
Tuomas Oikarinen
@tuomasoi
Followers
112
Following
17K
Media
11
Statuses
57
Developing scalable ways to understand neural networks. PhD student at UCSD. https://t.co/aiLkcmamyb
Joined April 2021
Excited to present our new paper at ICML - Evaluating Neuron Explanations: A Unified Framework with Sanity Checks. How do you know if your automated interpretability description is faithful? We discover that most currently popular evaluation methods fail simple sanity checks.

1
0
2
Come by poster E1107 4:30pm today if you’re interested in evaluating automated interpretability!
Excited to present our new paper at ICML - Evaluating Neuron Explanations: A Unified Framework with Sanity Checks. How do you know if your automated interpretability description is faithful? We discover that most currently popular evaluation methods fail simple sanity checks.
0
0
2
To learn more stop by our poster E-1107 Wednesday 4:30-7pm! Arxiv: https://t.co/azCLsB64hu Code: https://t.co/ojrELh13Qr Website: https://t.co/YvAWAm2qdM Joint work with @LilyWeng_ and Ge Yan!

github.com
[ICML 25] A unified mathematical framework to evaluate neuron explanations of deep learning models with sanity tests - Trustworthy-ML-Lab/Neuron_Eval
0
0
1
Overall we recommend using metrics that pass these tests, such as Correlation (uniform sampling), AUPRC and F1-score/IoU. Using proper evaluation metrics is important for advancing automated interpretability, but also for developing interpretable decompositons like SAEs.
1
0
0
We discover that many popular methods fail these simple tests, such as: - Evaluating on highly activating inputs only (Recall) - Correlation with top-and-random sampling - Mean Activation Difference (MAD)
1
0
0
To understand which metrics are the best, we propose simple sanity checks measuring whether a metric can differentiate the perfect explanation from an overly generic/overly specific one.

1
0
0
We unify 20 diverse evaluation methods under the same framework, and show they can be described as comparing the similarity between a neuron activation vector and a concept presence vector. Differences are mostly on the similarity metric used, and how concept vector is annotated.
1
0
0

⚡ Making Deep Generative Models Inherently Interpretable – Catch us at #CVPR25 this week! ⚡ We’re excited to present our paper, Interpretable Generative Models through Post-hoc Concept Bottlenecks, at @CVPR 2025 this week! 🚀Project site: https://t.co/bzRBQRjCPl
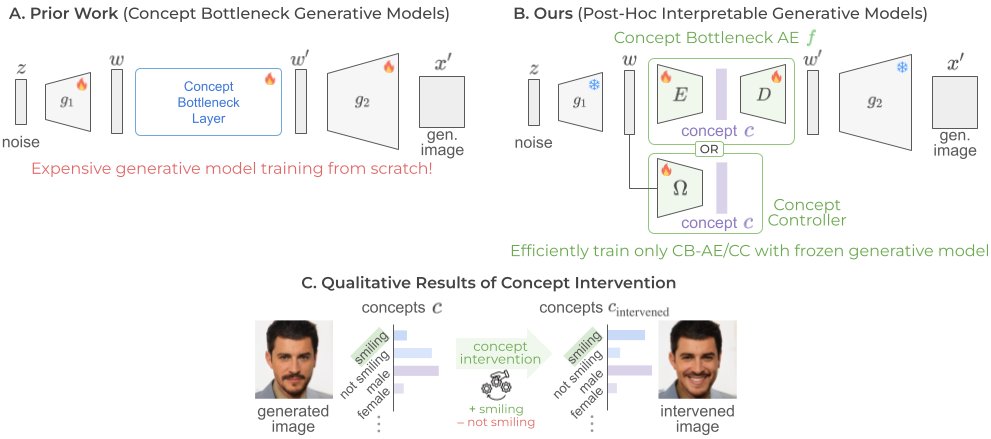
0
3
6
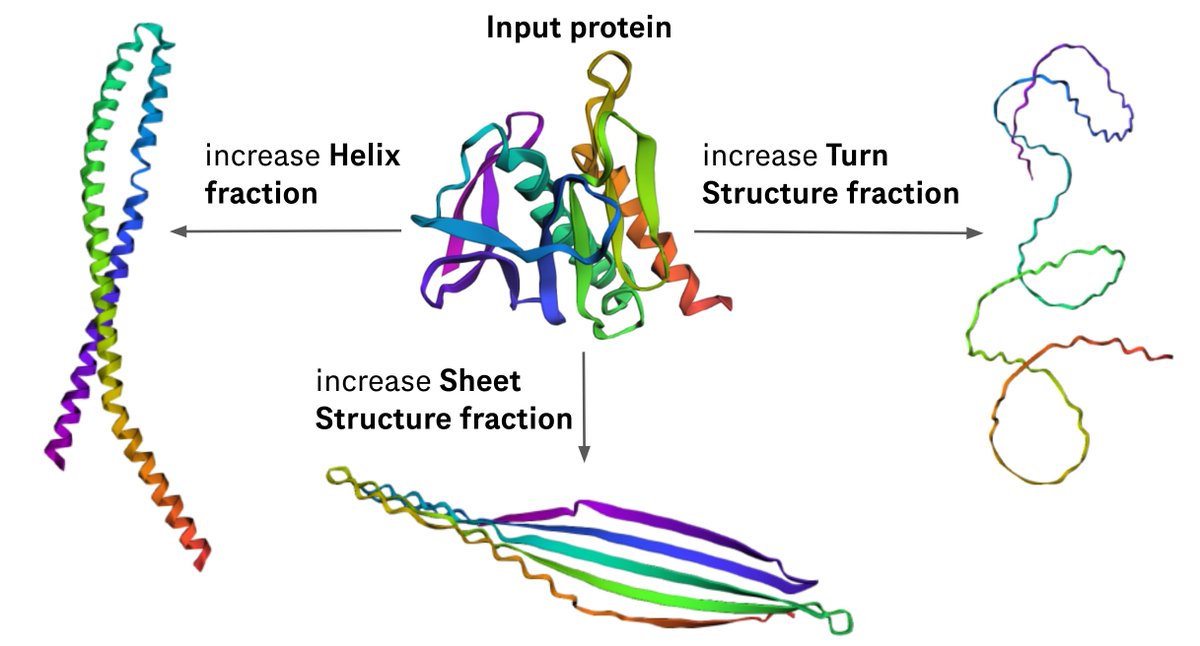
I will be presenting this work tomorrow at #ICLR2025 at 10 am stop by to know how to build protein language models and use them to design proteins with new properties!

