

Russell Kaplan
@russelljkaplan
Followers
11,052
Following
652
Media
79
Statuses
513
Past: director of engineering @Scale_AI , startup founder, ML scientist @Tesla Autopilot, researcher @StanfordSVL .
San Francisco
Joined January 2013
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Robert Fico
• 260560 Tweets
Newcastle
• 75519 Tweets
Assassin's Creed
• 61588 Tweets
Amad
• 59062 Tweets
Brighton
• 54978 Tweets
Antony
• 51073 Tweets
Ubisoft
• 44842 Tweets
Gordon
• 44578 Tweets
Yasuke
• 40215 Tweets
Nkunku
• 39380 Tweets
#MUNNEW
• 37897 Tweets
Cole Palmer
• 35860 Tweets
Sevilla
• 27448 Tweets
Mainoo
• 25755 Tweets
Cádiz
• 25529 Tweets
#AtalantaJuve
• 23614 Tweets
Romney
• 22305 Tweets
Nitro
• 19813 Tweets
Bruno Fernandes
• 18057 Tweets
Reece James
• 17855 Tweets
Celta
• 17006 Tweets
Hojlund
• 16423 Tweets
Amrabat
• 16071 Tweets
Rasmus
• 15593 Tweets
Mudryk
• 15333 Tweets
#CoppaItalia
• 12991 Tweets
Reims
• 10528 Tweets




















Pinned Tweet

Second order effects of the rise of large language models:
71
696
3K
You can tell the authors of the new room temperature superconductor paper believe in their results because they published two papers about it concurrently: one with six authors, and one with only three.
The Nobel prize can be shared by at most three people.


