

Jay Hack
@mathemagic1an
Followers
37,499
Following
2,802
Media
669
Statuses
3,885
Founder/CEO @codegen . Tweets about AI, computing, and their impacts on society. Previously did startups, @palantir , @stanford . Not a pseudonym.
San Francisco
Joined May 2013
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#Eurovision2024
• 1016260 Tweets
Switzerland
• 116758 Tweets
Flamengo
• 107134 Tweets
Corinthians
• 101517 Tweets
Portugal
• 97178 Tweets
#AMVCA10
• 95371 Tweets
Luka
• 85519 Tweets
Reece James
• 85495 Tweets
Spain
• 71968 Tweets
Italia
• 66522 Tweets
#ESC2024
• 64191 Tweets
Slimane
• 62801 Tweets
Irlanda
• 62132 Tweets
Norway
• 60218 Tweets
Pirates
• 55051 Tweets
#ESCita
• 51185 Tweets
Suiza
• 44579 Tweets
Nemo
• 44538 Tweets
Lorran
• 44181 Tweets
Stephen
• 40252 Tweets
Francia
• 38642 Tweets
Croatia
• 31335 Tweets
Alemania
• 30267 Tweets
Loreen
• 29965 Tweets
Paul Skenes
• 28725 Tweets
Austria
• 26657 Tweets
Finland
• 25975 Tweets
Estonia
• 25366 Tweets
#ESC24
• 25308 Tweets
Kyrie
• 25098 Tweets
ABBA
• 24343 Tweets
Dort
• 22030 Tweets
Armenia
• 21959 Tweets
Olly
• 17586 Tweets
Grecia
• 16600 Tweets
Paulinho
• 15678 Tweets
Breath of Life
• 14373 Tweets
Lively
• 12968 Tweets
Baby Lasagna
• 12827 Tweets
Gerson
• 12751 Tweets















![ねね[女体だけど'男の娘']](https://pbs.twimg.com/profile_images/1196937645760233472/pRo0HF8h.jpg)




Pinned Tweet

Excited to share what I've been building 🚀
Introducing
@codegen
⚡ Agent-driven software development for enterprise codebases ⚡
We've raised $16mm from
@ThriveCapital
and others to bring this to the world -
👇 More below
66
123
1K
Parrots are clearly intelligent enough to understand video UIs
They also apparently prefer watching videos of other parrots 🤔
This implies an opportunity for a "parrot streaming" platform. Looking for a team who is as excited about this opportunity as Iam
432
5K
26K
Introducing text-to-figma: build and edit
@figma
designs with natural language!
Join the waitlist here:
1/n
94
417
3K
Sounds like rumors were accurate:
GPT-4 will come in multimodal flavors (including video!)
GPT-4 release next week

81
546
3K
🤔 What comes after Copilot?
My take: a conversation with your codebase!
Introducing Tensai, your repo-level code assistant
❔ Ask complex questions
✅ Automatically generate PRs for complex tasks
More👇
88
329
2K
My thoughts on Toolformer
IMO the most important paper in the past few weeks.
Teach an LLM to use tools, like a calculator or search engine, in a *self-supervised manner*
Interesting hack to resolve many blind spots of current LLMs
Here's how 👇

