformers have demonstrated remarkable capabilities in multi-step reasoning tasks. However, understandings of the underlying mechanisms by which they acquire these abilities through training...
0
54
0
RT @steverab: 🏅 Very excited to share that my recent Google internship project on model cascading has received the 𝗕𝗲𝘀𝘁 𝗣𝗼𝘀𝘁𝗲𝗿 𝗔𝘄𝗮𝗿𝗱 at the….
0
1
0

RT @_vaishnavh: Today @ChenHenryWu and I will be presenting our #ICML work on creativity in the Oral 3A Reasoning session (West Exhibition….
0
18
0
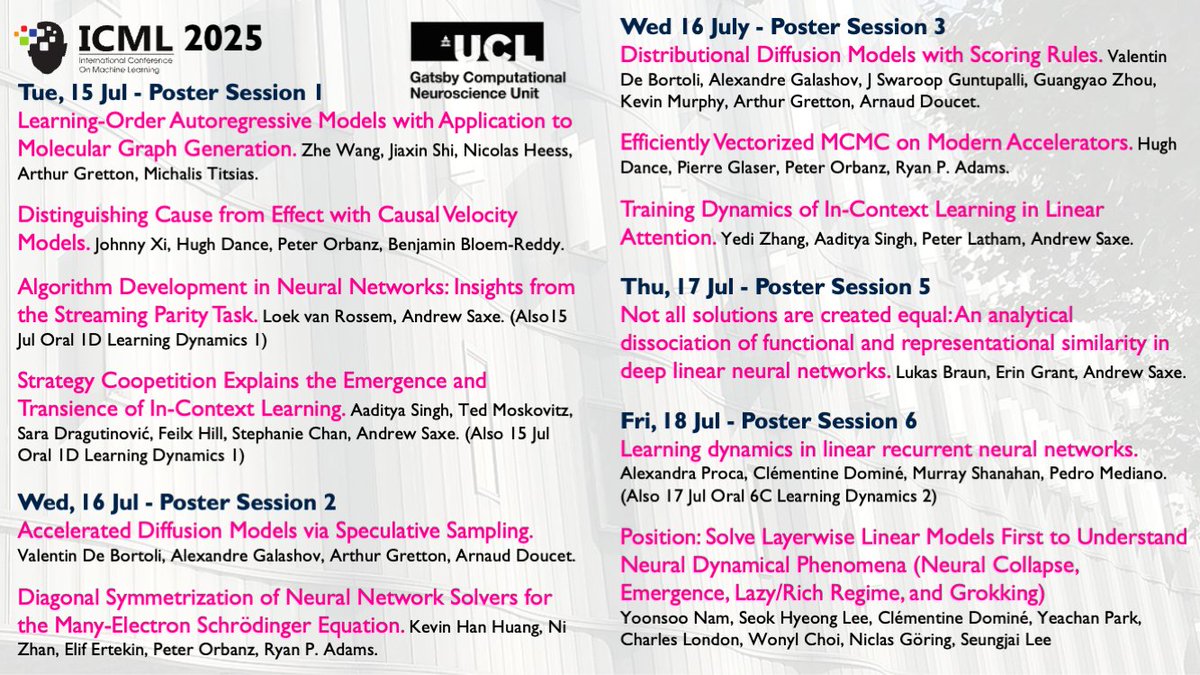
RT @GatsbyUCL: 👋 Attending #ICML2025 next week? Don't forget to check out work involving our researchers!
0
5
0
I will be at ICLR 2025 in Singapore next week. If you would like to meet and chat, please let me know. Potential topics of interest: query routing for LLMs, LLM's inference efficiency, kernel methods, hypothesis testing, etc.
1
0
6
RT @MPICybernetics: Apply now ⏰for the 3-months #CaCTüS #internship in Germany 🇩🇪 in summer 2025! .🌵 Research projects in #machinelearning,….
0
58
0
RT @GatsbyUCL: Huge congratulations to John Hopfield and our founding director Geoffrey Hinton @geoffreyhinton!.
0
12
0
RT @CsabaSzepesvari: The Association for Mathematic Research announces "Prize in the Mathematics of Artificial Inte….
0
63
0
RT @FrnkNlsn: Must-read excellent books with 🆓 PDF available to download from the author/book web pages:. 👉 https:/….
0
211
0
RT @LeopolisDream: State Space Models: A Modern Approach. This is an interactive textbook on state space models (SSM) using the JAX Python….
0
232
0
Deep Learning: Foundations and Concepts by Chris Bishop and Hugh Bishop. Free e-book available.
2
3
7
RT @songandyliu: Join us at the FIMI workshop on Functional Inference and Machine Intelligence at Bristol Uni., 25-27 March! Features stude….
0
11
0
If you are at NeurIPS, please check out our poster on Tue 12 Dec 10:45 a.m. CST — 12:45 p.m. CST. Paper: Thank you.
openreview.net
Cascades are a classical strategy to enable inference cost to vary adaptively across samples, wherein a sequence of classifiers are invoked in turn. A deferral rule determines whether to invoke...
0
0
3
Remedy: train a router model post-hoc to predict the difference of conditional accuracy of the two models (as suggested by the optimal rule). We observe experimentally that the post-hoc rule outperforms confidence-based rule in the 3 scenarios above.
1
0
2
We can compare the optimal rule above to the rule that relies only on the confidence of model 1. We identified 3 scenarios where the confidence-based rule can fail: 1. when model 2 is a specialist, 2. when there is label noise, 3. when the label distribution is skewed.
1
0
0
We derive the Bayes optimal deferral rule r* which looks like this. This is saying that it is optimal to defer to model 2 if the gain in conditional accuracy on input x exceeds c, where c is the cost of calling model 2.

1
0
1
Main research question: under what conditions would this confidence-based deferral rule succeed or fail? . We formulate a loss function that encourages the cascade to invoke the larger model sparingly while keeping the overall classification error low.
1
0
0
Consider 2 classifiers: 1. small, reasonably accurate, 2. large (costly), very accurate. Form a cascade where we first call model 1, and check whether it is confident (i.e., by thresholding its max. predictive class probability). If yes, use model 1. If not, use model 2.

1
0
2
We are happy to present a poster at NeurIPS 2023 titled ”When does confidence-based cascade deferral suffice?”. Poster attached.

2
5
29
RT @MIJUNGPARK11: We're hiring a Postdoc and two Ph.D. students to work together on privacy problems in ML at DTU. (and yes, I moved again,….

efzu.fa.em2.oraclecloud.com
Do you want to advance state-of-the-art privacy-preserving machine learning algorithms? We are looking for a postdoc, who is creative and enthusiastic for advancing machine learning research....
0
4
0