

Sean J. Taylor
@seanjtaylor
Followers
46,192
Following
4,240
Media
971
Statuses
18,982
Building @MotifAnalytics . Formerly @Lyft and @Facebook . Keywords: Experiments, Causal Inference, Statistics, Machine Learning, Economics.
Oakland, CA
Joined February 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Petro
• 503175 Tweets
Dortmund
• 212995 Tweets
Sancho
• 169539 Tweets
Boulos
• 117088 Tweets
Paco Villa
• 69498 Tweets
Rio Grande do Sul
• 65342 Tweets
Gabigol
• 52691 Tweets
Canelo
• 36285 Tweets
COMPLOT CONTRA LOS BROS
• 32600 Tweets
Kolo Muani
• 25361 Tweets
#AEWDynamite
• 22025 Tweets
Cacá
• 21766 Tweets
フジコ・ヘミングさん
• 21452 Tweets
Fortaleza
• 16269 Tweets
Carlos Miguel
• 14698 Tweets
Amazonas
• 14048 Tweets
Bidon
• 11473 Tweets




















Pinned Tweet

I was stoked to get some data from Bluesky and start to play around with it in
@MotifAnalytics
. Check it out and see how much you can do (from scratch!) in ten minutes, when you have the right abstractions for working with sequences.

8
8
73

I can’t understand how this can sound so ridiculous and yet be totally reasonable advice
Credit:
59
800
5K
Reading through the Wolfram announcement I had a startling realization about the nature of the universe.




90
518
4K
When I left Facebook, I had interviewed around 350 data scientists. I'm close to 100 interviews now at Lyft. I feel like I could write a book about what I've learned; what would be most interesting to read about? Do you think it's ethical to share themes and lessons learned?
163
79
3K
If you read a paper or blogpost and find it useful, a nice thing to do is write a quick email to the author and tell them. Writing long-form technical content is so much work and I think authors probably systematically underestimate how much value they create.
37
616
3K
When I'm showing someone my latest results by walking them through a Jupyter notebook.

16
351
2K
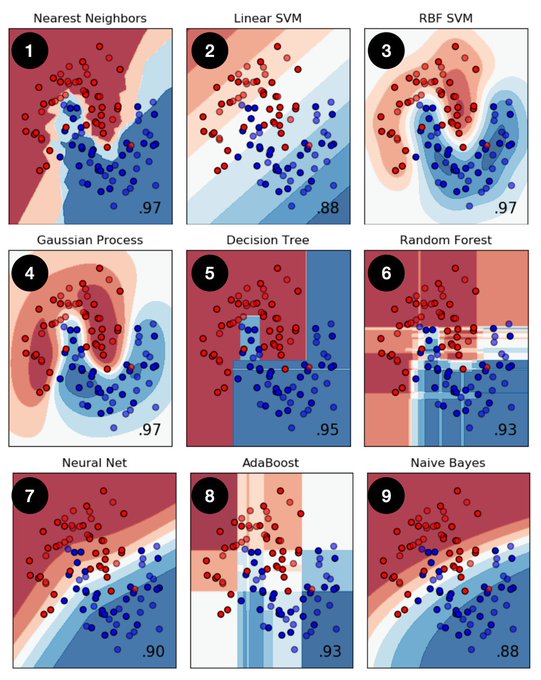
I love this graphic. Such a tidy way to think about it.
22
193
2K
Fool me once, shame on my prior.
Fool me twice, shame on my likelihood.
11
129
2K
One thing computers are really good at is telling you how many seconds have passed since January 1st, 1970.
25
86
1K
Almost every problem in my life can be traced to an unfounded optimism about how quickly I can get things done and how many things I can do at once.
17
99
1K
Perhaps my most controversial opinion: In machine learning education, the focus on supervised learning and particularly on classification problems gives people a totally misguided idea about how to use data to solve real problems.
39
148
1K
Some personal news: I'll be leaving my role at Facebook in two weeks. I can't say enough positive things about the company and my fantastic co-workers.
On 5/20, I'll start at Lyft as head of research science for the Decision Science Products team. Excited for the journey ahead!
84
29
1K
Two of the hardest things about cognitively demanding work are:
1) You can’t really make it go faster. There are tricks to getting unstuck but it usually proceeds very nonlinearly.
2) It often looks like it could have been done in a far shorter amount of time when it’s over.
23
137
1K
I often ask data scientists for examples of projects that went poorly or where they have regrets. The most common answer by far: agreeing to work on a question they didn't think could be well-answered with their data, then having the caveats/nuances ignored by decision makers.
30
228
1K
I'm as enthusiastic about the future of AI as (almost) anyone, but I would estimate I've created 1000X more value from careful manual analysis of a few high quality data sets than I have from all the fancy ML models I've trained combined.
19
328
1K
Another week, another re-read of
@karpathy
's timeless recipe for training neural networks, perhaps the article that's saved me the most time in aggregate.
9
165
1K
📈Long thread on how Prophet works📈
- Instead of sharing slides I'm transcribing my talk to tweets with lots of GIFs :)
- Thanks to
@_bletham_
for all his help.

