

Stephan Hoyer
@shoyer
Followers
8K
Following
5K
Media
73
Statuses
3K
Find me on BlueSky: https://t.co/k9tBZ18kXO
San Francisco, CA
Joined August 2009
RT @xarray_dev: Check out our new API for seasonal aggreggations, including support for custom seasons!. `ds.resample(time=SeasonResampler(….
xarray.dev
Introducing new SeasonalGrouper and SeasonResampler objects
0
7
0
RT @juliangreensf: "What's the Future of AI Weather Forecasting?" - Video of #SFClimateWeek Panel with @shoyer of @Google , Karthik Kashina….
0
4
0
As someone who is both an AI and climate expert, let me point out that AI and climate risk have many qualitative differences. To start, there is much higher degree of concensus about climate change than about AGI.

There is a weird amount of overlap between the people who insist that we take climate experts seriously when they warn of big changes on the horizon, and people who refuse to take AI experts seriously when they say the same thing.
2
1
28
RT @TEGNicholasCode: At AGU I talked to NASA people about how agencies could better support open-source tools they rely on. I argued that o….

xarray.dev
The new xarray.DataTree class allows working with netCDF/Zarr groups, brought to you in collaboration with NASA!
0
4
0
Twitter was fun, but I think I'm done. X has too much clickbait and not enough science. Pretty exciting to see how quickly my network is replicating itself over on the other app!.
1
0
25
xarray.DataTree is @xarray_dev's first major new data structure since it's initial release baxk in 2014!.

Xarray v2024.10.0 has just been released, including support for xarray.DataTree and zarr-python v3 !!!. @xarray_dev @zarr_dev.
1
3
51
This recording of this public talk on NeuralGCM is now available on Youtube:
I'm giving a public talk next week in downtown Palo Alto on "AI-based Weather and Climate Modeling with NeuralGCM.". Would love to see you there! It's the evening of Thursday Oct 3:
1
6
45
A nice summary of why I moved on from ML for PDEs. The literature on weather & climate modeling isn't perfect, but the baselines are certainly much more compelling and easier to find.

Our new paper in @NatMachIntell tells a story about how, and why, ML methods for solving PDEs do not work as well as advertised. We find that two reproducibility issues are widespread. As a result, we conclude that ML-for-PDE solving has reached overly optimistic conclusions.

6
14
204
I'm giving a public talk next week in downtown Palo Alto on "AI-based Weather and Climate Modeling with NeuralGCM.". Would love to see you there! It's the evening of Thursday Oct 3:

lu.ma
Modeling weather and climate changes is among the hardest challenges in the machine learning space. In this in-person event, Stephan Hoyer, a Senior Staff…
1
4
51
RT @SethAbramson: COMMUNITY NOTE: Humans are unlikely to step foot on Mars until the 2040s/2050s at the earliest, and there’ll never be a s….
0
298
0
RT @cherian_deepak: At long last Xarray can now group by multiple arrays. The culmination of 3 years of on/off work. .
0
32
0
Genuine question: What is the best evidence for the value of physics-based regional weather/climate modeling? . WRF certainly "looks" more realistic, but when is it actually consistently quantitatively superior to statistical post-processing of global models?.
15
4
37

somebody please integrate this into @xarray_dev pronto!.

