
Thinh
@thinhphp_vt
Followers
71
Following
66
Media
4
Statuses
18
PhD student @VT_CS, supervised by @tuvllms. Interested in search-augmented LLMs. Ex AI resident @VinAI_Research
Blacksburg, VA
Joined July 2023
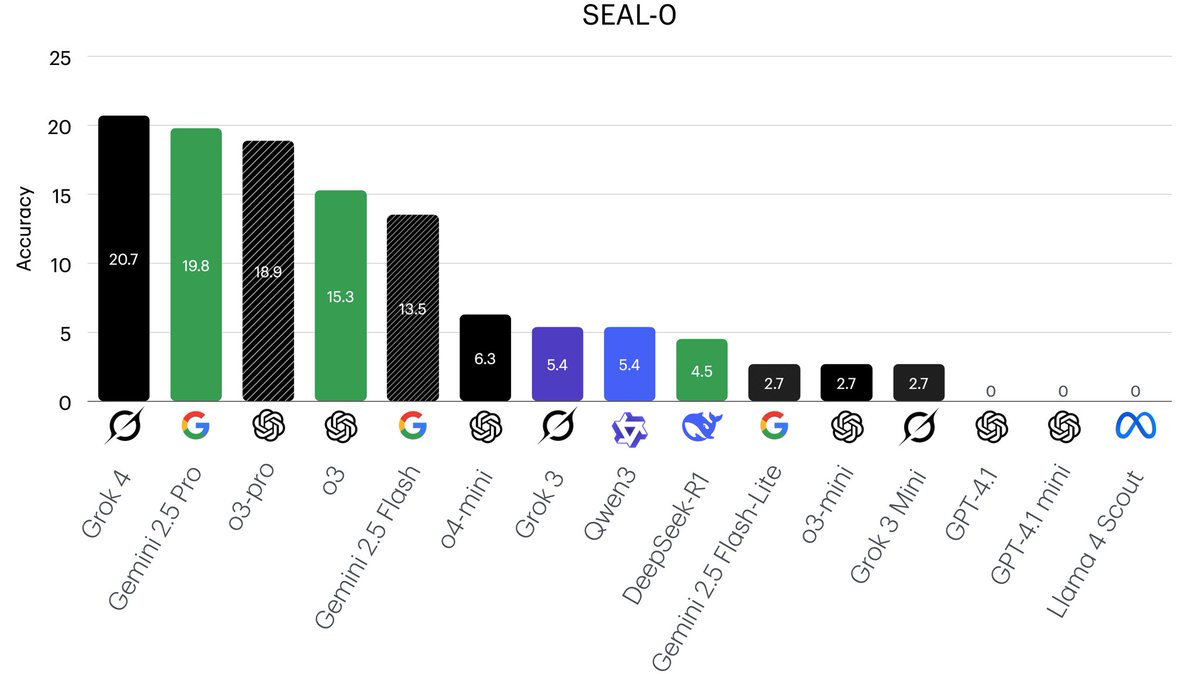
DeepSeek achieved a strong result on SEAL0, a challenging benchmark for reasoning with conflicting search results. 🎊.