24
335
1K
If I could more realistically estimate how long my projects were going to take I probably wouldn’t start any of them.
24
95
1K
My old data science team at Facebook would formally acknowledge a type of impact we called "preventing a doomed course of action." I love this phrase and the idea that you need to encouraging people to actually *stop* projects when there's too little upside or too much risk.
18
138
1K
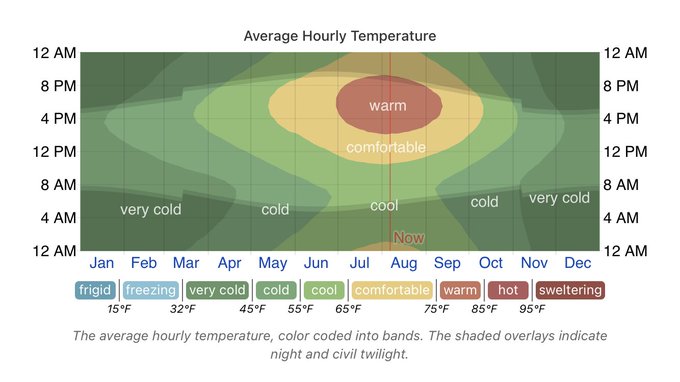
I recently got a copy of "W. E. B. Du Bois's Data Portraits: Visualizing Black America." Totally floored by the craft, artistry, and intention in this project. These plots were drawn in the *1890s* based on painstakingly collected data & told an important story we'd have missed.
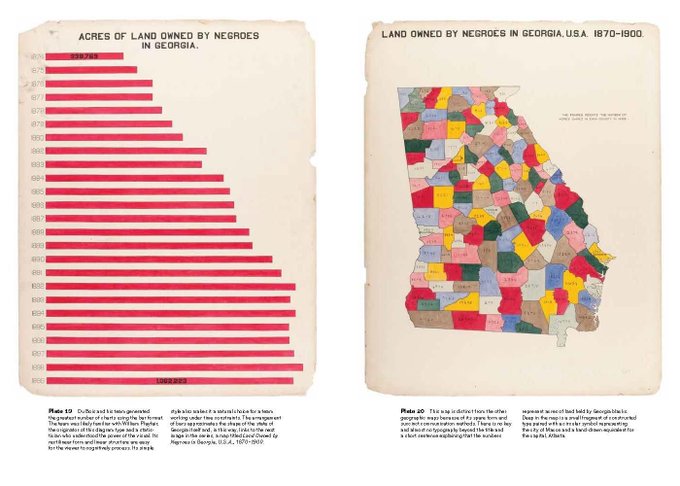
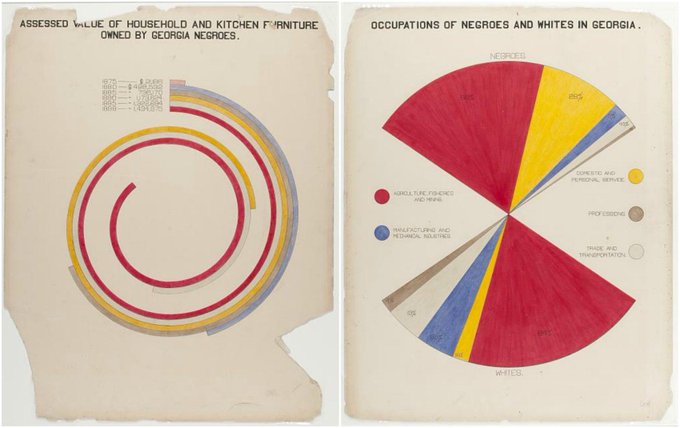
18
266
1K
I think this is an interesting topic but found this visualization hard to follow (no surprise if you've been reading my complaints about animated plots).
I have nothing to do tonight so i'm going to try to re-visualize this data. Starting a THREAD I'll keep updated as I go.