254
2K
20K
Today I saw the impact that AlphaFold is having on speeding up drug discovery firsthand:
23
571
3K
What I’ve learned about making synthetic data work for training ML models:
16
185
1K
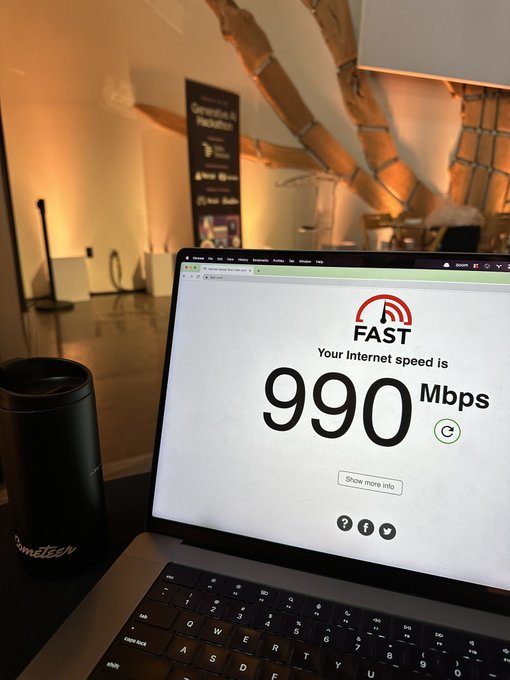
🔥 Thread of cool things hackers are building at Scale’s generative AI hackathon today:
26
141
1K
5/ Animal trials with this new protein will start soon. Still a long way to an approved drug, but it’s exciting to see drug discovery go faster with a neural network in a Colab notebook.
9
21
898
4/ AlphaFold unlocked a different approach: it found the 3D structure of the existing protein & receptors, which was unknown. With the structure + another ML model, they saw how binding affinities would change with different mutations. This led to an ideal candidate in 8 hours.
14
44
791
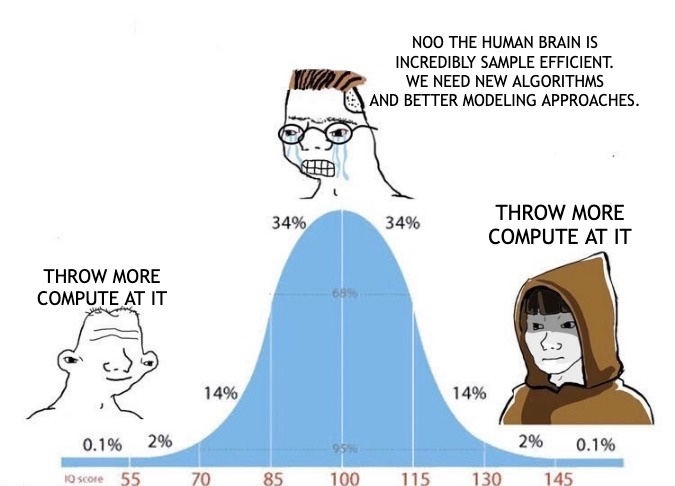
The rate limiter for AI progress (besides compute):
15
59
554
Startups that train their own large language models are starting to look like space companies. Raising millions in seed capital to afford a single training run (rocket launch). Better get it right.
11
21
511
1/ Soon, all products for creators will have embedded intelligence from massive language models (think Copilot in VSCode, DALL-E 2 in Photoshop, GPT-3 in GDocs). Companies making these products will need to roll their own massive language models or pay a tax to OpenAI/Google/etc.
10
42
474
12/ Only thing that’s certain is: it’s gonna get weird.
21
16
467
A less-obvious benefit of an on-prem ML training cluster is cultural. When you own the hardware, ML engineers are incentivized to keep utilization high. With on-demand cloud instances, incentives are to minimize costs. Former leads to more experiments and better models.
20
28
433
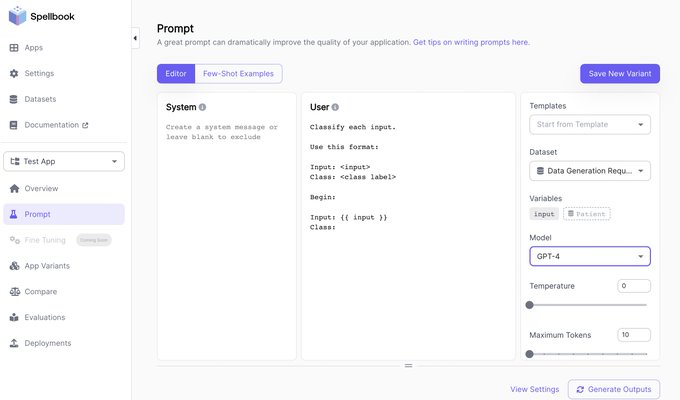
Want to play with the GPT-4 API but don't have access yet?
GPT-4 API access and playground now available in Scale Spellbook:
No CC required, signup in <1 min. We will keep this open for the first 1,000 signups. Happy hacking!
26
68
419
I recently left
@scale_AI
. I'm so thankful to the team there and for
@alexandr_wang
's bet to acquire our startup nearly 4 years ago.
When I joined Scale, it was a single-product company building the data engine for autonomous vehicles. It's amazing to see how far Scale has come:
45
7
429
Rap Battle - 🤯 demo. Pick any two people and it will generate a rap battle on the fly, using GPT-3 for lyrics, wavenet for vocals, and stable diffusion for the avatars. Sound on!
Live demo:
10
54
416
First time I’ve asked to see a company’s GPT-3 prompt as part of investor due diligence. The times, they are a-changin’.
17
30
402
10/ Instead of SEO optimization, marketers will start maximizing the log likelihood of their content being generated by an ML model. This will have unexpected consequences, like marketing data poisoning attacks ().

5
30
387
6/ Governments will eventually realize that having the computational infrastructure to train the largest language models is essential to national security. Within a decade we will see a new Manhattan project for AI supercomputing, that makes existing clusters look like peanuts.
7
31
372
2/ Over time, companies will become stratified into Compute Rich and Compute Poor. Many Compute Poor companies will become existentially dependent on the ML models of the Compute Rich.
6
30
356
Hosting a Clubhouse tonight 8pm PT with
@karpathy
@RichardSocher
@jcjohnss
on recent breakthroughs in AI. Will discuss image transformers, CLIP/DALL-E, and some other cool recent papers. Join at:
20
49
356
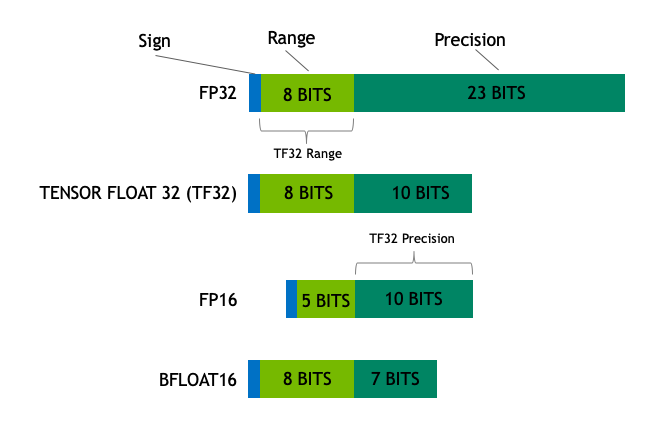
The new TF32 float format
@NVIDIAAI
announced today is a big deal. Same dynamic range as fp32, same precision as fp16, with only 19 bits total and hw-accelerated. Will be default mode of cuDNN going forward. 6x training speedup for BERT on new Ampere GPUs with no code changes!
9
77
341
8/ Generative language models will slowly replace search. Why Google something when you can get the exact answer you need, embedded in the product you’re using? We see inklings of this already with things like Copilot (). This trend has many implications.
15
26
341
3/ These Compute Rich companies will be the new platform gatekeepers of the coming decade. Just like Apple or FB can expel companies dependent on their ecosystems today (Epic Games, Zynga), in the future, if you lose access to your language model, your product won't function.
6
18
331
1/ A friend runs a biotech startup designing drugs to fight cancer. In prior work, they found that tumor cells make a protein that binds to two receptors in the body. Binding to just one of them would inhibit the tumor’s growth, but binding to both makes the tumor grow faster.
2
13
320