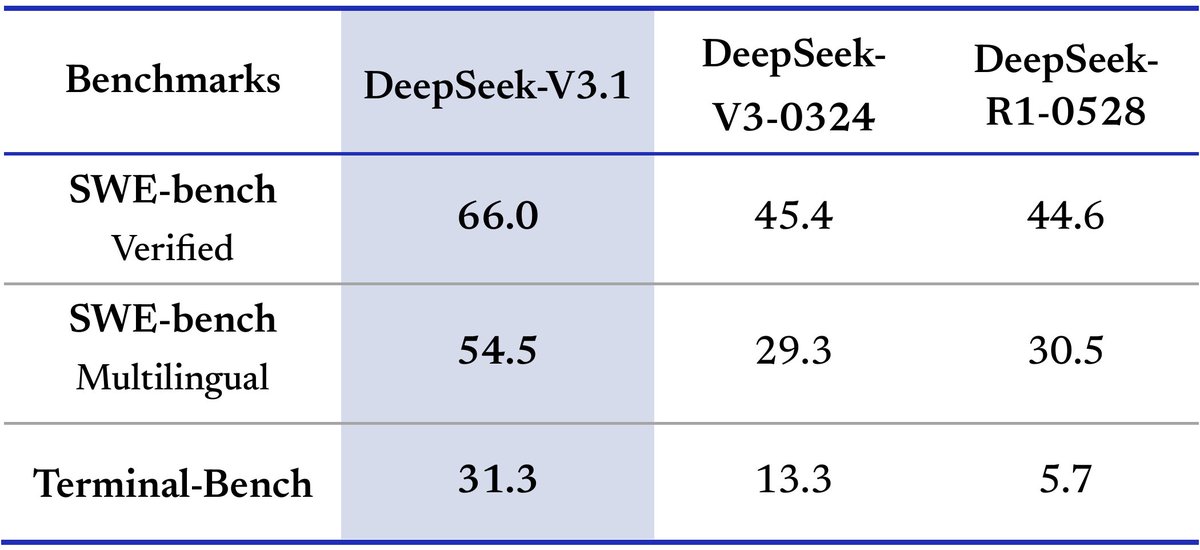
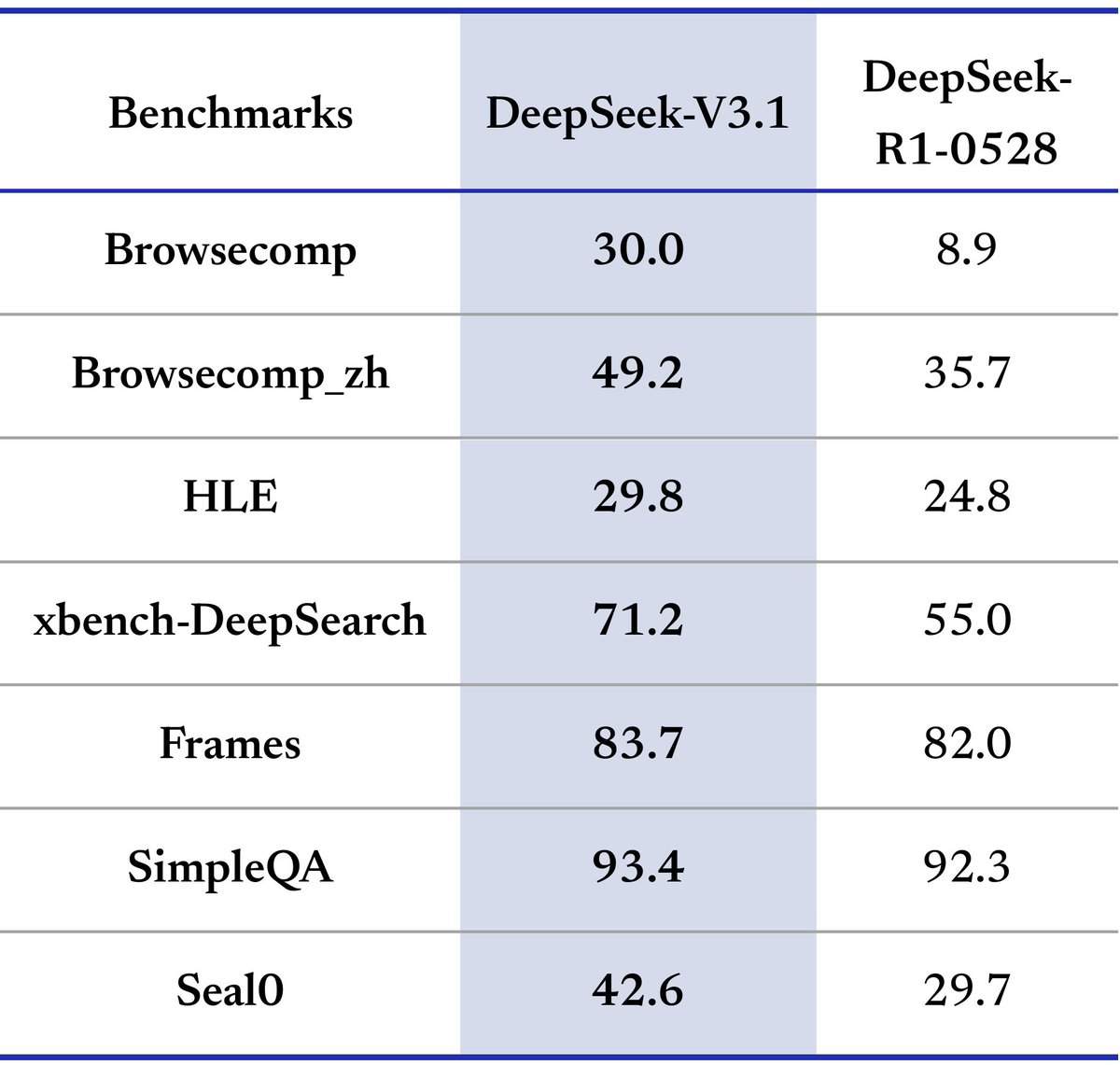
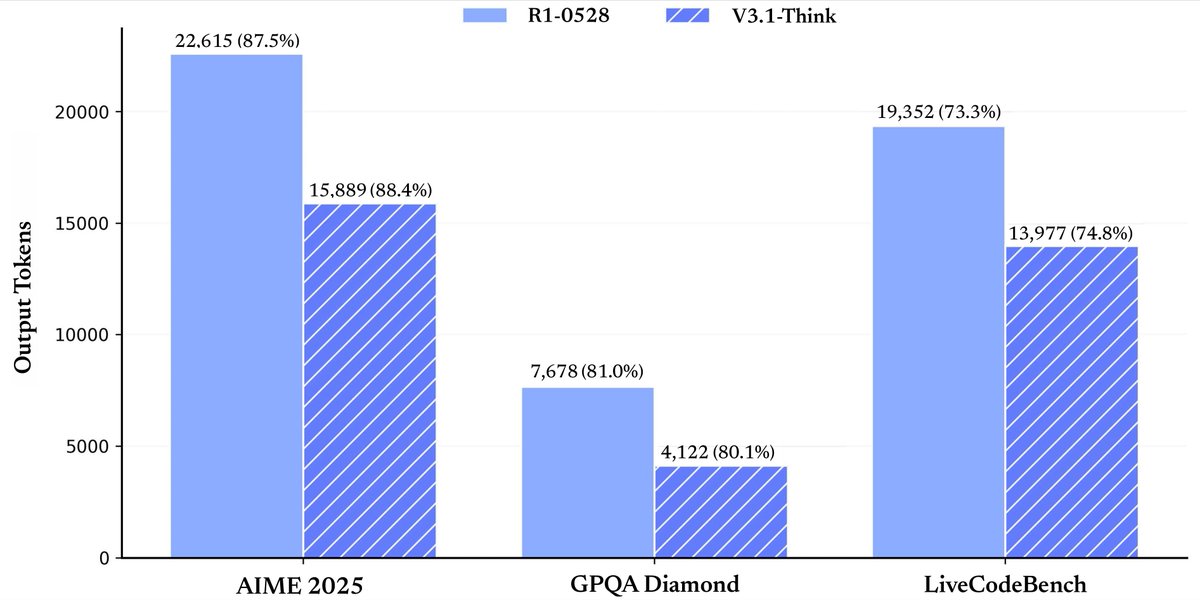
Tools & Agents Upgrades 🧰. 📈 Better results on SWE / Terminal-Bench.🔍 Stronger multi-step reasoning for complex search tasks.⚡️ Big gains in thinking efficiency. 3/5
0
1
5
RT @tuvllms: Excited to share that our paper on efficient model development has been accepted to #EMNLP2025 Main conference @emnlpmeeting.….
0
9
0
RT @basvanopheusden: A few weeks ago, I started a new job at @OpenAI. I wrote a document about my interview process and recommendations for….

docs.google.com
AI research interviews Bas van Opheusden, A few weeks ago, I started a new job at OpenAI. This document describes my interview process, lessons learned and advice for you. If you’re reading this, I...
0
355
0
RT @SherylHsu02: 1/n I’m thrilled to share that our @OpenAI reasoning system scored high enough to achieve gold 🥇🥇 in one of the world’s to….
0
284
0
RT @ii_posts: Most search models need the cloud. II-Search-4B doesn’t. 4B model tuned for reasoning with search tools, built for local us….