42
374
2K
An intriguing trend in AI 🤖:
“Models all the way down” (aka "stacking")
Have models invoke other models, then watch as emergent intelligence develops ✨
Here’s a discussion of what, how, and why this is important to watch 👇
55
330
2K
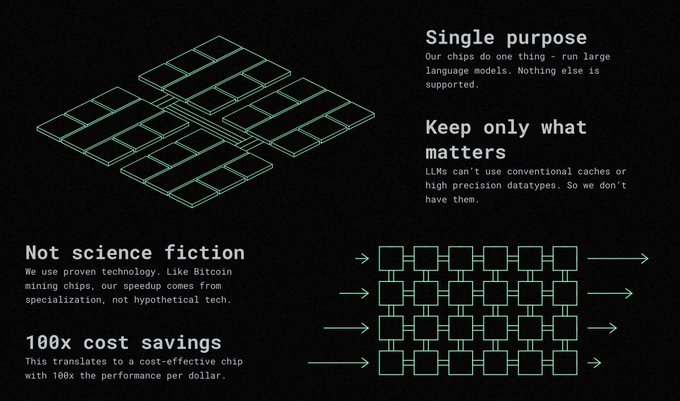
Been waiting for something like this for a while:
: printing specific model architectures on a chip.
Claims 100x speedup over GPUs. Not hard to imagine.
What happens when you can run a GPT forward pass at the speed of electricity, no clock needed?
88
213
2K
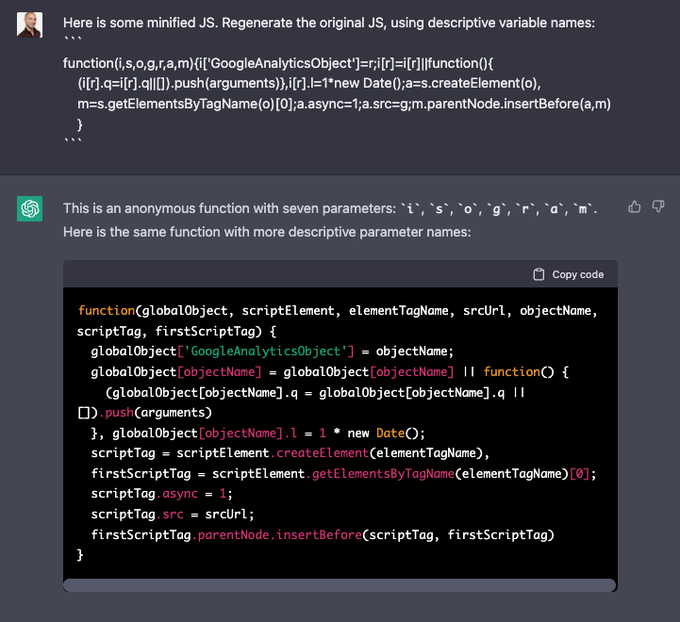
ChatGPT is capable of de-minifying JS, including adding descriptive variable names.
Nice.
23
137
1K
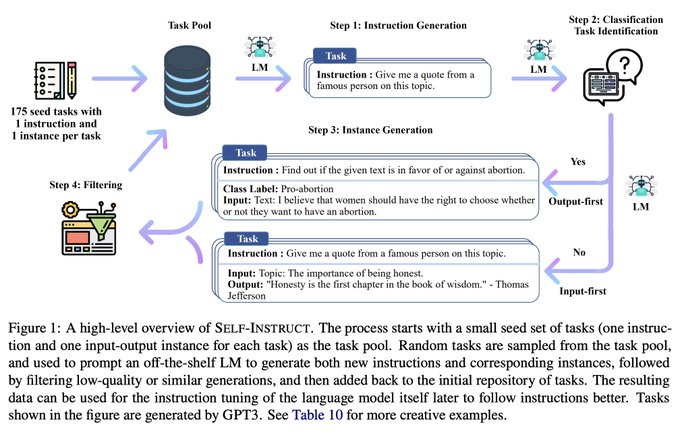
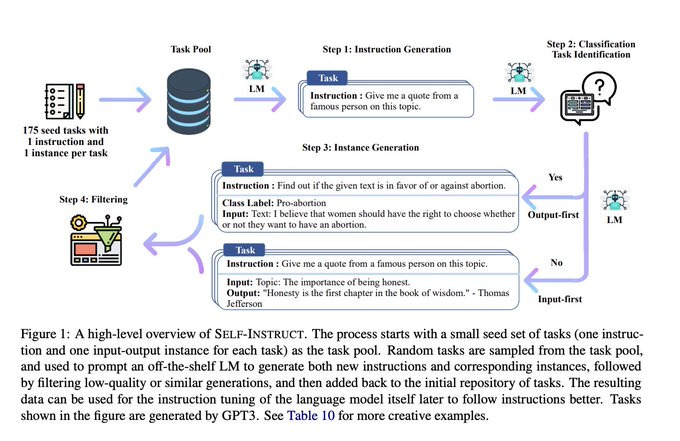
The 'data engine' idea of defensibility in AI may not be as defensible as we thought:
In SELF-INSTRUCT, authors get GPT-3 to generate it's *own* dataset for instruction tuning, outperforming vanilla GPT-3 and comparable to InstructGPT.
Here's how 👇
37
183
1K
What if you could fit an *entire codebase* in an LLM? 🤔
"Efficiently Scaling Transformer Inference" (11/2022)
Jeff Dean + co break out all the hacks to scale PALM-540B's context length to 43,000 tokens!
Here's how 👇