7/ The largest public AI supercomputer project in 2022 is Facebook’s AI RSC (), at ~$1B in capex. The original Manhattan project was ~$30B, the space race ~$250B adjusted for inflation. We have orders of magnitude of scale left just from increasing spend.
6
21
314
3/ Before AlphaFold, finding such a protein would take ~1 month: order lots of mutated DNA sequences, insert them into cells, filter the cells which bind to one receptor but not the other, and sequence those cells’ DNA.
1
11
300
To predict LLM progress areas, look at the new datasets. For example: Pile of Law, a 256GB of legal text dataset published in July 2022, has made it 10x easier for LLM researchers to get legal tokens. You can expect 2023’s LLMs to be enormously better at legalese.
6
19
282
5/ This is also why most serious AI companies are now designing their own training chips. You can either pay NVIDIA their 65% gross margins, or have each marginal dollar go ~3x as far on your inevitable billions in capex by using in-house training chips.
8
13
277
2/ If they could design a new protein that binds to only one receptor and not the other, this mutant protein might be a potent cancer drug.
2
9
264
One weird trick for better neural nets: 𝗽𝗼𝘀𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝗲𝗻𝗰𝗼𝗱𝗶𝗻𝗴𝘀. To model high freq data, instead of scalar input x, use [sin(πx), cos(πx), ... sin((2^N)πx), cos((2^N)πx)]. Used in Transformers and now neural rendering[1]. What a diff.
[1]

2
44
262
11/ We will also see Sponsored Outputs for language models. Advertisers will be able to pay to condition model outputs on their products. Significant research effort will one day go into v2 AdWords, now paying for likelihood that your ad is generated instead of search placement.
6
16
263
New blog post: How Much Better is OpenAI's Newest GPT-3 Model?
We evaluate davinci-003 across a range of classification, summarization, and generation tasks using Scale Spellbook🪄, the platform for LLM apps. Some highlights: 🧵
4
44
259
4/ The most serious Compute Rich companies will aggressively secure their compute supply chains: their access to chips. Like how Tesla is buying lithium mining rights, the Compute Rich companies must also ensure they can feed the ever growing hunger of their largest models.
1
13
247
9/ Web properties with user-generated content will change their licensing terms to demand royalties when their data is used to train AI models. StackOverflow is valuable, but why would you visit it when your editor already knows the answer to your question?
4
12
239
LLMs will work way better once they're trained explicitly to attend to an external knowledge base not seen at training time, w/out fine-tuning. Memorizing Transformers and RETRO require the knowledge base at training time. RETROfit needs fine-tuning. Is anyone working on this?
27
19
209
Excited to share what I’ve been working on lately: Scale Spellbook — the platform for large language model apps! Some fun things I learned about LLMs while building this product: 🧵

