

Haoran Xu
@ryanxhr
Followers
243
Following
392
Media
26
Statuses
122
Ph.D. student @UTAustin & Student researcher @MSFTResearch. Towards super-human AGI using RL.
Joined December 2016
RT @RLBRew_RLC: ⚠️ Reminder! Submissions for @RL_Conference's RL beyond Reward Workshop are due May 30 (AoE)!. We are brewing an interestin….
0
11
0
I will miss #ICLR2025 but come to check our work on a new perspective of solving Reinforcement Learning using discriminator-weighted imitation learning. @ShuozheL and @yayitsamyzhang will present it during today’s poster session.



1
5
12
Come to check our work on a new pre-training objective for LLM based on the transformer architecture, led by Edward! . More work around BST will come out, stay tuned!.

arxiv.org
We introduce the "Belief State Transformer", a next-token predictor that takes both a prefix and suffix as inputs, with a novel objective of predicting both the next token for the prefix and the...

introducing the belief state transformer: a new LLM training objective that learns (provably) rich representations for planning. bst objective is satisfyingly simple: just predict a "previous" token alongside the next token. come by our ICLR poster this thursday to chat!.
0
1
16
RT @JohnCLangford: The Belief State Transformer is at ICLR this week. The BST objective efficiently creates compac….

microsoft.com
John Langford talks about a new transformer architecture that generates compact belief states for goal-conditioned planning, enhancing planning algorithms' efficiency and effectiveness.
0
19
0
RT @harshit_sikchi: 🤖 Introducing RL Zero 🤖: a new approach to transform language into behavior zero-shot for embodied agents without label….
0
34
0
Co-led with @RichardMao93817 and other amazing collaborators Weinan Zhang & @atLargeIC & @yayitsamyzhang at @lab_midi . 😅I am unable to attend the conference this year due to 🇨🇦 VISA issues, feel free to chat with @RichardMao93817 during poster session for more details.
0
0
0
SOTA results on D4RL benchmarks (~60 on halfcheetah-m, ~100 on hopper-m, ~90 on walker2s-m, ~90 on antmaze-m-p, ~70 on antmaze-l-p and antmaze-l-d).

1
0
0
🌟Select: due to the multi-modality contained in the optimal policy distribution, the guide-step may guide towards those local-optimal modes. We thus generate a few candidate actions and use the value function to select one with the highest value to achieve global-optimum.

1
0
0
The second term is intractable due to the conditional expectation, we propose an in-sample method to accurately estimate this guidance term, avoiding the evaluation of OOD actions.

1
0
0
🧭Guide: we first show that DICE-based methods (see and for an introduction) can be viewed as a transformation from the behavior distribution to the optimal policy distribution.

1
0
0
Our framework is fundamentally different from previous methods that rely on actions generated from the diffusion behavior policy. The guide-then-select paradigm is less prone to error information from the reward model, generating in-sample optimal actions.

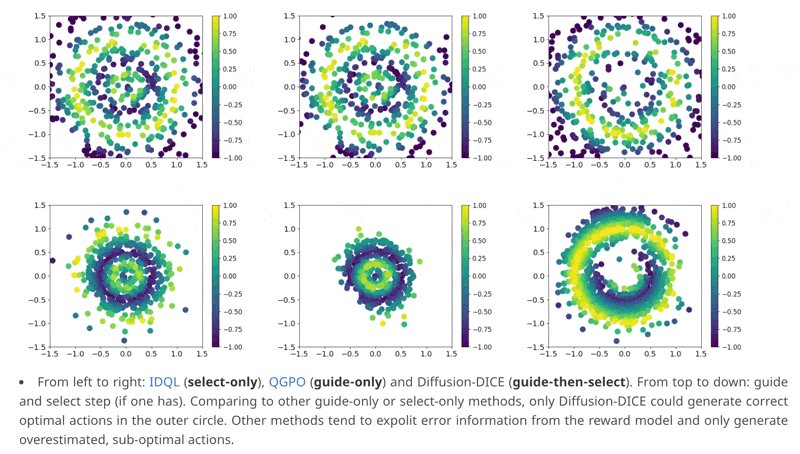
1
0
0
Diffusion models are well-known to their strong expressivity of fitting multi-modal distributions. However, how to correctly do that in RL remains unsolved. In this work, we aim to use diffusion models to fit the optimal policy.

1
0
0
📢Come to check our #NeurIPS2024 paper on how to correctly use diffusion models in RL!. We rethink diffusion-based RL algorithms by using a guide-then-select paradigm to bring minimal out-of-distribution errors. Project page:
7
23
106
RT @JiahengHu1: 🚀 Despite efforts to scale up Behavior Cloning for Robots, large-scale BC has yet to live up to its promise. How can we bre….
0
37
0
RT @harshit_sikchi: How can you use offline datasets to imitate when an expert only provides you with observation trajectories (without act….
0
11
0
RT @pcastr: Great keynote by David Silver, arguing that we need to re-focus on RL to get out of the LLM Valley @RL_Conference
https://t.co/….
0
70
0
RT @RLBRew_2024: On popular demand due to the upcoming Neurips deadline, we are further extending the submission deadline to 👉23 May 2024👈….
0
4
0