20
200
1K
Why I've transitioned from social science research to working on methods and tools:
Me: (presents social science research)
People: We disagree about the findings, interpretation, and importance.
Me: (builds and shares a tool)
People: Thanks, this is awesome and useful.
19
142
958
Probably the most productivity-improving thing you do can for a data science team is to create and maintain a strong, inclusive community of practice. If people on your team aren’t constantly learning from each other, you’re leaving a ton of value on the table.
10
241
957
Prophet is an open-source forecasting package implemented in both Python and R, used in production at Facebook:
17
318
906
If you want to question whether human-produced labels for training ML models represent "ground truth," look no further than the sheer volume of misclassifications in a pair of recycling/trash bins.
16
221
904
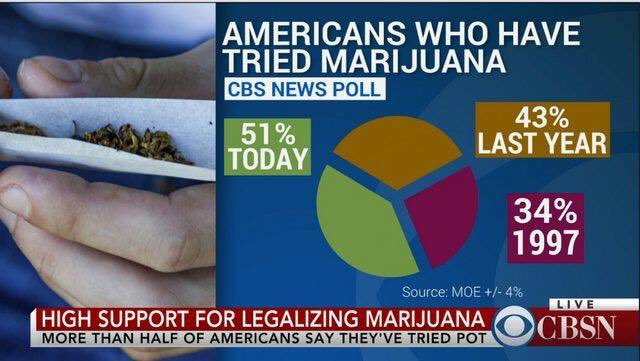
We fail to reject the null hypothesis that Taco Bell distributes sauce packets with equal probability (p = 0.947).

