
Hongyao Tang
@tanghyyy
Followers
61
Following
28
Media
14
Statuses
27
Associate Research Fellow at @TJU1895. Postdoc at @Mila_Quebec and REAL @MontrealRobots working with @GlenBerseth. Working on RL, Continual Learning.
Joined November 2021
RT @johanobandoc: Thank you all for stopping by our poster session at ICML! Due to visa issues, @tanghyyy couldn’t join us in person; howev….
0
4
0
(7/8) 💪 ReMix is also more resilient to.- 1️⃣constrained maximum response length,.- 2️⃣prompt format variations (i.e., with and without guide tokens).

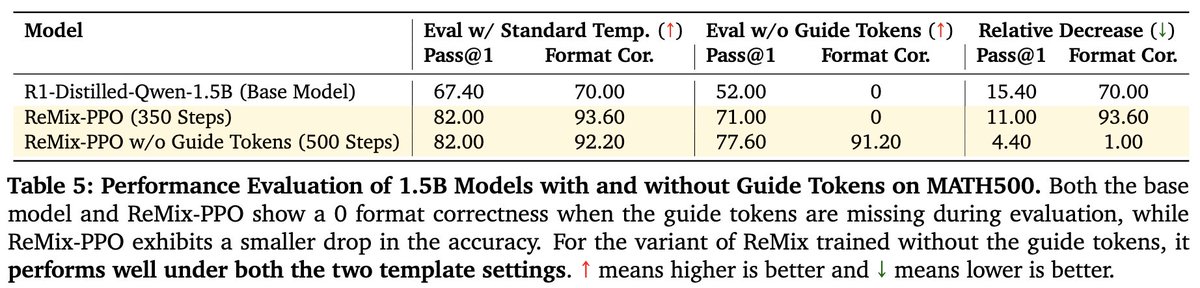
1
0
1
(6/8) 🔬How does Off-policy RL influence reasoning?. ⭐More off-policyness, quicker drop in reasoning length and reflection frequency, more prone to collapse.⭐ReMix exhibits a two-stage learning behavior of reasoning, that integrates the efficiency boost and steady improvement


1
0
0
(5/8) 🌟How does ReMix work?. Mix-PPG with an increased UTD boosts early-stage training significantly, while policy reincarnation plays a critical role in ensuring asymptotic improvement.
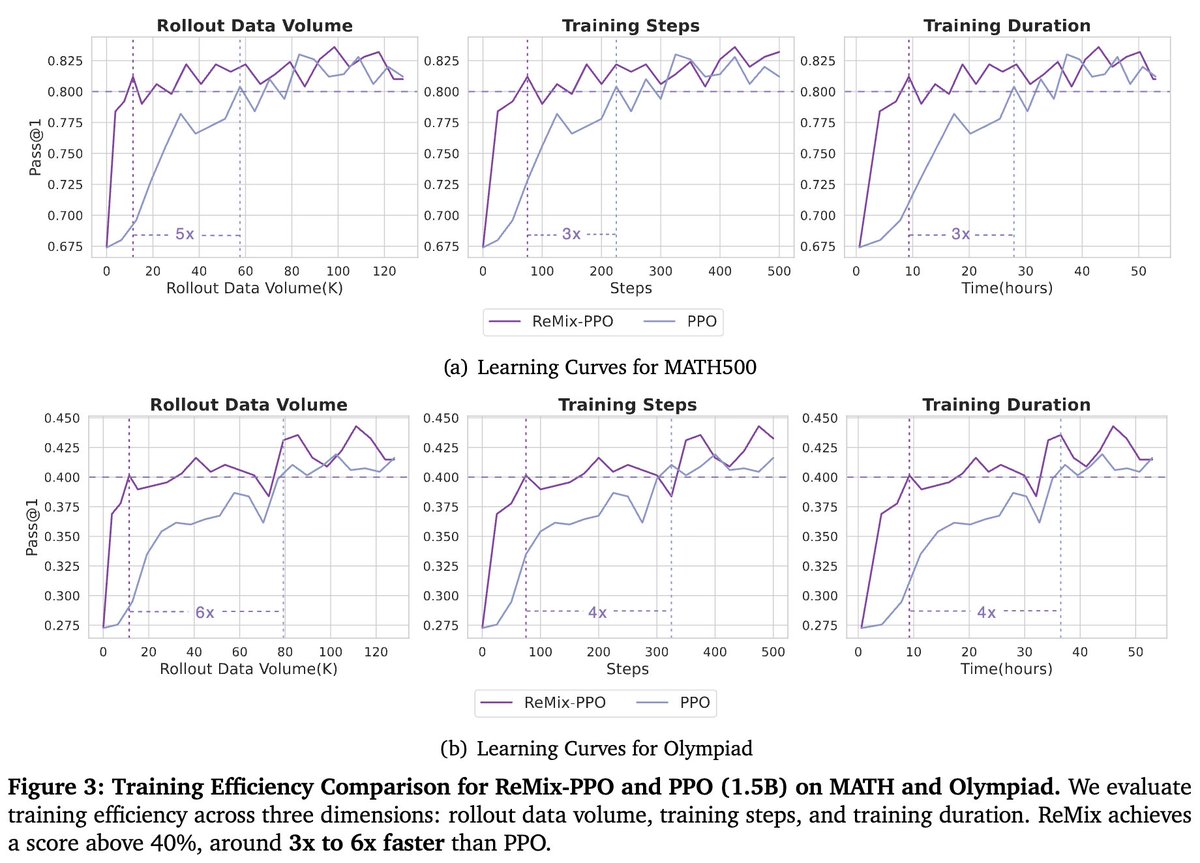

