emi
@technoabsurdist
Followers
799
Following
10K
Media
43
Statuses
2K
we built herdora because writing cuda sucks and hiring gpu engineers is impossible. we turn slow pytorch into fast gpu code. automatically. please reach out emilio [at] herdora [dot] com if you want faster/cheaper inference .

Herdora (@herdora_ai) is the Cursor for CUDA. It automatically turns your PyTorch code into optimized GPU kernels so you don't have to write CUDA. Congrats on the launch, @technoabsurdist & @gpusteve!.
3
3
25
RT @finbarrtimbers: Someone’s gonna release an actual “RL for kernel development” paper without measurement errors at some point and no one….
0
2
0
RT @tryfondo: 🚀 @herdora_ai launched! Cursor for CUDA. "Herdora turns your slow PyTorch into fast GPU code, automatically.". 🌐 https://t.co….

tryfondo.com
👑 Herdora Launches: Cursor for CUDA
0
2
0
sometimes I accidentally run chat without agent mode and get scared by the horrible results. how do people live like that.
0
0
4
RT @gpusteve: 📜 ai doesn't run on just NVIDIA anymore - it’s running on many different chips, each with different quirks, tradeoffs, and sc….
0
2
0
RT @ycombinator: Herdora (@herdora_ai) is the Cursor for CUDA. It automatically turns your PyTorch code into optimized GPU kernels so you d….
0
15
0
RT @kenbwork: Reminds me a lot of the recent wave of (very successful) systems companies that rewrote popular frameworks like Kafka to take….
0
2
0
what's next at @herdora_ai: deeper kernel optimizations, advanced quantization techniques, and improved memory management. our ultimate goal: build the best hardware-agnostic tools for programming accelerators. break CUDA's software moat to lower industry costs, accelerate.
0
0
2
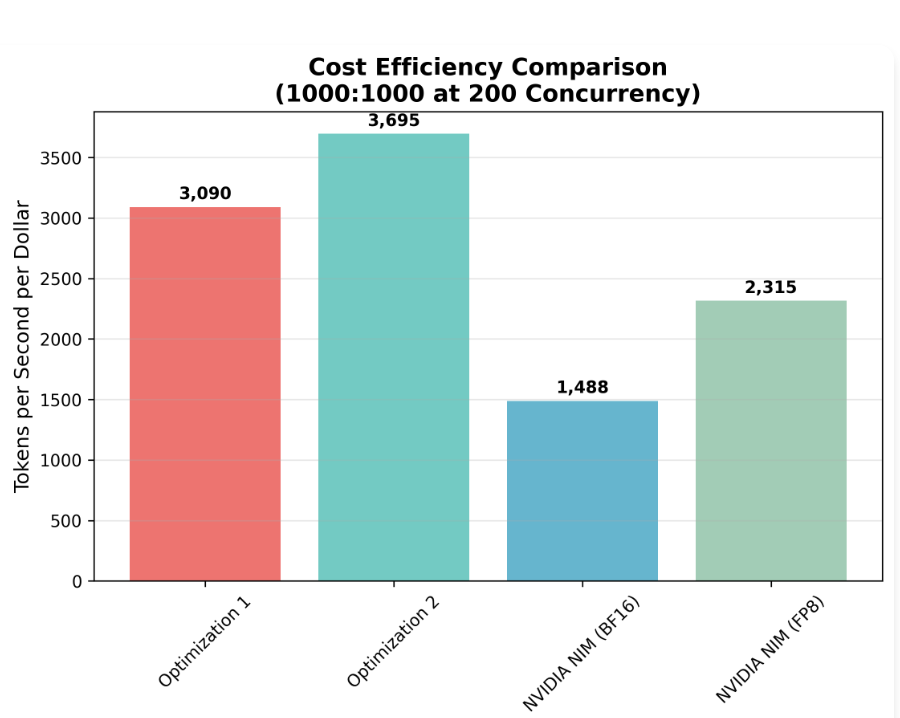
initial results:.• amd mi300x: 7,353 tokens/sec @ $1.99/hr → 3,695 tokens/dollar.• nvidia h100: 11,553 tokens/sec @ $4.99/hr → 2,315 tokens/dollar.
1
0
2
our first steps:.• custom mi300x-specific kernels for critical ops (attention, gemm).• optimized gpu execution with hip graph to slash latency and cpu bottlenecks.• introduced fp8 quantization, achieving high speed without significant accuracy loss (<2% drop on gsm8k dataset).
1
0
2
🦙 we optimize llama3.1-8b on an mi300x and show that after fp8 + custom-kernel tuning, it cranks out ≈ 7.3 k tok/s at 3.7 k tokens per dollar, beating H100 fp8 on cost-efficiency by 60%.
1
0
2
the challenge: amd’s software ecosystem (rocm) lacks the maturity of nvidia’s cuda. great hardware stays underutilized without strong software support. we're tackling exactly this gap. (3/6).
1
0
2
large language models are powering everything from chatbots to fully agentic systems. yet, almost everyone still defaults to nvidia gpus. the mi300x quietly stands out with 192gb hbm3 memory (over double h100’s 80gb) and 5.3tb/s bandwidth. (2/6).
1
0
2
📜 new blog post: amd’s mi300x gpu has huge potential for affordable, high-throughput llm inference - but it's currently underused due to software limitations. our initial optimizations already make it ~60% more cost-effective than nvidia's h100! (1/6). (🔗 links in final post).
2
2
15
RT @tenderizzation: “let’s see what happens if I bump the project to the next major CUDA release”
0
7
0