24
150
835
Imagine if every technical blog post started with a few paragraphs of inane personal anecdote and put the code in a small box at the very bottom.
29
41
850
One useful mental model for statistics: every bit of certainty you achieve has to either be earned with data or bought with assumptions, and you don’t often know how much the assumptions have cost you.
6
120
823
One stark difference between R and Python. If I'm looking for a good natural spline implementation:
R: I can directly import `splines` which Douglas Bates has been working on for 22 years.
Python: google/copy/paste some snippet from StackOverflow and pray that it's correct.
36
49
772
A couple days ago another team asked me to speak about Bayesian data analysis. I decided that instead of doing a nuts/bolts of how to fit/use Bayesian models, I would describe "Bayesian analysis: The Good Parts". <potentially controversial thread>
17
212
760
Often people say “I’m not good at X” when they really mean “I’m not good at tolerating the negative feelings I experienced when I was trying to learn X.” For me it’s learning languages. Being a beginner at stuff is frustrating, embarrassing, jealousy-inducing, and even hopeless.
11
64
765
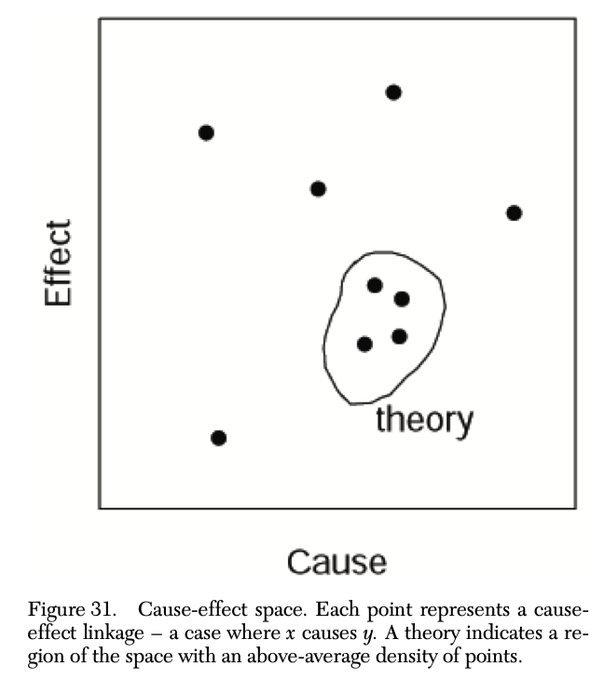
Imagine being an expert on causal inference and concluding from all available evidence that hundreds of smart people aren’t using your methods because they’re too stubborn and the policy implication is you need to tell them that on Twitter everyday.
20
66
748
One of the best parts about not being an academic is having a positive response to learning that someone’s already written about idea I just had, as opposed to being completely demoralized.
13
37
735
I've been reflecting a lot on why data science is so hard to do well. My current mental model: value is generated multiplicatively.
You must get each thing right or it's worth almost nothing:
- Formulate good questions
- Quality data
- Correct analysis
- Communicate findings
21
150
710
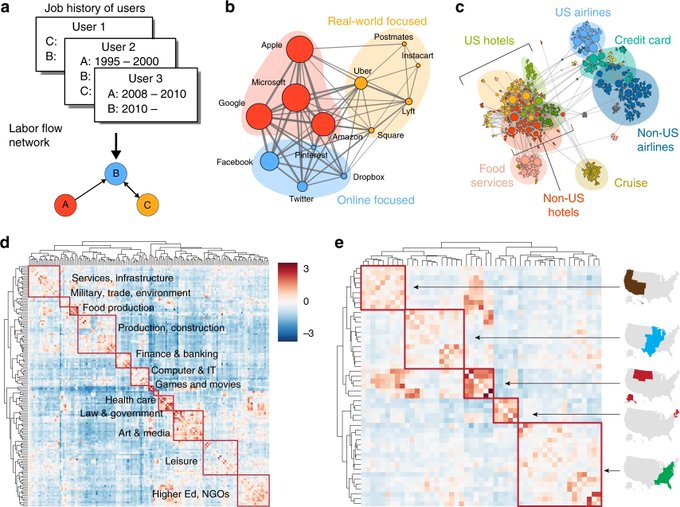
This new paper clustering the global labor network is really rad. It's cool how much structure pops out when you apply the right model. Great work
@vagabondjack
@yy
et al.!
10
197
698
Incredible work on Bayesian Optimization by my colleagues on Facebook's Adaptive Experimentation team. This is the next generation of A/B testing.
3
170
683
Sometimes I think the most important skill is knowing how to find information resources: knowing the right places to look, the right queries to use, the right people to ask, efficiently skimming writing, and then persevering when your process doesn't yield easy results.
18
91
687
Yesterday was last full time day at Lyft, though I’ll remain in a part-time advisory role. I’m grateful for three years filled with kind and talented people, intellectually stimulating problems, & many valuable lessons. Ten years into my tech career, it’s time for a little break.
35
2
668
The sheer faith required to build a data science team.
“Let’s hire a bunch of expensive and hard to recruit employees and have them help us get value out our data!”
“How will we know if it’s working?”
“That’s easy, we’ll hire more of them to tell us.”
13
61
659
Just trying to get an answer to my dumb stats question without judgement like everyone else and how's this supposed to make me feel Glen???
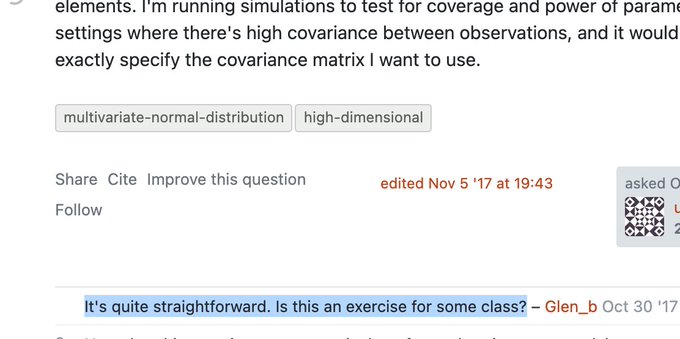
32
16
664
At Lyft we have a special implementation of gradient boosted trees for dealing with spatial data called GeoBoost. Here's how it works!
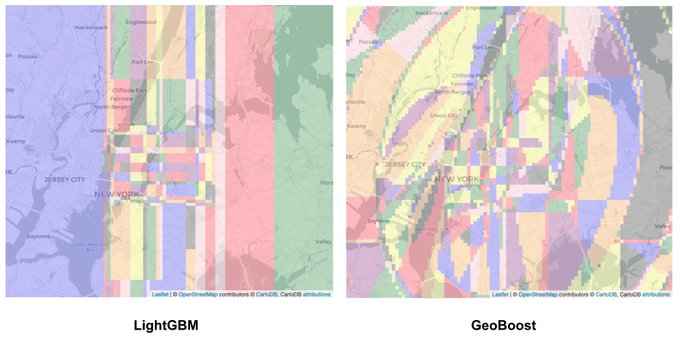
7
107
654
A/B testing is just stochastic gradient descent for companies.
13
49
642
When you start your research project with a data set rather than a research question.
13
145
649
This is amazing -- you can fit a model in R and then export to a runnable SQL statement, so scaling your prediction step is done by your database! Supports GLMs and many tree-based models.


