
Rajat Arya
@rajatarya
Followers
289
Following
313
Media
27
Statuses
813
Current: @huggingface tech lead + software engineer, Previously: XetHub co-founder. Backend software engineer, 10+yrs building ML systems.
Seattle, WA
Joined August 2008
RT @Gradio: Today, we are excited to launch 𝑇𝑟𝑎𝑐𝑘𝑖𝑜, a lightweight experiment tracking and visualization library — written in <1,000 lines….
0
52
0
100% agree, can't wait to see how well Xet scales for Llama 4 Behemoth!.

Llama 4 Maverick and Scout are the first major models on Hugging Face uploaded with Xet, making the upload significantly faster for Meta and saving you 500GB on downloads. Very necessary as the size of models is increasing. Can’t wait to see how much speed up Behemoth will get
0
0
2
RT @RemiCadene: HOT 🔥 fastest, most precise, and most capable hand control setup ever. Less than $450 and fully open-source 🤯.by @huggin….
0
229
0
Love DIY Quantified Self! Can't wait to try this out for myself. .

Super excited to introduce Halo: A beginner's guide to DIY health tracking with wearables! 🤗✨. Using an $11 smart ring, I'll show you how to build your own private health monitoring app. From basic metrics to advanced features like:.- Activity tracking.- Heart rate monitoring.-

0
0
3
RT @AnnInTweetD: First demo of a @xetdata-backed roundtrip to/from @huggingface servers = first steps to a faster, more scalable HF Hub!….
0
4
0
RT @xetdata: Adding AI to your project for the sake of it won’t lead to success. Here’s what you need to know before integrating AI 🧵.
0
1
0
RT @_odsc: Don’t miss Rajat Arya’s @rajatarya upcoming Solution Showcase Talk, Visualizing the Evolution of ML Models, at the AI Solution S….
0
1
0
We launched our revamped website on a Friday afternoon. 🚀 What did you do today to know you are alive?.
0
0
1
RT @xdssio: Excited to share my latest article on data versioning framework in machine learning! After months of research and project work,….
0
4
0
RT @xetdata: AI Conference is happening next week in San Francisco (September 25th & 26th) and we're thrilled to be presenting and supporti….
0
1
0
Here's what the entire process looks like on my laptop. The model loaded in 0.6s (622.73ms) on this invocation, and the recipe seems pretty decent. Try it out and let me know how it works for you!

0
0
0
Here’s the code to get Llama 2 up and running on your Mac laptop in a few minutes. The first time you run this, it should take ~4m for the model to load, but it should then load within a second. So, the total time from start to finish is < 5m for running Llama 2 on your laptop.

1
1
0
3. pip install pyxet for Python SDK and CLI. 4. Set up authentication: Create a Personal Access Token and then run the login command from a Terminal so your ~/.xetconfig is set up with your login token.
1
0
0
1. Create an account: Go to and Sign in with GitHub. 2. Quick start: Go to follow the Install & Setup steps (.

