
Shawn Jain (at NeurIPS ‘25)
@shawnjain08
Followers
181
Following
26
Media
3
Statuses
43
Co-Founder at Synthefy; Venture Partner at Lightscape; ex-OpenAI, MIT, MSR, Uber ATG
San Francisco, CA
Joined January 2011

Imagine asking: 📦 “Forecast delivery demand if I cut shipping fees in half this holiday season.” 🛋️ "Forecast my couch and tables, if I start promoting couches over tables this labor day" …and getting answers in minutes, not months. No messy data pipelines. No Model
lnkd.in
This link will take you to a page that’s not on LinkedIn
0
4
11
The future of forecasting is enriched. More signals. More context. Smarter models. Better foresight. 🔗 Full post: https://t.co/F6xKKXq0Xr Want to try out @synthefyinc? My DMs are open. 📩
medium.com
For decades, time series modeling was stuck in a narrow paradigm.
0
0
0
This isn’t just about a better model. It’s about a marriage of models and data. And that’s why we’re building a platform - not just an algorithm. One that connects to external data sources, enriches signals, and delivers results.
1
0
2
We’ve already seen this in action. A customer asked us to forecast demand for a core food product. Baseline RMSE: 0.24. After enriching with prices of related pantry goods? New RMSE: 0.21 More context → better signal → better forecast.
1
0
1
What is dataset enrichment? It’s the process of adding real-world, correlated signals to your time series data, like: - Weather - Macroeconomics - Traffic - Social trends - Event calendars This context fuels smarter models.
1
0
0
At Synthefy, we’re building forecasting systems that are: ✅ Multivariate ✅ Metadata-aware ✅ Context-conditioned But better models aren’t enough. They need better data to power them. Enter: dataset enrichment.
1
0
1
For decades, time series modeling was stuck in a narrow paradigm. Most models were univariate - looking at one signal in isolation. They ignored context because the models couldn’t handle it. @synthefyinc is changing that. 🧵
1
4
13
Generative AI ≠ just LLMs. The future isn’t one model for everything. It’s building the right model for the job. For time series, don’t bend your data to fit transformers. Use tools that fit the signal. Let Synthefy solve your time series. DM me if you want to try
0
0
2
Our models show SOTA results across: - Energy demand - Retail simulation - Medical time series (ECG, heart rate, PPG) They generate realistic, diverse futures - grounded in multimodal context. Synthefy models (top row, red) produce samples that match the ground truth
1
0
2
At @synthefyinc , we built something different: - A diffusion model designed for time series - A universal metadata encoder (text, tabular, categorical, continuous) - Native support for dense, noisy, real-world signals
1
1
2
Why? The issue is architectural. Transformers assume: - All data is tokenized text - Context = more tokens - The Input/output stream is sequential & discrete But time series needs: - Continuous and Real-Valued inputs - Multi-modal conditioning - High temporal
1
0
1
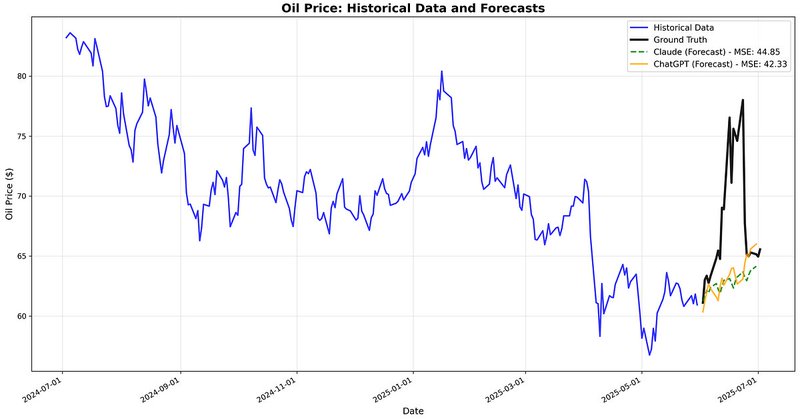
We ran a simple test: Forecast oil prices using ChatGPT & Claude. Result? Both missed major price spikes. They output smooth trends - completely missing the signal. Transformers are great at language. Not at real-world dynamics.
1
0
1
LLMs can’t solve time series. Here’s why: LLMs are powerful, general-purpose tools. But somewhere along the way, we started treating them as the answer to every problem. They’re not. And for time series modeling, they’re the wrong tool entirely. Let’s dig in 👇
6
3
13
LLMs are amazing at a lot of things - but time series forecasting isn’t one of them. In Synthefy's latest blog post, we explain why token-based architectures aren’t inherently designed for real-world time series tasks - like forecasting energy demand, retail trends, or medical
medium.com
Large Language Models (LLMs) have captured the imagination of the world. And for good reason — they’re powerful, flexible, and…
3
5
15
Time-Series is the most under-appreciated and under-researched modality in gen-ai, even though it comprises the large majority of data in the world. That's why I am co-founding @synthefyinc with @ShubhankarAgar3 and @SPChinchali We won 1st at the DT/T-Mo AI Challenge.
1
1
7

The surge in #OpenEndedness research on arXiv marks a burgeoning interest in the field! The ascent is largely propelled by the trailblazing contributions of visionaries like @kenneth0stanley, @jeffclune, and @joelbot3000, whose work continues to pave new pathways.
3
18
115
Touches on open-endedness, evolutionary computation, genetic programming, and deep learning. Excited to see what others build on this! 4/4
2
4
56
Synergy between evolutionary algorithms and language models: EAs can leverage LMs to generate data in novel domain, and thereby improve LM — bootstrapping it into competence in that domain (here evolving locomoting 2D virtual creatures). 3/4
1
9
80
What I've been working on at OpenAI!

ELM done with an amazing team: @kenneth0stanley @GordonJo76 @darkmatter08 @kandouss & Cathy Yeh. [video shows an evolutionary lineage from an initial barely-functional seed program to a final solution -- best in full-screen] 2/4
0
0
3
“Evolution through Large Models” – new paper from our team at OpenAI. Step towards evolutionary algos that continually invent and improve at inventing: Large models can suggest (+ improve at making) meaningful mutations to code. Paper: https://t.co/ObrAN6rBVE 1/4
30
455
3K