[1/n] Does AlphaFold3 "know" biophysics and the physics of protein folding? Are protein language models (pLMs) learning coevolutionary patterns? You can try to guess the answer to these questions using mechanistic interpretability. But the thing is, more often than not, we know
0
10
43
💡LLMs don’t have to be black boxes. We introduce CB-LLMs -- the first LLMs with built-in interpretability for transparent, controllable, and safer AI. 🚀Our #ICLR2025 paper: https://t.co/08Q4Jcl39L
#TrustworthyAI #ExplainableAI #AI #MachineLearning #NLP #LLM #AIResearch
1
2
5
The nice thing about being in academia right now is that even if nobody reads your papers, at least the LLMs will
0
0
4
Check out our new paper on creating interpretable protein language models! Turns out Concept Bottleneck Models can be quite useful in the real world, allowing for example highly controllable protein generation!
[1/n] Does AlphaFold3 "know" biophysics and the physics of protein folding? Are protein language models (pLMs) learning coevolutionary patterns? You can try to guess the answer to these questions using mechanistic interpretability. But the thing is, more often than not, we know
0
1
8
2. Crafting Large Language Models for Enhanced Interpretability https://t.co/qqlHey0UpB A method to create Concept Bottleneck Models for language classification tasks with increased transparency. Come by the poster sessions 11am-12pm and 2:30pm-3:30pm to learn more.

arxiv.org
We introduce the Concept Bottleneck Large Language Model (CB-LLM), a pioneering approach to creating inherently interpretable Large Language Models (LLMs). Unlike traditional black-box LLMs that...
0
1
3
We will be presenting two papers at the Mechanistic Interpretability Workshop at ICML today! 1. Describe-and-Dissect: Interpreting Neurons in Vision Networks with Language Models (Spotlight!) https://t.co/7J2Y1eUbby A cool new way to create generative neuron descriptions.
1
0
4
I will be presenting our paper on Linear Explanations for Individual Neurons at ICML tomorrow Tuesday 11:30am-1pm! Come by poster #2601 if you want to learn more about how to understand neurons beyond just the most highly activating inputs. https://t.co/w1hswNA0S3
Excited to share our new ICML paper “Linear Explanations for Individual Neurons”. In the work we propose an elegant solution for explaining polysemantic neurons: Neuron are best understood as a linear combination of interpretable concepts.

0
0
7
Lowkey the most exciting part of the new Claude release. Happy to see some external oversight.

“We recently provided Claude 3.5 Sonnet to the UK’s Artificial Intelligence Safety Institute (UK AISI) for pre-deployment safety evaluation. The UK AISI completed tests of 3.5 Sonnet and shared their results with the US AI Safety Institute (US AISI) as part of a MoU”
0
0
1
If you want to learn more, check out our arXiv: https://t.co/vNlyYQlqsu GitHub: https://t.co/PggvkkILfc As a bonus, here is a Bald Eagle + Military vehicle neuron discovered in ViT-L/32

0
0
0
Finally we propose an efficient way to automatically evaluate explanation quality via simulation for vision models. This measures correlation between actual neuron activation and activation predicted by a model based on the explanation. We can see our LE performs the best.

1
0
0
We propose two effective ways to generate linear explanations: 1. LE(Label): Using human labeled concept data 2. LE(SigLIP): Using pseudo-labels from multimodal models. Both are fast to run (~4 seconds/neuron), and automatically determine good explanation length for each neuron.
1
0
0
For example, high activations of Neuron 136 (RN50 layer4) correspond to snow related concepts, while for low activations it responds to hounds and dogs in general. This is naturally represented by our explanation with snow related concepts having higher weigths.

1
0
0