Large language models are magical. But using them in production has been tricky, until now.
I’m excited to share ✨Spellbook🪄✨— the platform for LLM apps from
@scale_AI
. 🧵
49
132
1K
6
13
200
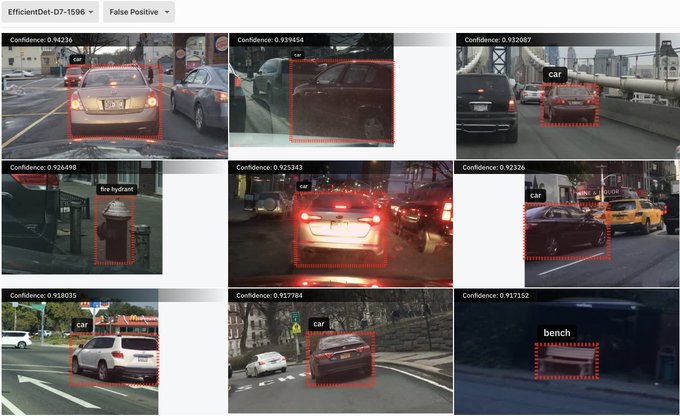
1/ Fun fact: if you sort your model’s false positive predictions by confidence, the top results will almost always be errors in your dataset's labels. Here are some “false positive predictions” according to the labels in Berkeley DeepDrive:
3
14
194
The Token Hunters. At the frontier of LLM research, they scour the world for precious new tokens to add to the training set. They’ve already scraped the internet. They will scan books, transcribe songs, hire writers, make deals for fresh token supply. The drivers of AI progress.
9
13
177
1/ It pays to be paranoid. Bugs can take so long to find that it’s best to be really careful as you go. Add breakpoints to sanity check numpy tensors while you're coding; add visualizations just before your forward pass (it must be right before! otherwise errors will slip in).
1
4
155
@sjwhitmore
and team are building a key-value store to enable long-term memory in language model conversations

6
1
150
“Realistic Evaluation of Deep Semi-Supervised Learning Algorithms” — turns out that many SSL papers undertune their baselines! With equal hyperparam budget and fair validation set size, SSL gains are often smaller than claimed.
#ICLR2018

3
54
138
GPT-3 Auditor: scanning code for vulnerabilities with LLMs.
3
4
134
@ESYudkowsky
@rmcentush
This play-money market has very little depth at the moment. As I write this, a single trade from a new account's free starting balance can swing the market more than 20 absolute percentage points.
3
0
133
What makes large companies have a strategic advantage in machine learning research & products?
Answer for the last five years: data
Next five years: compute
More & more DL research is becoming inaccessible without Google-scale datacenters.
5
51
131
4/ That last one is super powerful btw. It turns out to be way more impactful to make your synthetic *features* realistic than to make your synthetic *data* realistic. One older but good paper on this:

3
9
129
2/ It's not enough to be paranoid about code. The majority of issues are actually with the dataset. If you're lucky, the issue is so flagrant that you know something must be wrong after model training or evaluation. But most of the time you won't even notice.
3
5
125
(1/3) Writing great data labeling instructions is harder than programming. In programming, the edge cases are finite. In labeling, the edge cases are infinite and often completely unimaginable.
5
10
124
Seems like >50% of hackers have ChatGPT open writing code alongside them at the
@scale_AI
hackathon. A new era for hackathon productivity.

6
7
123
HouseGPT generates raw MIDI data directly from few-shot prompted GPT-3 to create 🎶 house music 🎶 🔊
7
9
119
Evan, Parker, and David are building a backend and database that is entirely LLM-powered. “Who needs Postgres?” 1KB of storage!

3
3
120
1/ Excited to share that Helia has been acquired by
@scale_AI
! Scale’s mission—to accelerate the development of AI applications—is an exceptional fit with Helia’s ML infrastructure tech and expertise. I’m so proud of team Helia for what we’ve accomplished in such a short time.
9
3
118

7/ Bugs are fixed faster when iteration times are faster. Impose a hard ceiling on model training time, even if you could squeeze more gain by training a bit longer. In the long run, experiment velocity >> performance of one model.
3
2
113
So cool to see Tesla and
@karpathy
reveal HydraNet to the world. What started as my Autopilot internship project two years ago has come a long way...