8
113
641
What software are people using to draw those fancy neural network architecture diagrams? Surely they aren’t doing this by hand...
26
66
618
In the spirit of sharing professional failures in addition to successes: Today I had a paper rejected from a journal. It's the second journal that gave us a R&R and then rejected the revision. I've been working on this paper since 2013 and am still damned proud of the research.
20
44
628
Probably the most important skill you can have is the ability to get a big group of people to agree to working on the same thing for a prolonged period of time.
8
62
619
Your first attempt at fitting a curve might be a polynomial. You can see that as you add terms you can *interpolate* better but the *extrapolation* is very poor. This is because the local trend it is estimating is usually very wrong.
5
173
620
Pretty neat time series package from Uber's data science team. It's got a nice API and uses PyStan under the hood.

6
98
616
One weird thing about data science is that the plot you’re showing someone in your slides either takes ten times as much time as they think or a tenth of the time, but often not in between.
10
63
614
Right after that amazing feeling of getting your code to work, there's this awful moment where you realize how much clean up it needs before anyone can possibly be allowed to see it. It's like reckoning with the mess in your kitchen after cooking a big meal.
11
37
619
Someone just *called my phone* for help with my open source software. Never, ever, ever, ever do this.
37
50
607
Tools/techniques that made exploratory data analysis in Python way better for me:
1) Leveling up on method chaining in Pandas:
2) Using Altair for plotting:
3) Using nb_black to clean up notebook code:

9
121
601
A friend just asked "didn't you work at the Fed?" Yes. But as for implied expertise, let me explain:
I was an RA. Alan Greenspan liked the scenario forecast lines to be colors that our software couldn't output. My most important job was to manually alter the plots in CorelDraw.
19
33
585
Domestication is crazy. Kale, broccoli, brussels sprouts, and cabbage are all the same species, brassica oleracea.
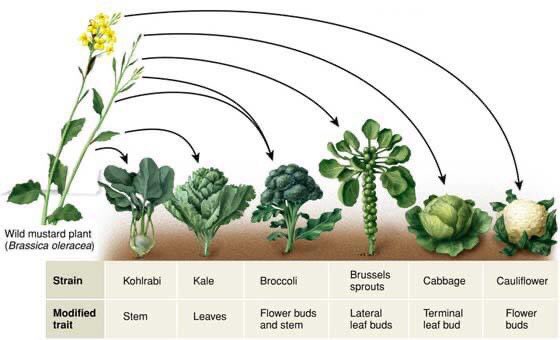
11
105
560
It's amazing how much data processing code goes away when your data is stored appropriately (usually tidy). Often, I can delete half my code once I figure out how I should have reshaped the data.
Corollary: when I'm writing a lot of code, I rethink how I've arranged the data.
12
54
551
Professional news! I’ve joined
@MotifAnalytics
as co-founder and chief scientist. Building a company and a product is a new challenge for me. Just a few weeks in I can tell it’s going to be a ton of fun.
Thanks to
@mikpanko
and Theron Ji for letting me join their awesome team!
49
16
543
Slack is just like twitter except if every tweet is someone asking me to do something, I’m not allowed to unfollow anybody, and I lose my job if I don’t use it.
9
44
547
One time, I had to estimate a confidence interval for a sample estimate and there was no convenient formula for analytic standard errors.
#IBootstrapped

5
32
545
What are the most interesting parts of building a ML classifier?
1. feature engineering
2. label engineering
3. experimenting with different models
4. hyperparameter tuning
5. summarizing/explaining model performance
6. automating training and deployment
7. <something I missed>
67
116
525
The adult version of the marshmallow test is whether you wait until the pizza cools before eating or knowingly scorch the roof of your mouth.
27
57
527
The most grad student thing I’ve done in awhile, today I emptied all my soy sauce packets from several months of delivery orders into a measuring cup and refilled my soy sauce bottle. Hard to beat this feeling.
17
3
534
Holds up perfectly over four years later.

