

Replicache
@replicache
Followers
3,891
Following
1
Media
3
Statuses
169
A JavaScript framework for building high-performance, offline-capable, collaborative web apps. Come say hi at !
Joined January 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Kendrick
• 790537 Tweets
Drake
• 717456 Tweets
Rocky
• 252321 Tweets
#BANOBAGIxTEN
• 179138 Tweets
みどりの日
• 86845 Tweets
Hope Hicks
• 80063 Tweets
WNBA
• 69900 Tweets
Padres
• 58109 Tweets
#แบมแบมอินราชมัง
• 54832 Tweets
#ENCOREAREA52DAY
• 53878 Tweets
スパコミ
• 47696 Tweets
Kdot
• 34515 Tweets
Aubrey
• 32487 Tweets
Caitlin Clark
• 29209 Tweets
Cavs
• 28331 Tweets
Thiago Silva
• 25143 Tweets
Kul Ka Crown
• 24192 Tweets
設営完了
• 16638 Tweets
Emilia
• 15277 Tweets
Garland
• 14558 Tweets
Rick Ross
• 12029 Tweets
Marlins
• 11420 Tweets
結束バンド
• 11179 Tweets
Drizzy
• 11015 Tweets
Donovan Mitchell
• 10974 Tweets
Arraez
• 10291 Tweets





















Early feedback on Replicache:
"Absurdly easy"
"Exciting stuff"
"🔥🔥🔥"
"Next time I build an offline app, I don't need to build a f-cking sync engine"
1
2
40

How Replicache helps
@assetbots
build an amazing realtime user experience as a one-person startup.
1
7
17
We are extremely excited to share the news that
@ErikArvidsson
is joining Rocicorp and will be working with us on Replicache. Unstoppable now!
0
1
16
It slices, it dices, it juliennes fries!
When you use realtime sync to move data to the client, you can build much more interactive experiences, much more easily.
Learn how we built a zero-latency filter picker for an issue tracker using Replicache:
0
0
15
Slides for yesterday's talk on Replicache and Reflect:

0
1
15
Reflect is the next step for Replicache.
It takes the game-inspired sync engine from Replicache and adds a completely managed backend, making it absurdly easy to create game-quality multiplayer apps.

✨ Announcing Reflect ✨ – A new way to build multiplayer apps like Figma or Notion.
Rather than CRDTs, Reflect syncs the way video games do. Today, Reflect is available to everyone.
Learn more: What the Multiplayer Web can Learn from Video Games ⏩
29
62
474
1
1
14
Some people ask about Replicache's consistency model.
This is a good question! As the saying goes: it's easy to be fast and incorrect.
We wanted to be sure, so we asked Jepsen to review our early designs: .

Last fall, Replicache commissioned Jepsen to take a look at their design docs, and we wrote a bit about how it works:
They're doing something kinda like Bayou for mobile apps: local, speculative JS transactions, replicated asynchronously.
1
3
12
1
3
9

Most excitingly, this dramatically reduces our costs, since we're no longer running infrastructure.
To celebrate, we're making Replicache free for any non-commerical projects.
We're also upping the free tier for commercial to 500 monthly actives:

2
1
7
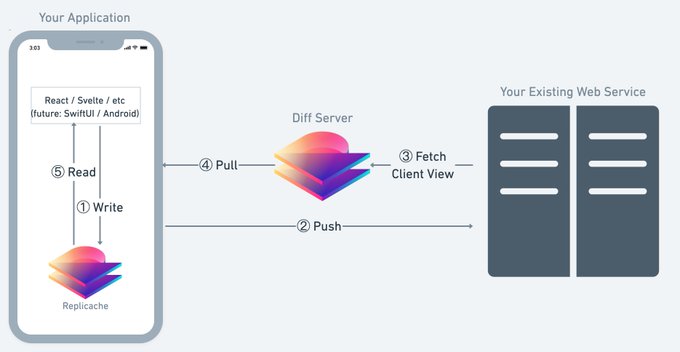
Replicache is removing the "diff server" from our sync protocol.
This is very exciting because it makes Replicache now a *purely* client-side solution. Your data goes directly from your server to your client, without passing through any services run by us.
1
1
7
Replicache for the web is here!
I know ya'll weren't busy with anything else today, but btw:
@replicache
is now available in beta for web applications:
4
17
128
0
0
6
Wow! The response to our announcement yesterday was pretty awesome. About 200 of you signed up to join the early access program in 24 hours.
If you still want to, hit that big pink button on !
1
1
5
@equanimityhow
Firebase is not fully offline-first either. You can't do queries locally, so many screens in your app end up going to network first, then falling back to local only after a timeout. This destroys the responsiveness that is a hallmark of a truly offline-first design.
0
0
4
Replicache 11 release notes. Come for the new indexing features, stay for the exciting `compare-utf8` origin story!
0
3
4
The only caveat is durability: transactions aren't final until confirmed by your server.
For many transactions (mark-read, compose-draft) you can assume success and tell user they are final immediately.
For some (buy-concert-ticket), you will want to wait for server to confirm.
2
1
4
Check out the latest at or go directly to the sdk at .
Happy hacking!
0
0
4
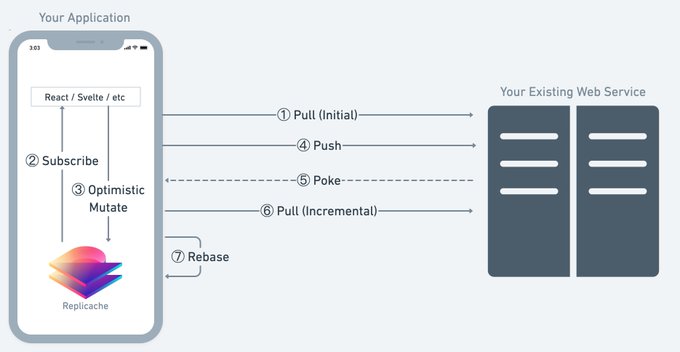
Poke.