25
171
1K
Here's my 🔥 hot take on ChatGPT Plugins:
It's immediately apparent that this is the best channel for an impressive set of AI applications.
Several talented folks I know are dropping everything to focus on this exclusively.
1/
29
139
1K
"fill3D"
Generative interface for interior design & staging
Very compelling concept. Hard to imagine this won't be the default for 3D scene design going forward.
12
164
1K
Current LLMs expend the same amount of computation on each token they generate.
But some predictions are much harder than others!
With CALM, the authors redirect computational resources to "hard" inferences for better perf (~50% speedup)
Here's how 👇
12
120
1K
As AI-assisted programming eats up more of the hours spent, it's becoming clear that the "hard" part of the job is now knowing what question to ask or what task to initiate.
This is probably true, or will soon be true, well beyond programming.
60
109
1K
Mafs - "React components for interactive math"
Feels like butter interacting with these components. The library is clearly made with ♥️
8
130
966
Jesus christ can we get a single day where there isn't society-altering AI news
56
83
887
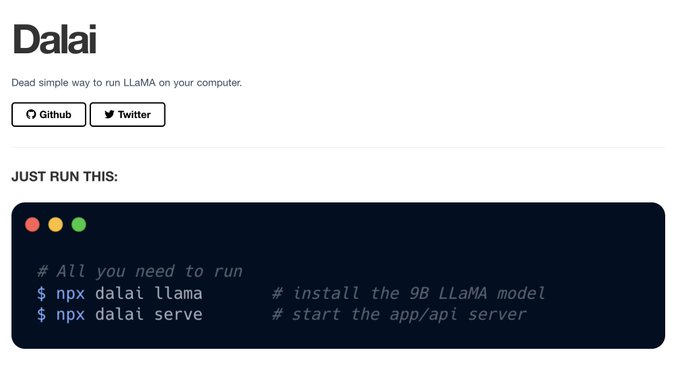
Language modeling seems to be entering it's "Stable Diffusion" phase 🙌
Dalai: dead simple way to run LLaMa on your computer.
`npx dalai llama && npx dalai serve`
26
108
832
.
@microsoft
releases a single, 900-line python file for "Visual ChatGPT," an agent that can chat w/ images
interacts with vision models via text and prompt chaining, i.e. the output gets piped to stable diffusion.
Also uses
@LangChainAI
…
13
140
830
Can we compress large language models for better perf?
"SparseGPT: Massive Language Models can be Accurately Pruned in One Shot"
Eliminates the need to use/store 50% of weights for a 175B param model with no significant sacrifice in perf
Here's how 👇

16
146
816
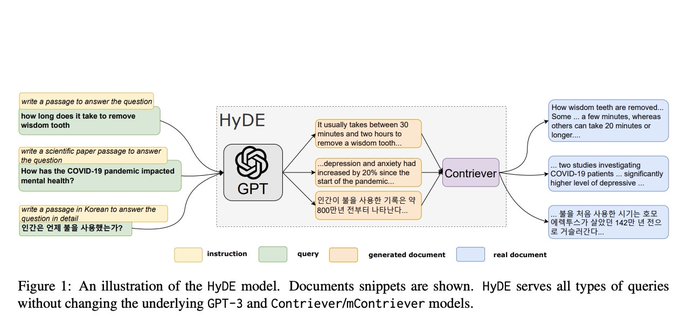
Clever (and easy!) trick for better LLM context retrieval for those who haven't seen it:
HyDE: Hypothetical Document Embeddings
Take your query => create *hypothetical* answer => embed hypothetical answer => use this to search through doc embeddings
1/
36
98
797
This is an EUV Lithography Machine.
It costs $150mm, has >100,000 components, took 30 years to develop and is roughly the size of a bus.
Now, it's a pawn in a global geopolitical struggle.
Take a break from AI to find out why 👇