12
74
519
We should always have an emergency task force of people with exceptional GRE scores at the ready. Whenever there's an urgent need for advice from experts in a well-established academic field, they can sub in and rediscover all their key empirical and theoretical results.
13
27
521
Big news -- our team at Facebook is awarding $150K in grants for applied statistics research! Deadline for proposals is Oct 30th. Please share! Topics include:
- experimentation
- sampling
- surveys and nonresponse bias
- forecasting
- causal inference
14
345
515
Would be useful in a world where writing code were the main hard part of software engineering.

GPT3 writing code. A compiler from natural language to code.
People don't understand — this will change absolutely everything. We're decoupling human horsepower from code production. The intellectual equivalent of the discovery of the engine.

95
429
1K
19
57
495
My team has used this idea (in PyTorch🔥) to ensure that models are consistent with various economic and business assumptions (e.g. diminishing marginal returns). It can improve quality and training requirements by not forcing your model to learn easy-to-articulate structure.

Control your ML with common-sense shape constraint!
We’ve just released TensorFlow Lattice 2.0 for training flexible and interpretable ML models powered by domain knowledge.
💡Check it out →
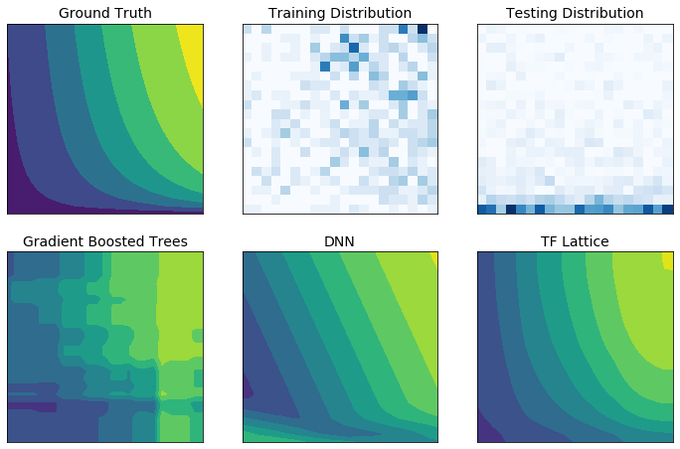
1
135
484
6
91
494

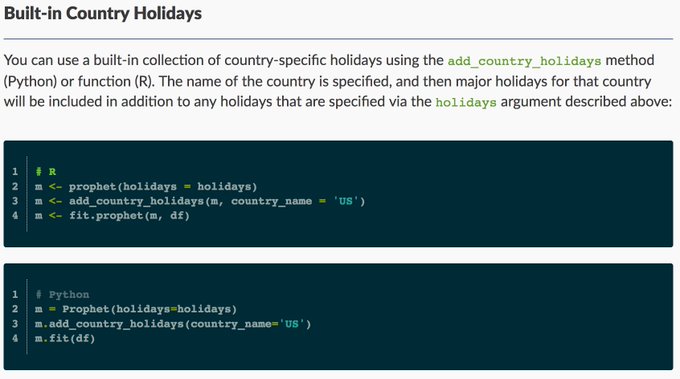
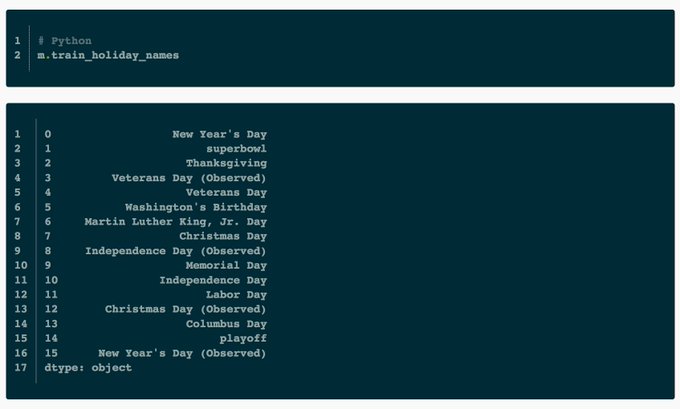
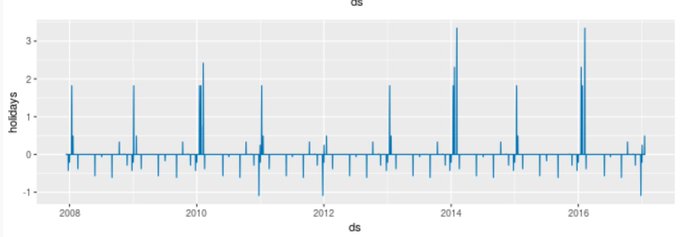
We released Prophet 0.4 today! Thanks to all the wonderful contributors ❤️
Prophet can now automatically generate lists of holidays for over a dozen countries. Just in time for the holidays 🕎🎄😜
Install:
Built-in holiday docs:
11
126
479
Maybe Google can build a 10B parameter deep learning model to predict with high accuracy THAT I NEVER WANT TO USE MAPS FROM MY WORK ACCOUNT.
14
20
461
A Python dataframe that implements something close to the dplyr API, entirely backed by SQLite (no Pandas or Numpy):
(Kind of a weird thing I was hacking on this weekend)