3
14
111
1/ It’s increasingly clear that language-aligned datasets are the rate limiter for AI progress in many areas. We see incredible results in text-to-image generation and image captioning in large part because the internet provides massive language<>image supervision for free.
3
5
100
4/ You can unit test ML models, but it's different from unit testing code. To prevent bugs from re-occurring, you have to curate scenarios of interest, then turn them into many small test sets ("unit tests") instead of one large one.
3
5
105
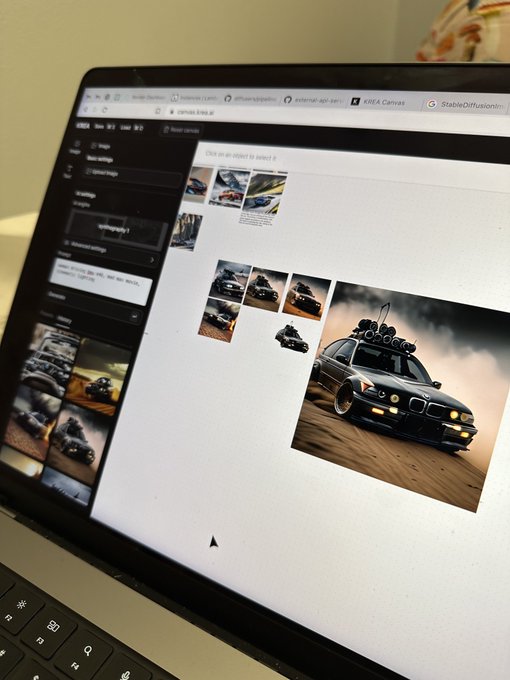
The
@krea_ai
team is building the Game of Life, where each alive cell is a whimsical happy Stable Diffusion image and each dead cell is an eerie, dark Stable Diffusion image, all of which evolve over time. Built on a generative AI version of Canva they made.
3
3
102
3/ The antidote is obsessive data paranoia. Without this, data issues will silently take away a few percentage points of model accuracy.
1
5
101
Avirath and
@highchinar1
are building a personalized learning curriculum generator on top of Spellbook

1
3
99
Next gen voice assistant with Whisper for transcription and LLMs doing document retrieval + question answering.
@mov_axbx
brought his GPU workstation for extra-low-latency edge inference 🔥
3
3
93
4/ Imagine if AlphaZero, beyond telling you the best chess move for a position, could also explain in English *why* that move is best, and why the more natural-seeming move is wrong. With linguistic reference to patterns that are human-interpretable.
4
4
90
5/ Training strategies are also better understood. If you have lots of real data and are using synthetic to cover edge cases, train jointly. With very little real data, it’s best to pre-train on synthetic and fine-tune on real. Synthetic works best as a complement to real.
2
3
90
6/ When someone asks “why do you think that?”, you can’t articulate the true reason: the billions neuron firing patterns in your head that led you to your result. You project this complexity down into a low-dimensional language description.
3
4
87
5/ Of course, such an explanation won’t be perfectly accurate. Any explanation in language is a low-dimensional projection of what’s really happening inside AlphaZero’s torrent of matrix multiplies. But the same is true when we use language to describe our own thought processes.
1
2
83
3/ Software actions, work tasks, healthcare, economic data, games… think about all the domains where we do *not* have this language-aligned training data, and what would be possible if we created that data.
3
4
77
3/ Today, the toolbox for overcoming the reality gap is large. Beyond better rendering, we have GANs for domain adaption (e.g. CycleGAN), domain randomization (popular in RL), adversarial losses on neural net activations to force synthetic / real feature invariance, and so on.
1
4
75
🌳🌍 Automatic permit application generation for climate tech companies & carbon dioxide removal, by
@helenamerk
@douglasqian
@PadillaDhen

4
1
75
1/ Context: synthetic data has matured drastically in the past 1-2 years. It’s gone from a research niche to a production dependency of many large-scale ML pipelines, especially in computer vision.
2
2
72
Imagining a world of interacting LLMs that depend on others' specific embedding spaces. To upgrade one, you will have to upgrade the versions of all dependencies, or vector spaces will be incompatible. Dependency hell for LLMs incoming!
10
4
72
6/ Without model unit tests, you will see aggregate metrics improving in your evaluation but introduce critical regressions when you actually ship the model. Unit tests are a requirement to durably fix bugs in ML-powered products.
1
3
70
9/ (This is also why Scale is starting a dedicated effort to create or collect language-aligned datasets for new problem domains. If you want help collecting language alignment data for your domain, reach out: language-models
@scale
.com)
9
5
66
Some applied deep learning principles on the Autopilot team, presented at
@Pytorch
dev summit:
- Every edit to the dataset is a new commit. Track carefully
- Curate hard test sets; random isn’t good enough
- Train all tasks jointly from scratch whenever possible