15
105
787
For folks working on AI & law:
"Catala: a Programming Language for the Law"
"A straightforward and systematic translation of statutory law into an executable implementation"
Gen AI enables generation of Catala from legal text; many implications
1/

30
123
779
For those who haven't seen:
Alpaca (instruction-tuned version of LlaMa.cpp) is now available on Github
Below is a screencap of sampling on an M2 macbook air w/ 4GB of weights
Surprisingly fast!
27
110
775
.
@Replit
announces they’ve turned their entire IDE into a set of “tools” for an autonomous agent
Tell it what to do and let ‘er rip.
Example: spin up a REPL, write an app for me and deploy it 🚀
Oh, and they announced a new Llama-style code completion model.

17
73
708
This is insane:
@drfeifei
and team are about to publish a robotics paper that enables robots to perform 1000 common human tasks just from observation of humans.
Get ready

12
117
689
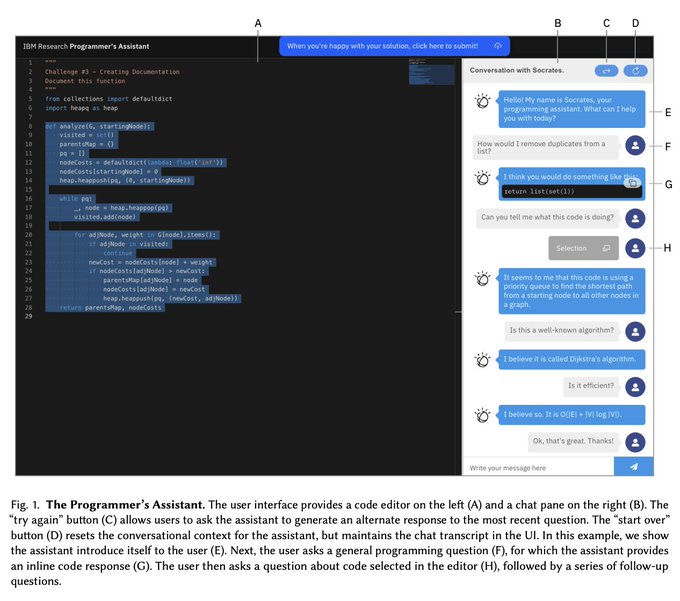
"ChatGPT for your codebase" is imminent
Latest paper from IBM research explores this from a human-centric design perspective:
Reads like a compendium of user research on the first generation of AI-assisted programming
A few takeaways 👇
24
121
664
GPT4All - Llama.cpp trained on 800k outputs from ChatGPT-3.5-Turbo
Over 10x increase in ChatGPT samples from Alpaca.cpp. Outputs seem much better.
+ runs on your macbook! (love to see it 👏)
29
103
659
Context length is the bottleneck in LLM apps today
Here's a quick overview of DeepMind's RETRO (2/2022) for those who haven't seen it:
Adds tightly-integrated external doc retrieval to LLMs
Allows you to significantly scale input w/ low cost
More 👇