14
92
463
It's funny to think about how in the early days of the web, people worried Wikipedia would be filled with terrible information because anyone could edit it. Now it's basically the only resource left that I'll trust without hesitation.
15
41
457
Wrong answers only

217
90
452
Here's a nice paper about why this idea is extremely appealing and completely wrong:

12
64
453
In many cases, the secret to finishing a project is just changing your definition of what being done means.
10
35
452
I'm procrastinating tonight so I'll share a quick management tool I use. It's close to the end of H1 so performance reviews are coming. I tell this to my reports: "Your work is going to be distilled into a story, please help me tell a good one so I can represent your work well"
11
67
444
Folks have asked me for references on the ML perspective on causal inference. Here are two good ones:
1.
@matheusfacure
's book "Causal Inference for the Brave and the True" (Part II)
2.
@CasualBrady
's lecture notes (Chapter 7)
4
88
438
For a sufficiently small/biased sample, the most important factors are things experts already know and the next set of factors you learn are probably noise and unlikely to generalize. In other news, I look forward to the release of 19 new Marvel movies this summer.

Warner Bros has signed a deal for a AI-driven film management system which will help decision-making for greenlighting certain films. The AI system can assess an actor’s value in any territory and how much a film is expected to earn in theaters. (Source: )

2K
1K
4K
16
44
437
Incredibly useful reference on gradient descent optimization algorithms:
I've been reading up on these algorithms for a project and the literature is SO dense and math-y. So thankful to
@seb_ruder
for synthesizing it clearly and providing pseudocode.

3
112
434
A framework for designing and evaluating metrics:

19
102
437
If you're deploying Python code in production you probably want to know about XAR, a new open source project that lets you package many files into a single self-contained executable file:

7
127
428
If you're a data scientist who works with not-so-technical stakeholders, how do you think about getting them to listen to you, trust your analysis, and follow your suggestions? Especially when they may have strong opinions based on small samples or more limited evidence.
89
69
434
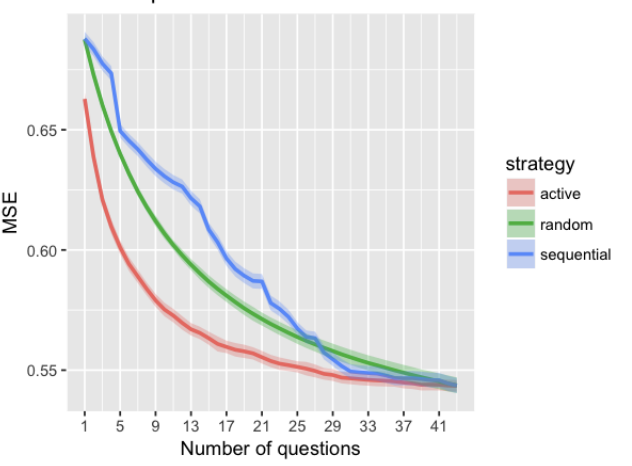
New working paper: "Active Matrix Factorization for Surveys"
w/ Chelsea Zhang, Jas Sekhon, & Curtiss Cobb
We ask fewer questions and impute missing responses via probabilistic matrix factorization, choosing questions sequentially using active learning.
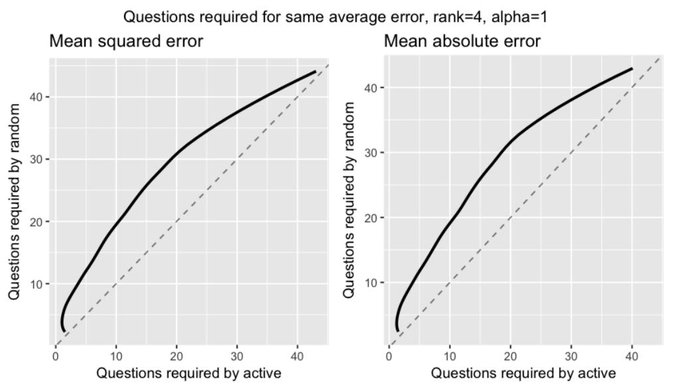