0
117
0
🥳Congrats @ii_posts for an impressive result on SEAL-0, a challenging benchmark for search-augmented LLMs. 🤩Looking forward to the evaluation standards it shapes in this field. 📚Read more:

arxiv.org
We introduce SealQA, a new challenge benchmark for evaluating SEarch-Augmented Language models on fact-seeking questions where web search yields conflicting, noisy, or unhelpful results. SealQA...


0
0
6
RT @PeterDiamandis: . @EMostaque came back on the show to chat about: . --how we can't compete against AI agents. --his solution for a POSI….
0
74
0
RT @j_dekoninck: We just released the evaluation of LLMs on the 2025 IMO on MathArena! Gemini scores best, but is still unlikely to achieve….
0
40
0
RT @sukjun_hwang: Tokenization has been the final barrier to truly end-to-end language models. We developed the H-Net: a hierarchical netw….
0
741
0
🔥 SEAL-0 Leaderboard 📈. Our results on SEAL-0 show a large room for improvement in LLMs' ability to reason over conflicting evidence. 🤯. 👉Checkout our paper: 👉Dataset:
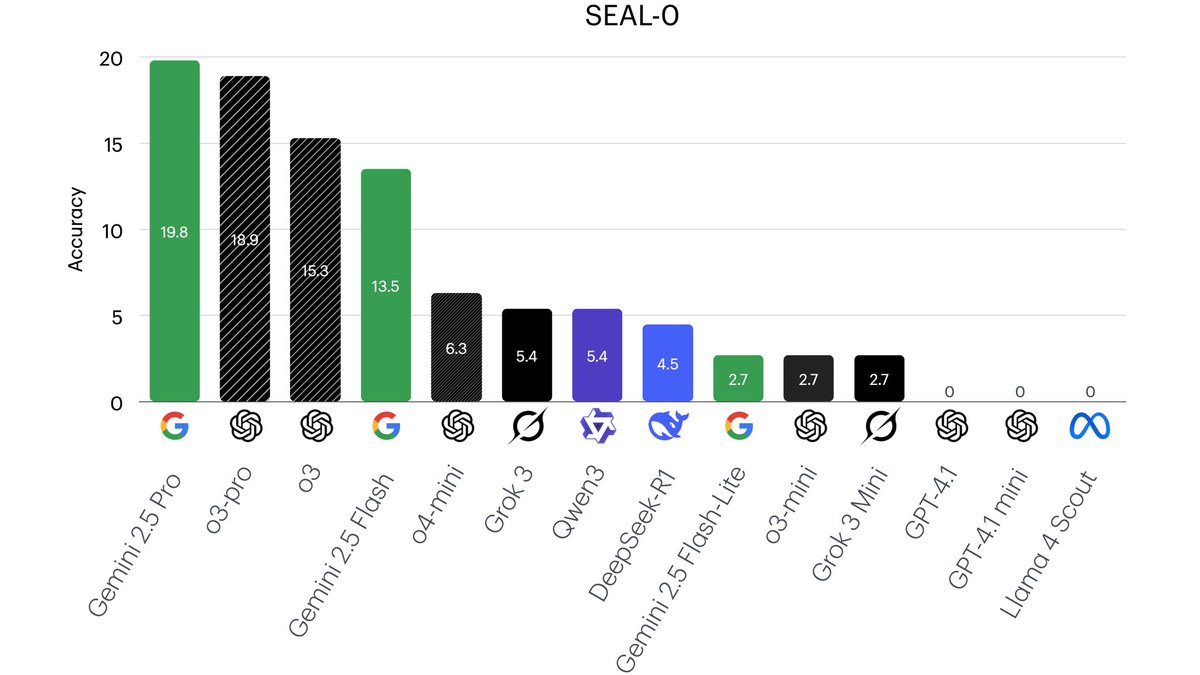
0
5
13
My first work done during my PhD 🥳🥳🥳.

✨ New paper ✨.🚨 Scaling test-time compute can lead to inverse or flattened scaling!!. We introduce SealQA, a new challenge benchmark w/ questions that trigger conflicting, ambiguous, or unhelpful web search results. Key takeaways:. ➡️ Frontier LLMs struggle on Seal-0 (SealQA’s


3
1
21
RT @tuvllms: ✨ New paper ✨.🚨 Scaling test-time compute can lead to inverse or flattened scaling!!. We introduce SealQA, a new challenge ben….
0
38
0