By popular demand, the Treescope pretty-printer from the Penzai neural net library can now be installed separately, and supports both JAX and PyTorch!. And that's not all: Penzai itself now has less boilerplate and includes more pretrained Transformer models!
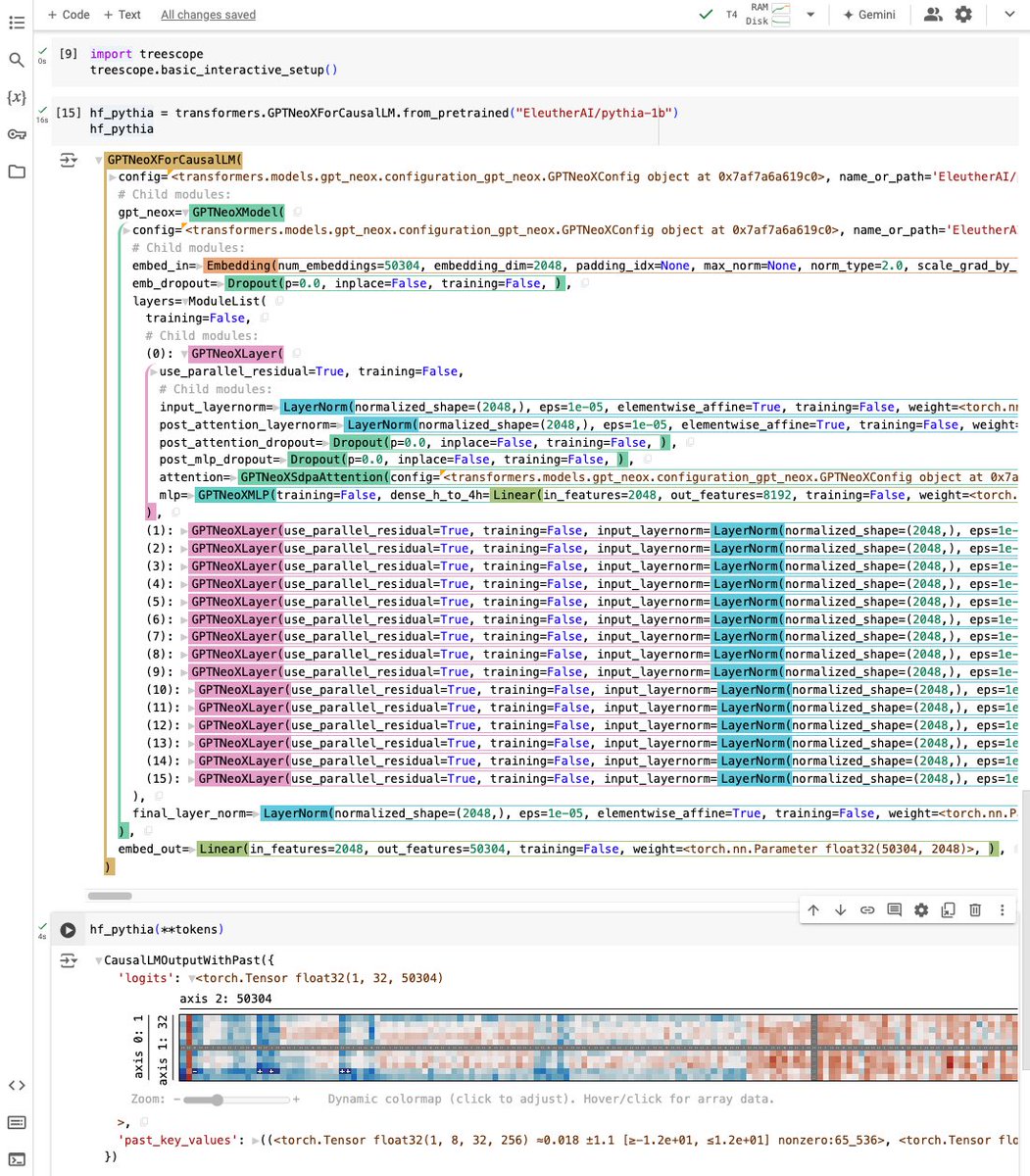

1
0
15
RT @raspstephan: NeuralGCM is the result of persistence and long-term vision from @shoyer and the team. 4 years ago I wrote a blog post on….
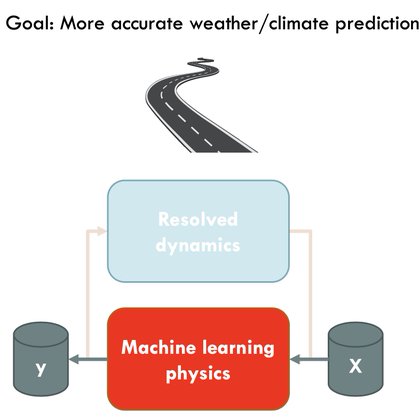
raspstephan.github.io
The argument goes like this: Climate models continue to have large uncertainties → these uncertainties are primarily caused by the parameterization of sub-grid clouds which are based on heuristic...
0
7
0
RT @janniyuval: New @nature paper: NeuralGCM results (all are a "first"):.1) A differentiable hybrid atmospheric m….
0
36
0
RT @sundarpichai: In @Nature today: NeuralGCM, a breakthrough in climate modeling. It combines physics-based modeling with AI, and is up to….
0
182
0
NeuralGCM was a huge team effort, and I would especially like to acknowledge the core team who has worked on the project over the past three years: @dkochkov1, @janniyuval, @langmore, @pnorgaard314, @singledispatch.
2
1
35
NeuralGCM is freely available, and we are excited to see how scientists build upon it. For more details, see my blog post describing the work, and our open source code:.
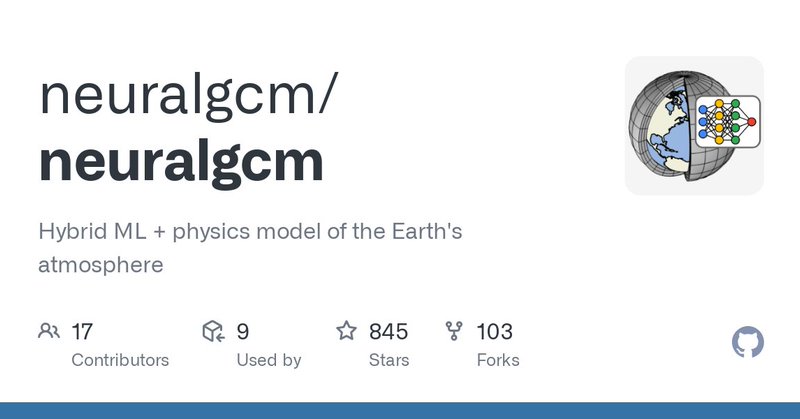
github.com
Hybrid ML + physics model of the Earth's atmosphere - neuralgcm/neuralgcm
1
2
59