When processes evolve separately from each other, their state diverges.
That's why we're kicking off a newsletter. Issue 001 of "The Sync" covers the last six months of changes to
@replicache
and
@hello_reflect
.
Check it out at .
0
1
6
0
0
4
We think this will be a much nicer way to work with offline-first systems, and are looking forward to sharing more details over the coming months.
0
1
3
4
0
3
🧵…
@replicache
is a very very different way to build web apps.
There are no apis. At least not like graphql/rest style apis. There are no loading indicators. No http errors.
There’s no real distinction between network data, and client data.
1
2
7
0
0
2
We'll be implementing this change over the coming month or so -- the current docs and setup still require the diff server.
But it will be a minor change from a user perspective, so if you start playing with Replicache now, it won't hurt badly when we remove diff server later.
1
0
2

0
0
2
@troutgirl
@JacobMGEvans
@JeromeHardaway
@replicache
does offer a hooks interface in `replicache-react` fwiw :).
1
0
2
@VLecrubier
The API will not change significantly, so it's fine to start using Replicache now anticipating this feature will appear. Thanks!
0
0
2
"Absurdly easy"

Pop this demo open in two browser windows and watch changes in one get reflected in the other.
The most interesting thing about replicache is that it's absurdly easy to write a backend for it - build an endpoint that returns ALL state in one go, Replicache handles diffing/etc
2
4
24
0
0
2
@VLecrubier
We're working on it actively, and it's our top priority. We have had a shockingly high number of requests for this :). We expect it to be available this fall.
2
0
2
We will continue to maintain Replicache, but if you're not interested in running your own backend, or found it too difficult, take a look at Reflect! You can have your first app live in minutes!
0
0
2
1
1
2
@troutgirl
@JacobMGEvans
@JeromeHardaway
We aren't super stoked with hooks, but it seems better than not-hooks. And it's certainly the direction the community is going.
0
0
2
In short, a correctly implemented Replicache-powered system (including all clients and your backend) will be Causal+ Consistent: .
This is one of the strongest consistency models offline clients can ensure.
1
0
2
Killing diff server is great for privacy, security, reliability, but there's more! It:
* Removes couple network hops from sync, decreasing latency
* Eliminates the size limitation on Replicache - instances are now limited only by client side capacity ()
1
0
2
Most interestingly:
💪🏾 90% (!!) of you would prefer to run Replicache yourself!
This sounds pretty great to us: We don’t want your data any more than you want to give it to us!
(We may still offer Replicache as a service if you insist).
1
2
2
New., quicker, quickstart available for Replicache JS SDK:
Check it out!
0
3
2
What does this mean to you as a developer?
We think it's a pretty nice way to work. You get arbitrary transactions, written in a full programming language that are very similar to "ACID"-style transactions.
1
0
1
@nullstax
If you open the network tab, you'll see that the pull actually happens in chunks of ~3MB. Although we do eagerly download the entire dataset, we do so by expanding a window in 3MB increments. The same exact technique could be used to delay downloading some data if desired.
1
0
0
@alley_oop
Hi
@alley_oop
,
The detailed proposal is here: .
The bug tracking the work is here:
1
0
1
Replicache was always *primarily* client-side, and worked with any standard backend stack.
But it did require this web service we ran on . The intent was easy integration: servers could just return a JSON snapshot, we'd calculate a diff to send to clients.
1
0
1
But talking to customers, we've learned that tradeoff isn't worth it. They'd prefer a bit extra work to get us out of the loop. We are only too happy to oblige.
2
0
1
Either way, you can follow this account to keep updated of developments in our work.
Thanks so much for listening, and for your interest in Replicache!
0
0
1
Thanks
@bfirsh
!

I have tried and failed to build this several times over the past few years. This would have saved me so much time had it existed then:
Something about tools with names starting with "Replica-", eh.
0
0
12
0
0
1
Co sign

0
0
1
Next up for us: Select a new small group of customers to work with.
Basically, the people we think we can help most and fastest. We’ll let you know if you’re in that group this week.
1
0
1
@fredkisss
You have to make some (relatively minor) changes to your schema to support Replicache, and you have to implement two special endpoints – /push and /pull.
You can get a feel for what's involved here:
0
0
1
Some interesting stats:
👩🏽💻~80% of you are building a web app, 50% mobile, 15% other
🕸~70% your web apps are built with React!
📱~50% of your mobile apps are built with React Native, 34% iOS/Swift, 20% Flutter
1
0
1
@gr2m
A client is an instance of the Replicache client embedded inside an app. In the context of web applications, a client would typically correspond to a browser on a user's computer. The price is in terms of number of unique clients that sync per month.
0
0
1
@swyx
@roomservicedev
@homebase__io
An important distinction is going to become whether the solution wants/needs to be an one-stop-shop (like Firebase - db, auth, hosting, security, etc), or whether it can be used with your existing stack.
0
0
1