

Nick Jiang
@nickhjiang
Followers
750
Following
1K
Media
33
Statuses
224
interpreting neural networks @berkeley_ai // cs + philosophy @ucberkeley // prev @briskteaching @watershed
Berkeley, CA
Joined July 2019
What makes LLMs like Grok-4 unique?. We use sparse autoencoders (SAEs) to tackle queries like these and apply them to four data analysis tasks: data diffing, correlations, targeted clustering, and retrieval. By analyzing model outputs, SAEs find novel insights on model behavior!

6
16
156
RT @nickhjiang: What makes LLMs like Grok-4 unique?. We use sparse autoencoders (SAEs) to tackle queries like these and apply them to four….
0
16
0

RT @BaldassarreFe: Say hello to DINOv3 🦖🦖🦖. A major release that raises the bar of self-supervised vision foundation models. With stunning….
0
277
0
RT @NeelNanda5: I'm excited about our vision of data-centric interpretability! Even if you can't use a model's internals, there's a lot of….
0
9
0
Work done with @lilysun004*, Lewis Smith, and @NeelNanda5. Thank you to @GoodfireAI and MATS for compute support!. Blog post:
lesswrong.com
Nick and Lily are co-first authors on this project. Lewis and Neel jointly supervised this project. …
0
0
10
Our results suggest that SAEs can systematically analyze large datasets for insights. We are particularly excited for their application to data-centric interpretability, which we believe is an under-invested but crucial approach to understand models.
1
0
2
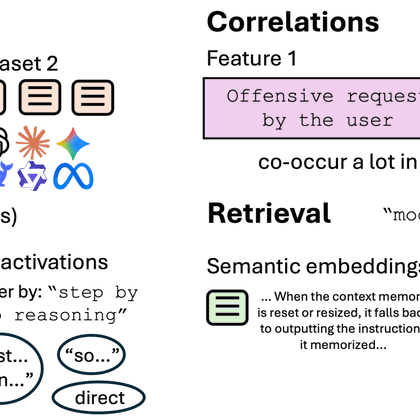
Finally, we use SAEs for data retrieval and find they excel at property-based queries (e.g., “repeating text”). We construct a benchmark of property-based queries and find that SAEs often outperform semantic embeddings, which are tuned for semantic queries like fact-finding.

1
0
5
SAE features can also cluster data in different ways than semantic embeddings, which group data by similar topics. By filtering features (ex. tone-related), we can group data by similar properties. For instance, we can cluster GSM8K responses into different reasoning approaches.

1
0
3
We can also detect correlations in datasets, where all French samples might happen to only talk about dogs. By finding features that co-occur often in data samples, we find that offensive topics in Chatbot Arena tend to correlate with narrative stories.

1
0
3
For example, to “diff” two datasets, we can subtract the frequencies by which features fire. Diffing model outputs to the same prompts lets us compare models like Grok-4, with top feature differences revealing stronger differences at 5× lower cost than our LLM baseline.

1
0
4
LLM outputs & training data hold valuable insights on how models behave and work. While analysis has typically relied on LLMs 🤑🤑, we show that SAEs can interpret large datasets more efficiently by using max-pooled feature activations as a large set of labels for our data.

1
0
9
man when u visit a new country and this is the first meal you’re handed

1
0
8
So much of research centers on hope and faith that ppl who don’t take leaps of faith are unlikely to enjoy research.
3
0
10

RT @nickhjiang: Updated paper!. Our main new finding: by creating attention biases at test time—without extra tokens—we remove high-norm ou….
0
35
0
Additionally, we release a LLaVA-Llama 8b model (CLIP-L encoder) configured with a test-time register. We have also updated references and added new experiments to the appendix!. LLaVA-Llama 8b: Paper: Repo:

huggingface.co
1
0
5
These findings are preliminary and only done on a base OpenCLIP model, where outliers are small (norm < 500). If they extend to the language domain, however, they offer a promising way to manage outliers—a challenge for quantization—without engineering hacks. See Appendix A.11.
1
0
1
Zeroing out the activations of register neurons removes outliers and drops classification performance by ~20%, but adding an attention bias recovers this drop. Our results suggest that outliers are primarily attention biases in ViTs.

1
0
2
Sun et al (”Massive Activations”) proposed adding an attention bias during training to mitigate high-norm outliers. But we can do this training-free! Specifically, for each attention head, we set v’ and k’ to the value and key vectors of a test-time register averaged over images.

2
0
3