1
0
0
(4/8) 🧪We train ReMix based on PPO/GRPO and DeepSeek-R1-Distill 1.5B/7B (as base model), with DeepScaleR-Preview-Dataset. 📊ReMix achieves a significant reduction in rollout data volume, when matching/exceeding the performance of 15 recent models on 5 math reasoning tasks.
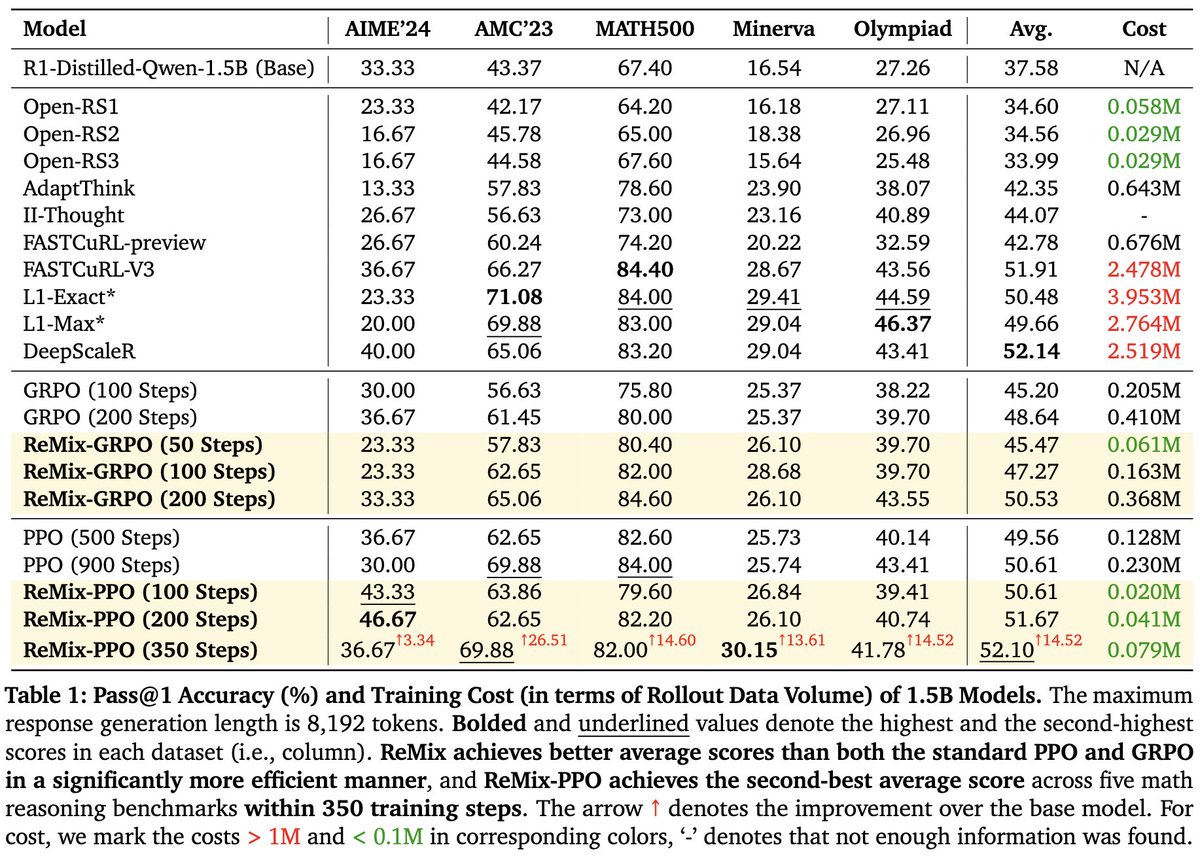
