
Michael Ryoo
@ryoo_michael
Followers
351
Following
19
Media
7
Statuses
39
prof. with Stony Brook Univ. / research scientist with Salesforce AI Research
Joined October 2021
What we end up having at CoRL 2025 will depend on the result.

#CoRL2025 poll: If there is a K-Pop performance by a Korean idol group at the banquet, would you enjoy it?.
0
0
4
We show that the approach even allows "learning from human videos" to improve its performance. arxiv: code:

github.com
[WIP] Code for LangToMo. Contribute to kahnchana/LangToMo development by creating an account on GitHub.
0
0
3
We present a new System1-System2 model; it uses image diffusion model as its high-level System2 to predict embodiment agnostic pixel-based representation. A Transformer-based System1 maps such universal representations to actual robot actions.
1
0
3
Introducing LangToMo, learning to use pixel motion forecasting as (universal) intermediate representations for robot control: .
2
2
13
RT @corl_conf: #CoRL2025 .Hey Robot Learning Community! .CoRL 2025 will be held in Seoul, Korea, Sep 27 - 30. Submission deadline: Apr 30….

corl.org
Welcome to CoRL 2025!
0
5
0
LLaRA will appear at #ICLR2025 !!. It is an efficient transformation of a VLM into a robot VLA. For more details:.

github.com
[ICLR'25] LLaRA: Supercharging Robot Learning Data for Vision-Language Policy - LostXine/LLaRA
(1/5).Excited to present our #ICLR2025 paper, LLaRA, at NYC CV Day!.LLaRA efficiently transforms a pretrained Vision-Language Model (VLM) into a robot Vision-Language-Action (VLA) policy, even with a limited amount of training data. More details are in the thread. ⬇️



1
6
38
RT @SFResearch: 🚨🎥🚨🎥🚨 xGen-MM-Vid (BLIP-3-Video) is now available on @huggingface!. Our compact VLM achieves SOTA performance with just 32….
0
5
0
CoRL 2025 will be co-located with Humanoids 2025 at the same venue!

0
1
18
I am extremely pleased to announce that CoRL 2025 will be in Seoul, Korea! The organizing team includes myself and @gupta_abhinav_ as general chairs, and @JosephLim_AI, @songshuran, and Hae-Won Park (KAIST) as program chairs.

4
14
172
BLIP-3-Video is out!.

📢📢📢Introducing xGen-MM-Vid (BLIP-3-Video)! . This highly efficient multimodal language model is laser-focused on video understanding. Compared to other models, xGen-MM-Vid represents a video with a fraction of the visual tokens (e.g., 32 vs. 4608 tokens). Paper:
1
2
13
RT @_akhaliq: Salesforce presents xGen-MM (BLIP-3). A Family of Open Large Multimodal Models. discuss: This report….
0
76
0
Introducing LLaRA !!! It's a new robot action model, dataset, and framework based on LLMs/VLMs. It's opensource and trainable at an academic scale (7B LLaVA-based), so you can finetune it for your robotics task!.
github.com
[ICLR'25] LLaRA: Supercharging Robot Learning Data for Vision-Language Policy - LostXine/LLaRA

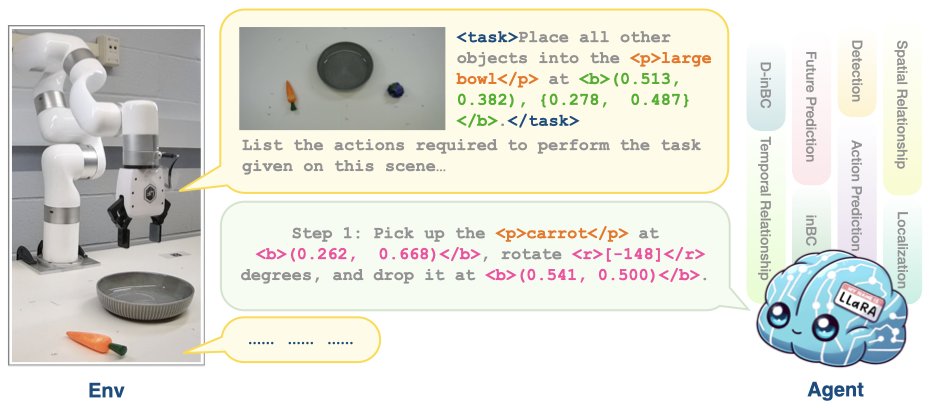
🚀 Excited to share our latest project: LLaRA - Supercharging Robot Learning Data for Vision-Language Policy! 🤖✨. We create a framework to turn robot expert trajectories into conversation-style data and other auxiliary data for instruction tuning. More details to come! (1/N)



0
1
15
RT @GoogleDeepMind: Today, we announced 𝗥𝗧-𝟮: a first of its kind vision-language-action model to control robots. 🤖. It learns from both we….
0
440
0
RT @hausman_k: PaLM-E or GPT-4 can speak in many languages and understand images. What if they could speak robot actions?. Introducing RT-2….
0
115
0
"Diffusion Illusions: Hiding Images in Plain Sight" received #CVPR2023 Outstanding Demo Award. Congratulations @RyanBurgert @kahnchana @XiangLi54505720!
2
5
28
RT @XiangLi54505720: Introducing Crossway Diffusion, a diffusion-based visuomotor policy taking advantage of SSL. In short: we add state de….
0
3
0

@DeepMind @keerthanpg @kkahatapitiy @xiao_ted @Kanishka_Rao @Yao__Lu @julianibarz @anuragarnab I thank all my collaborators!.
1
0
2
Token Turing Machines to appear at #CVPR2023!. It's a memory-based model designed for videos - using this for various sequential representation tasks at @DeepMind . Joint work with @keerthanpg @kkahatapitiy @xiao_ted @Kanishka_Rao Austin Stone @Yao__Lu @julianibarz @anuragarnab
3
5
24