7
99
428
Today I saw the release of a previously unimaginable text to video AI model and also a new python package manager, and it’s a very close race to determine which one is more impressive to the nerd community.
10
20
425
My favorite part here is the distinction between “average” and “not bad,” which have the same mode but convey drastically different information about how much certainty you have about it.

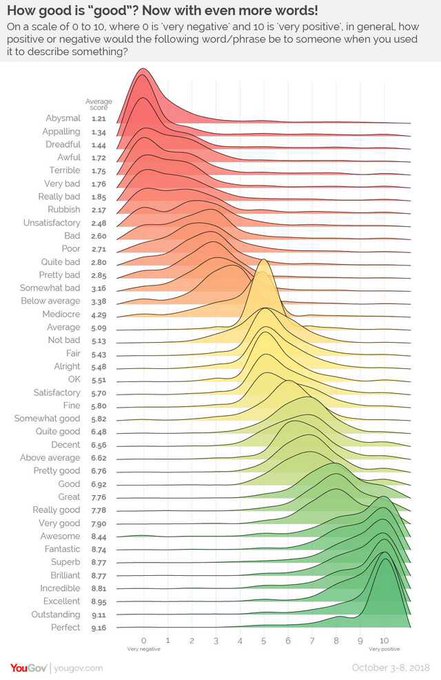
14
90
417
"No one believes an hypothesis except its originator but everyone believes an experiment except the experimenter."
- W. I. B. Beveridge (The Art of Scientific Investigation)
2
119
416
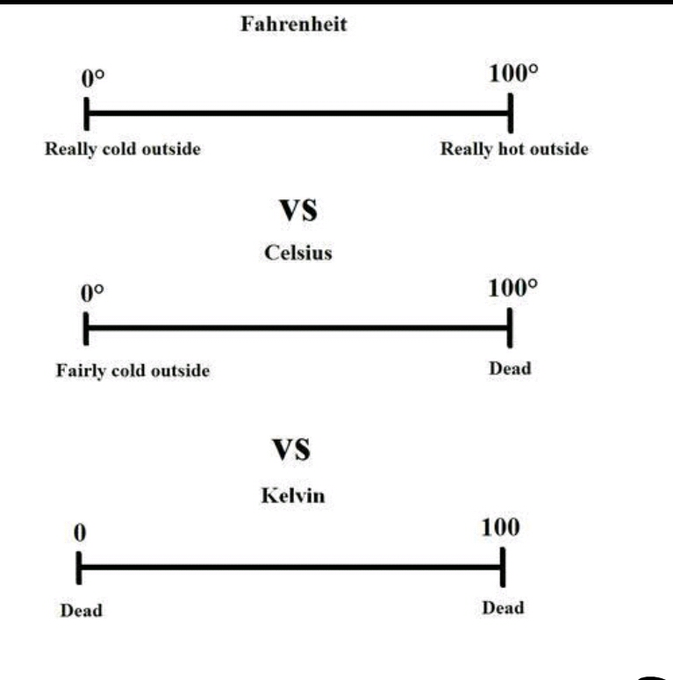
This post rips Prophet (a forecasting package I helped create) to shreds and I agree with most of it🥲 I always suspected the positive feedback was mostly from folks who’d had good results—conveniently the author has condensed many bad ones into one place.

12
58
414
Minor job announcement: I am no longer Head of Rideshare Labs at Lyft, I handed off most of my people management to a great manager who’s going to do a better job than I was. I’ll get more hands-on work and focus time, which I hope will help accelerate some exciting projects.
16
4
414
The worst part about tweeting is that all your personal and professional connections know damned well you’re procrastinating on replying to their emails.
13
15
410
In other bad financial news, I accidentally drank one of the bottles of spring water in my hotel room thinking it was complimentary.
16
6
408
Gonna start inverting loss functions and calling them win functions to see if I can make statistics more positive.
22
60
395