1
11
65
Language models are having rap battles now
Rap Battle - 🤯 demo. Pick any two people and it will generate a rap battle on the fly, using GPT-3 for lyrics, wavenet for vocals, and stable diffusion for the avatars. Sound on!
Live demo:
10
54
416
5
6
63
"Data network effects" claimed by AI startups are overhyped. Unlike most network effects, e.g. social networks where value is O(n^2) in # users, value of more data grows only O(log n). See:
0
15
61
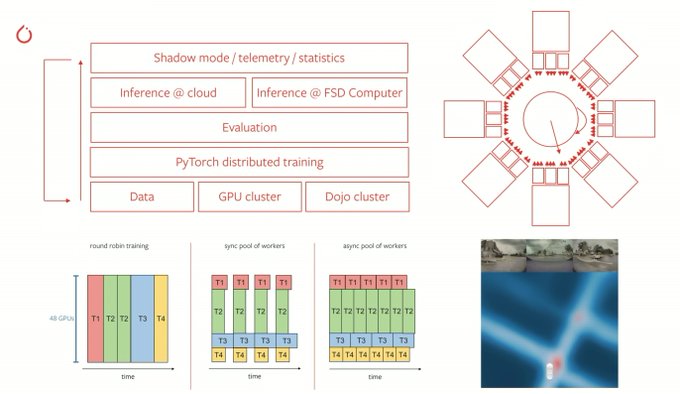
@karpathy
Talk highlights:
- 70,000 GPU hours to "compile the Autopilot"
- Tesla building custom neural net training HW
- Data & model parallelism for a giant multitask, multicamera NN
- Predictions made directly in the top-down frame
2
8
60

@HamelHusain
LLM Engine is free & open source, self-hostable via Kubernetes, with <10s cold start times including for fine-tuned models:

4
6
61
(0/6) Lots of exciting progress in neural network HW/SW systems shown off at MLSys this year. My main takeaways / favorite talks…
1
8
59
2/ By scraping image+caption pairs, you can create a strong self-supervised objective to relate images and text: make image and text embeddings similar only if they're from the same pair. But most data modalities don’t come with this language alignment.
2
1
56
2024 is going to see a major improvement in language models' ability to reason. There is so much cooking...
3
1
59
8/ Language-aligned datasets are the key to step-change progress on ML interpretability, and to neural networks helping with more and more problems. They will also help neural networks work *with* people instead of just replacing them.
2
2
58
7/ (A lot of these learnings come from helping incubate Scale’s new synthetic data product, which just launched publicly)
2
4
57
It seems like everyone in my lab has a part time gig at Google/FB/DeepMind/MS just for the extra compute. And that’s at Stanford, where AI funding is not exactly lacking
1
15
56
Quite impressed with my first
@scale_AI
data labeling job submission. Uploaded 1k image annotation tasks before going to sleep last night. Woke up and they are all labeled. With good quality!
1
7
56
When you’re in line for the bathroom at CS commencement and Don Knuth walks up behind you and says hi

0
2
52

5/ Each unit test should have an evaluation metric of interest, a pass/fail threshold, and be defined for a curated subset of data.
1
2
50
Since last week:
- CA to ban new gas car sales in 2035
- China pledges full carbon neutrality by 2060
- Tesla announces 50% cheaper batteries in 3 years
- GE to stop building coal plants
- Google to be carbon-free by 2030
- Walmart carbon neutral by 2040, AT&T by 2035
Progress!
2
1
48
And most importantly, davinci-003 can explain code in the style of Eminem.

2
8
48

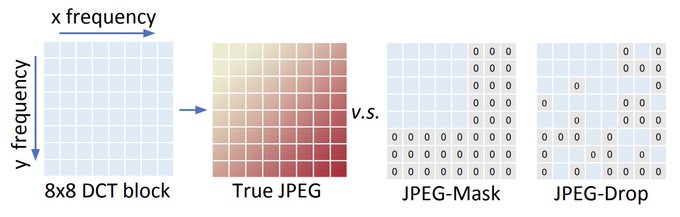
2/ Historically, the
#1
obstacle to adopting synthetic data has been the reality gap — the small differences between real and synthetic data that models may fixate on incorrectly, harming generalization.
1
2
44
6/ In the long run, synthetic data passes AI research’s “bitter lesson test” — it’s a general method that becomes better with increasing amounts of computation. Expect its popularity to keep growing.
3
5
44
We are so back.
Rolling admissions for
@scale_AI
's second generative AI hackathon are now open. Happening July 15th in San Francisco. Apply by June 12th for a spot.
Application link below.
🔥 Thread of cool things hackers are building at Scale’s generative AI hackathon today:
26
141
1K
2
12
42