
Vighnesh Subramaniam
@su1001v
Followers
72
Following
62
Media
4
Statuses
15
PhD student @ MIT EECS + @MIT_CSAIL https://t.co/UDgL88atg9
Joined January 2024
New paper💡!. Certain networks can't perform certain tasks due to lacking the right prior 😢. Can we make these untrainable networks trainable 🤔? We can, by introducing the prior through representational alignment with a trainable network! This approach is called guidance. (1/8)

1
3
8
Check out our new #ICLR2025 oral paper! Congrats to the team and in particular, to the first authors, @czlwang and @GeelingC!.

🎉Excited to share: My first ML conference paper, Population Transformer 🧠, is an Oral at #ICLR2025! This work has truly evolved since its first appearance as a workshop paper last year. So thankful to have worked with the best advisors + collaborators! 🤗 More soon!.
1
0
5
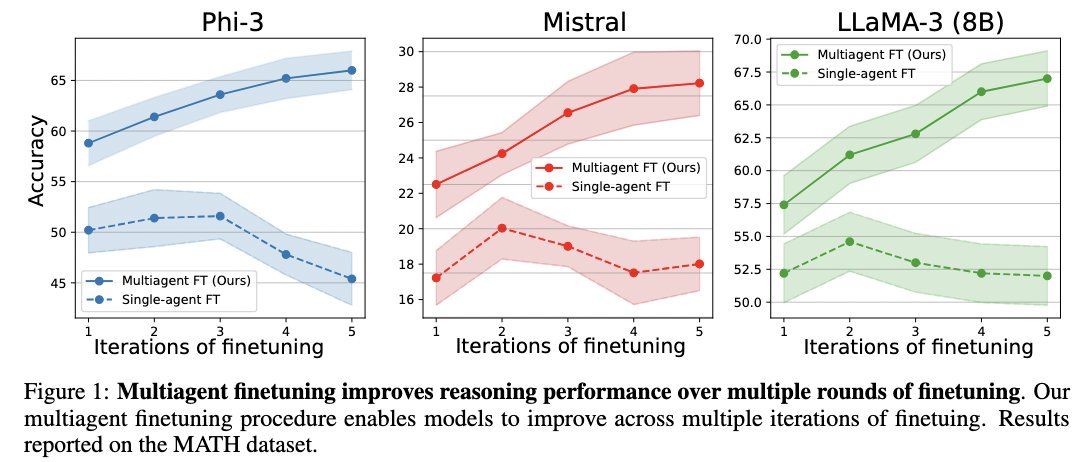
Check out our new work for self-improvement of LLMs! . This work uses a multi-agent set up that not only improves performance but preserves diversity over iterations of finetuning. Website: Paper:

arxiv.org
Large language models (LLMs) have achieved remarkable performance in recent years but are fundamentally limited by the underlying training data. To improve models beyond the training data, recent...