xethub.com
Accelerating large scale storage and collaboration features at Hugging Face
1
0
1
I really wanted to run Llama 2 locally on my Macbook Pro instead of on a Linux box with an NVIDIA GPU. So I put the llama.cpp GGML models into the XetHub Llama 2 repo, and now I can use Llama 2 in just 5s, and it loads the GGML model almost instantly. Here's how I did it:.
1
1
4
Let me know if you've tried it out! I’ll also add the -GGML variants for the folks using llama.cpp. And if there are other models and datasets you’d like to see on XetHub, leave a comment below 👇. Happy Llama 2-ing!🦙.
0
0
0
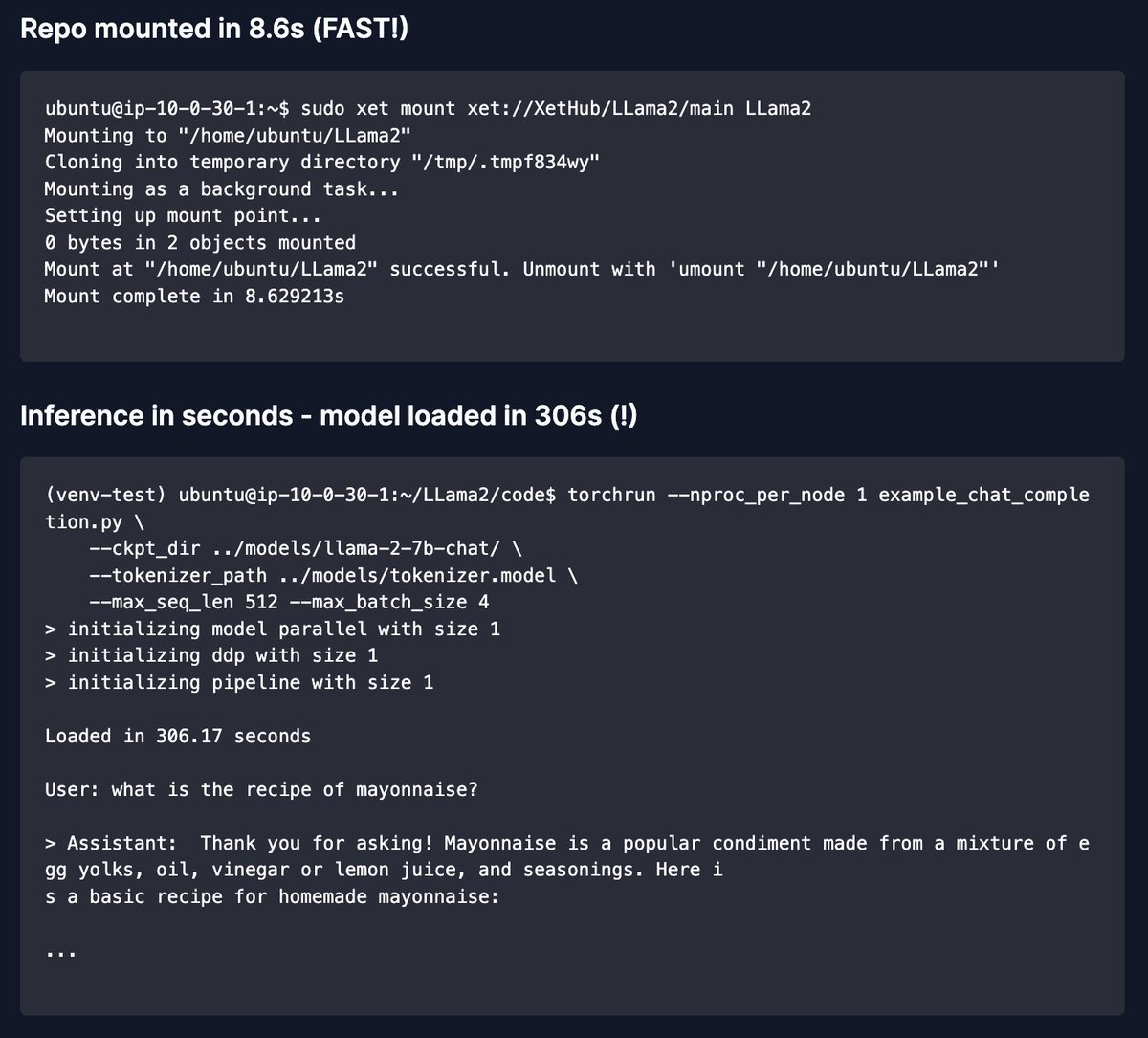
With @xetdata’s xet mount, you can get started in seconds and you’ll have the model ready to generate text in just a few minutes—without needing to download the whole model or make an inference API call. I got the whole repo mounted in 8.6s and the model loaded in 306s (<10min)
1
0
1
I wanted to play with Llama 2 right after its release last week, but it took me ~4 hours to download all 331GB of the 6 models.😬. So I brought them into @xetdata, where you can start using it in just a few seconds:
1
0
1
For real! Shawn has disappeared from the digital world. But I did catch up with him _once_ after I left Apple. He was super busy doing important things, if I remember correctly.

@QuinnyPig /cc: @backwoodsbrains.
0
0
1
RT @xdssio: When working on data science projects, I often want to save my work without having to think deeply about what's changed. I mad….
0
1
0