

steve
@gpusteve
Followers
219
Following
186
Media
77
Statuses
220
@herdora_ai (yc s25) | ml systems, chips, backflip doer | prev @ hedge fund | maintaining https://t.co/8IStIHPijG
sf
Joined May 2025
what is the standard amount of time to wait on a video call when someone's late w/ no notice.
3
0
4

how i feel after someone responds to my cold email (my response rate is 0.0001%)

0
0
4
Imagine if GANs had twitter. They’d be like “@discriminator is this true?”.

Imagine if memory pointers had twitter. They’d be like “@malloc is this true?”.
1
0
4
RT @tryfondo: 🚀 @herdora_ai launched! Cursor for CUDA. "Herdora turns your slow PyTorch into fast GPU code, automatically.". 🌐 https://t.co….

tryfondo.com
👑 Herdora Launches: Cursor for CUDA
0
2
0
want to follow along as we enter a new world of heterogenous compute. join us here:
0
0
1
we’re open to feedback, ideas, and collaboration - if you have thoughts on how we can make this more useful or expand it in the right direction, we’d genuinely love to hear from you.
1
0
1
this site serves as a live, open-source scoreboard for modern accelerators - showing how performance scales under real llm workloads.
1
0
0
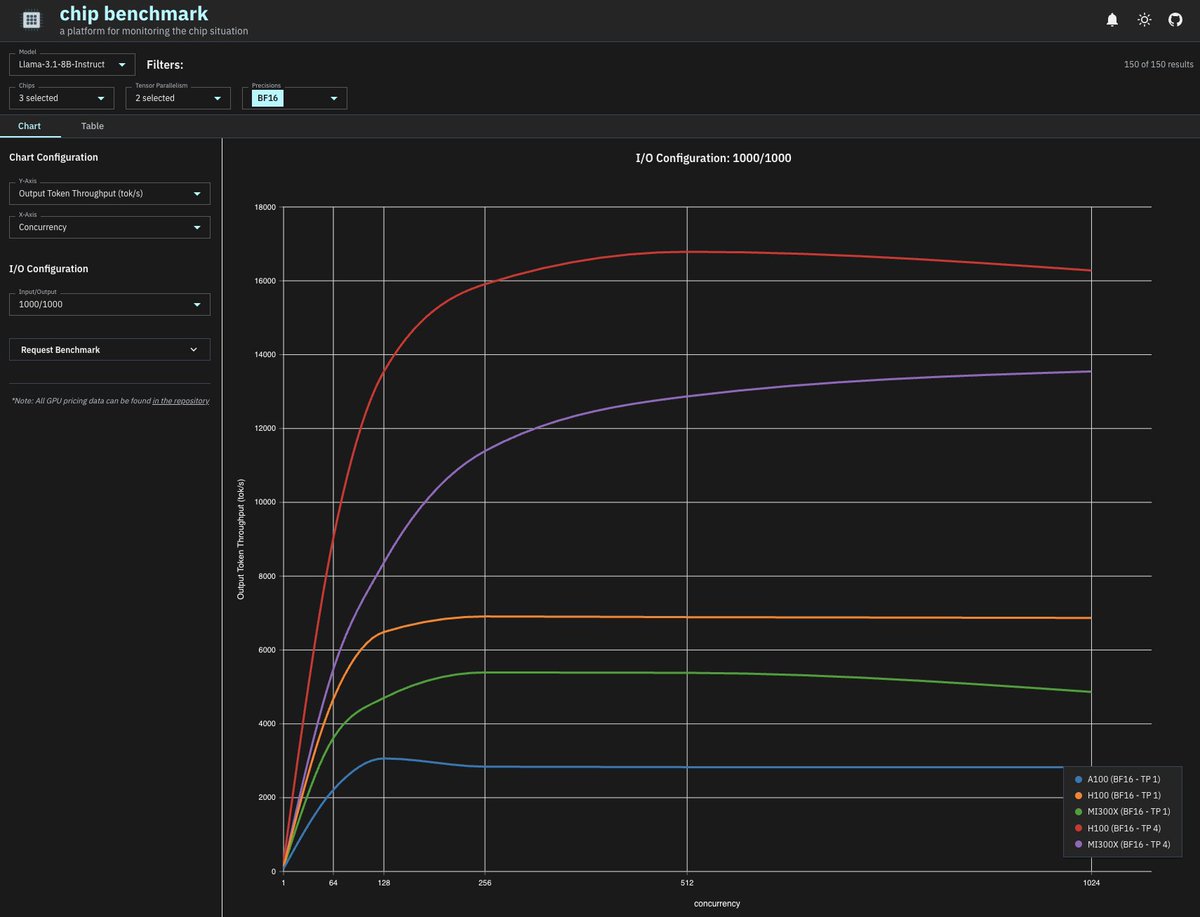
see here, as amd's mi300x surpasses nvidia's h100 in output tok/s running llama 4 scout!

1
0
1
the platform includes metrics such as throughput, latency, and performance/$. we look to add much more in the future.
1
0
1
we wanted to answer questions like: how fast does llama run on an H100 vs. an MI300X? And how does throughput scale across different workloads?.
1
0
1
📜 ai doesn't run on just NVIDIA anymore - it’s running on many different chips, each with different quirks, tradeoffs, and scaling behavior. today we’re launching - a new open-source platform to monitor the ai hardware situation.
3
2
17
looking forward to exciting times.

Herdora (@herdora_ai) is the Cursor for CUDA. It automatically turns your PyTorch code into optimized GPU kernels so you don't have to write CUDA. Congrats on the launch, @technoabsurdist & @gpusteve!.
0
2
13