Introducing multi-agent self-improvement with LLMs!. Instead of self improving a single LLM, we self-improve a population of LLMs initialized from a base model. This enables consistent self-improvement over multiple rounds.
0
0
7
RT @_abarbu_: Interested in large-scale neuroscience of language and multimodal representations? We have the dataset for you, the Brain Tre….
arxiv.org
We create a reusable Transformer, BrainBERT, for intracranial recordings bringing modern representation learning approaches to neuroscience. Much like in NLP and speech recognition, this...
0
2
0
Work done with amazing collaborators @DavidMa53462349, Colin Conwell, Tommy Poggio, Boris Katz, @thisismyhat, and @_abarbu_. Paper: Website: Code: (8/8).
0
0
0
We cover tons of other experiments and settings in the paper such as stopping guidance early and analyzing error consistency of guided networks in the paper. We hope guidance can be a general tool for improving and understanding neural network design😀! (7/8).
1
0
0
Most excitingly, we improve RNN performance on the copy-paste task which requires extensive memorization. We also make vanilla RNNs competitive with transformers on language modeling 🎉! (6/8).
1
0
1
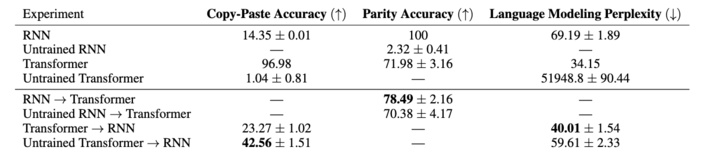
Furthermore, we extend guidance to sequence modeling with RNNs and transformers. We guide transformers using RNNs for the parity task — a traditionally difficult task for transformers and see significant improvement. (5/8)
1
0
0
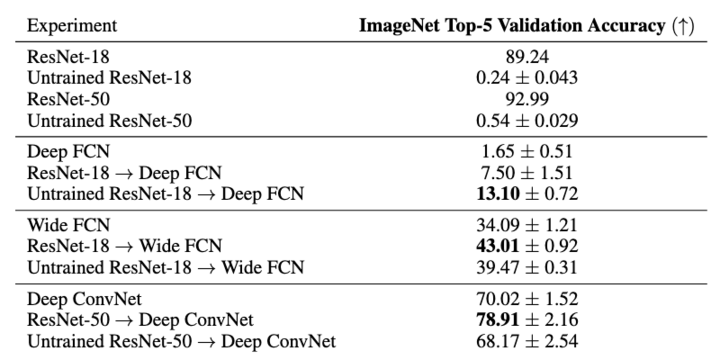
We consider guidance over other guide network/target network pairs for image classification and surprisingly find that aligning with an untrained guide network can have 𝐛𝐞𝐭𝐭𝐞𝐫 𝐫𝐞𝐬𝐮𝐥𝐭𝐬😯. (4/8)
1
0
0
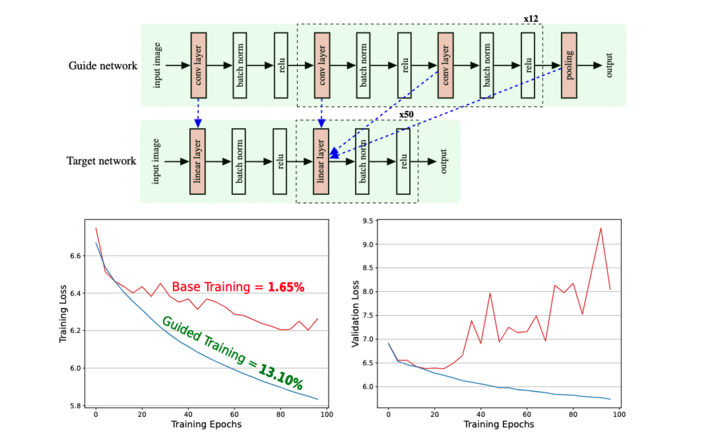
By using a layerwise representational alignment with a guide network, ResNet-18, during training, we're able to prevent overfitting and improve network performance significantly as shown by the green training curve. (3/8).
1
0
0
Below, we consider a fully connected network (FCN) trained on ImageNet. FCNs have a tendency to overfit on the task as seen by the red line which has an increasingly larger validation loss across training. (2/8)
1
0
0
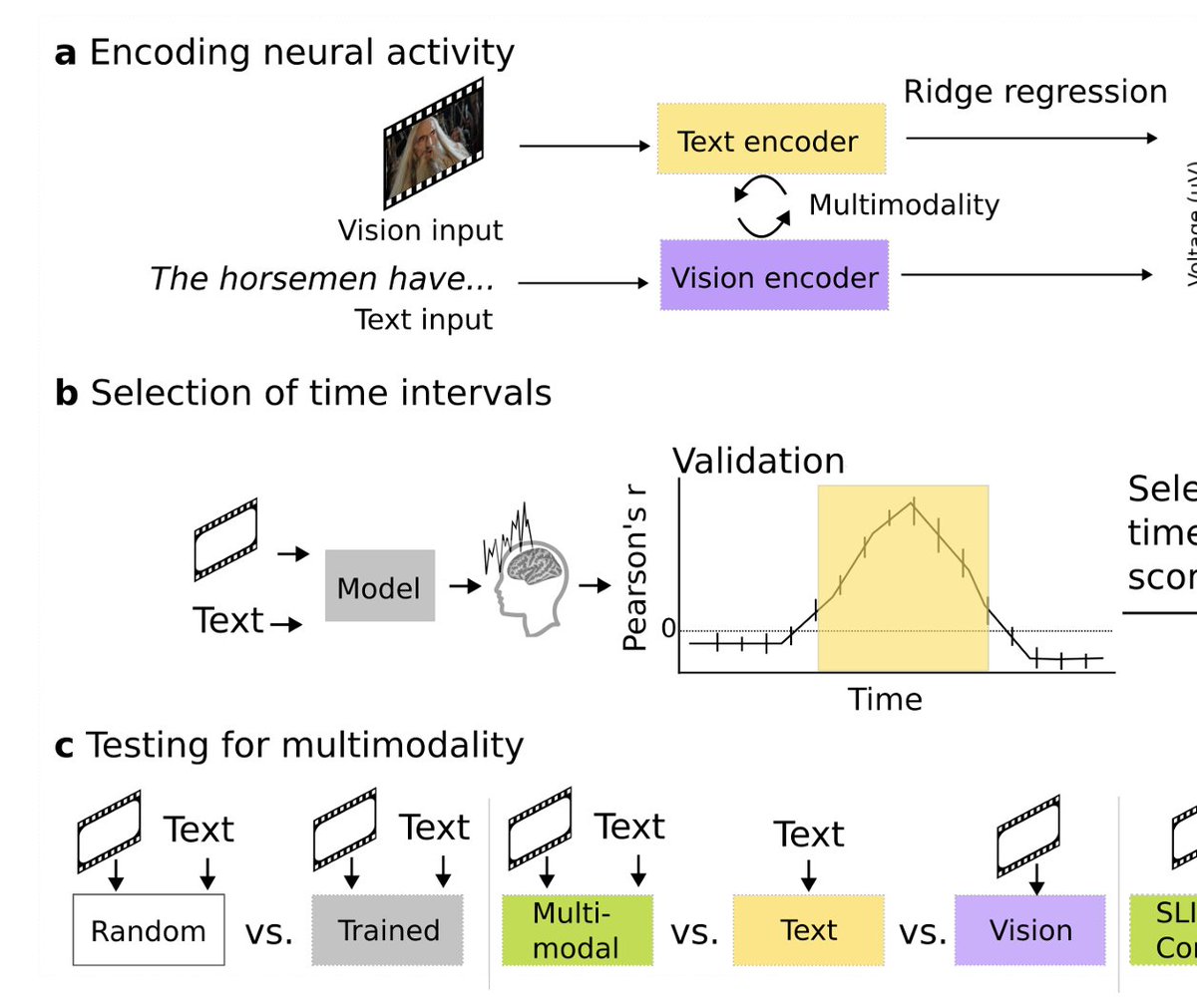
Check out our new paper on localizing and characterizing vision-language integration in the brain, now in ICML 2024!. Paper: Project Page: Dataset: Code:
github.com
Contribute to vsubramaniam851/brain-multimodal development by creating an account on GitHub.

Revealing Vision-Language Integration in the Brain with Multimodal Networks. Subramaniam et al, ICML 2024. Download the article here:
0
0
1