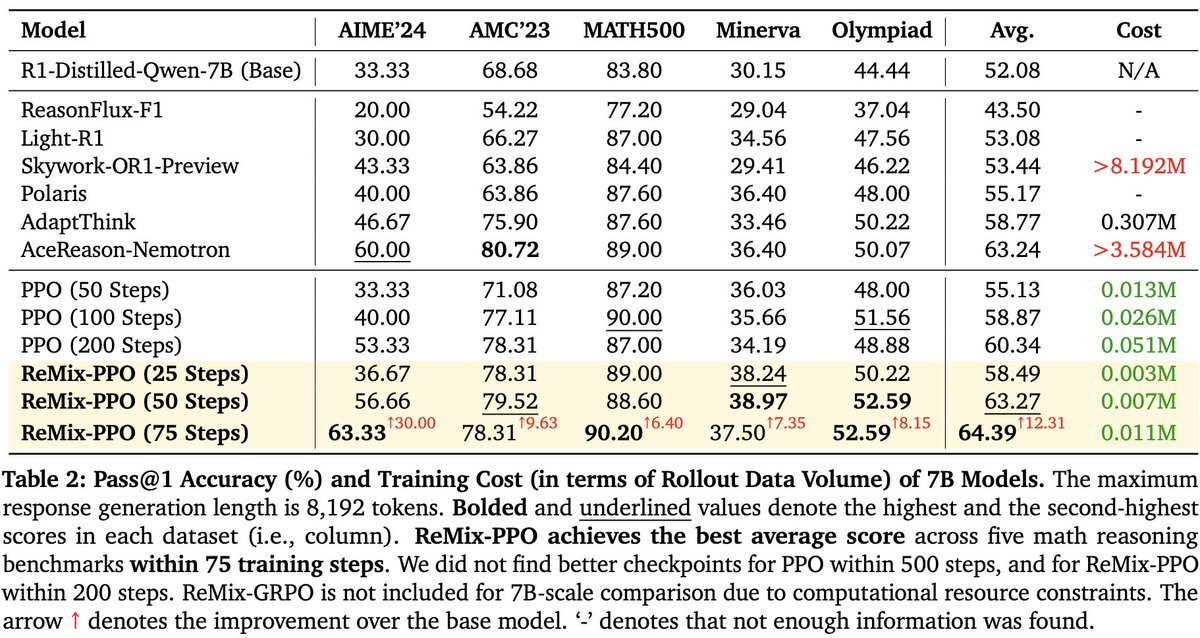
1
0
1
(3/8) 🧠 What is the recipe for ReMix?.- 1️⃣Mixed PPG = 60% PPO + 40% Generalized PPO (Queeney et al., 2021).- 2️⃣A higher UTD ratio.- 3️⃣KL-Convex constraint.- 4️⃣Policy Reincarnation (Agarwal et al., 2022).1️⃣2️⃣ for early efficiency boost, 3️⃣4️⃣for steady asymptotic improvement.


1
0
1
(2/8) 💡We propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix). 📊ReMix achieves competitive scores on five math reasoning benchmarks (i.e., AIME’24, AMC’23, Minerva, OlympiadBench, and MATH500), while showing a 30x to 450x reduction ↘️ in terms of rollout data.

1
0
1
(1/8) ⚡️Glad to share our paper “Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for LLM”! #LLMs. LLM RFT is expensive. Popular methods are on-policy in nature, thus being data inefficient. Off-policy RL is a natural and intriguing choice. 👇🧵

2
1
2
RT @GlenBerseth: Being unable to scale #DeepRL to solve diverse, complex tasks with large distribution changes has been holding back the #R….
0
10
0
(8/8) C-CHAIN is simple, effective, and plug-and-play for any RL agent. 📘 Paper: This work was a fantastic collaboration with @johanobandoc, @AaronCourville, @pcastr and @GlenBerseth 🙌. #ICML2025 #RL #ContinualLearning #DeepRL.

arxiv.org
Plasticity, or the ability of an agent to adapt to new tasks, environments, or distributions, is crucial for continual learning. In this paper, we study the loss of plasticity in deep continual RL...
0
0
1
(7/8)🔬 Why does it work?.Reducing churn gives:.1️⃣ Gradient decorrelation (suppresses NTK off-diagonal mass).2️⃣ Adaptive gradient scaling (step-size adjustment from reference batch).Both help maintain learning capacity under distribution shift.

2
0
1
(6/8)📊 It’s not just reward. C-CHAIN maintains gradient diversity and NTK rank during training. Without churn control, networks drift into low-rank regions. With C-CHAIN, they stay stable and plastic.
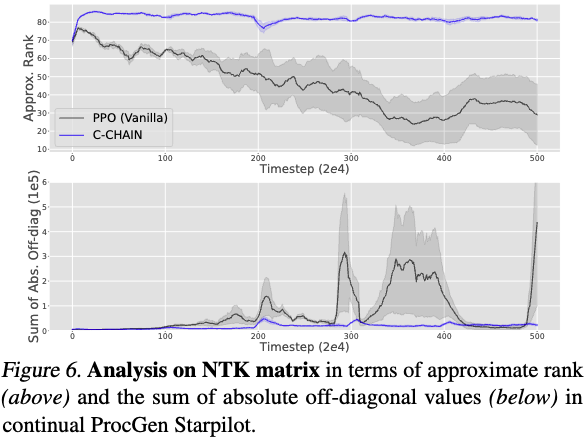

1
0
1
(5/8)📊C-CHAIN improves performance across 24 continual RL environments:.🎮 Gym Control, ProcGen, DeepMind Control Suite, MinAtar. It beats TRAC, L2 Init, Weight Clipping, LayerNorm, and AdamRel in most cases. ❤️Acknowledgement to the public code of TRAC



⭐New Paper Alert ⭐.How can your #RL agent quickly adapt to new distribution shifts ? And without ANY tuning?🤔. We suggest you get on the Fast TRAC🏎️💨, our new Parameter-free Optimizer that surprisingly works. Why?. Website:1/🧵
1
0
1
(4/8)💡 Our idea: if churn drives plasticity loss, then reducing churn should preserve it. 🎯 C-CHAIN: a lightweight regularization that penalizes churn during training, no task IDs, no extra memory, no replays.

1
0
2
(3/8)🧠 What is plasticity loss?.Over time, RL agents lose the ability to learn new tasks. Their networks overfit early, gradients become correlated, the rank of NTK matrix collapses, and learning stagnates. 👿It’s a silent killer in continual RL and churn is a key culprit.


1
0
2
(2/8)⚡️Churn = out-of-batch prediction drift caused by mini-batch updates (Schaul et al., 2022; Tang and Berseth, 2024). It creates instability and acts like silent interference especially under non-stationarity.

1
0
2
(1/8)🔥Excited to share that our paper “Mitigating Plasticity Loss in Continual Reinforcement Learning by Reducing Churn” has been accepted to #ICML2025!🎉. RL agents struggle to adapt in continual learning. Why? We trace the problem to something subtle: churn. 👇🧵@Mila_Quebec


1
13
53
RT @FanJiajun67938: 🔥 AI Model Can Self-evolve Without Collapse 🔥.Our ICLR 2025 paper introduces ORW-CFM-W2: the first theoretically sound….
0
10
0
A super great experience working with Prof. @GlenBerseth !.

This work has been a huge effort by @tanghyyy. Link to the paper: Improving Deep Reinforcement Learning by Reducing the Chain Effect of Value and Policy Churn.Paper:
0
0
3