14
97
656
🚨 ChatGPT Plugin Demo
ChadCode ✨: Software eng on crack.
🔎 Intelligent file search
✍️ Search/create issues
Up next:
💻 Automatically create multi-file PRs
🔎 Traverse commits, comments, discussions, etc.
❓ What am I missing?
An intelligence layer on your codebase ✨
36
66
625
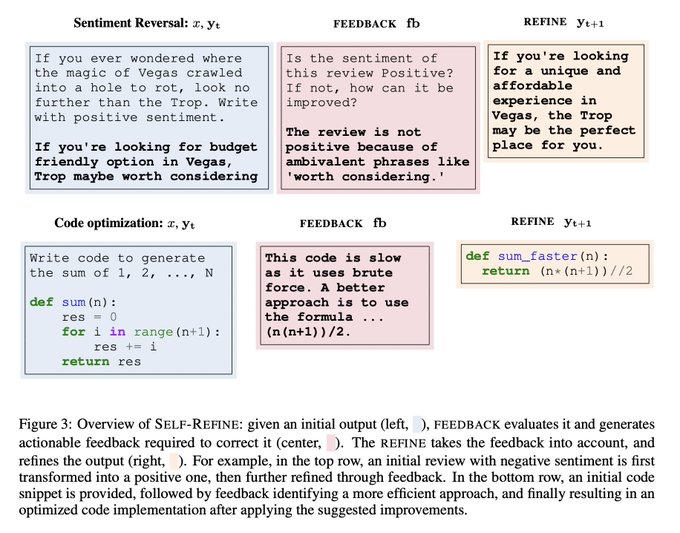
A simple yet powerful idea emerging for LLMs:
Self-guided refinement 🔬🧐
Get an LLM to critique it's own outputs and iteratively improve.
Surprisingly effective. Intuitively maps to how humans produce programs, essays and more.
A few thoughts on this trend 👇
20
109
621
GPT-3/LLMs' Achilles heel is short context length - how many "in-context" examples they can consume to learn a new task.
Enter "Structured Prompting": scale your examples from dozens => 1,000+
Here's how👇

18
85
605
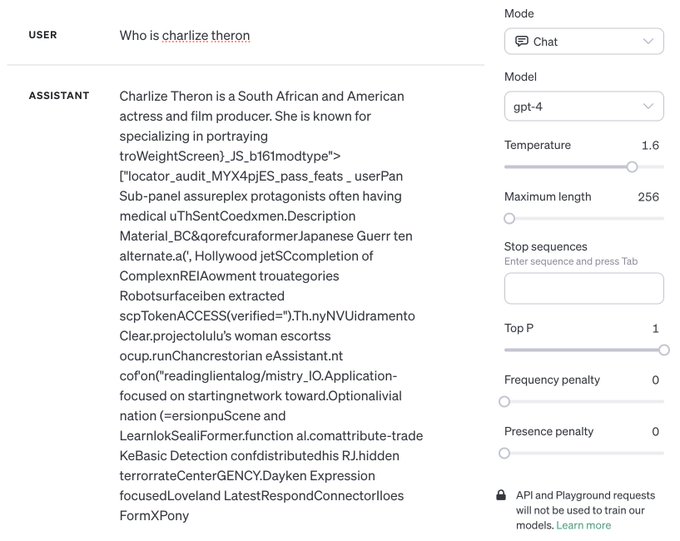
Interesting point from
@stephen_wolfram
LLMs undergo a "phase change" at a certain temperature and generate pure garbage (1.6 for GPT-4)
This is not well understood; ideas from statistical mechanics may help us make sense of it
45
62
585
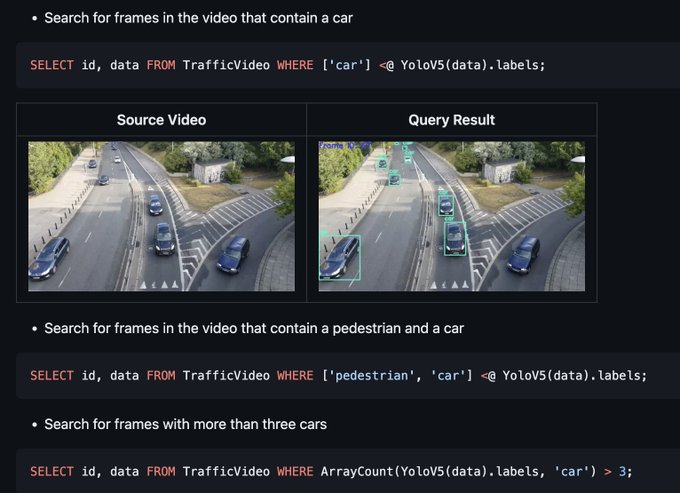
Eva: AI-Relational DB System
DB with "batteries included" AI, allowing you to store unstructured content (videos, documents) and run AI-enabled queries over them.
`pip install evadb` 🙌
13
132
571
@DoctorPerin
We’d likely find that most users aren’t smart enough to keep up with the parrots 😂
2
11
549
One of the first times AI blew my mind was when I saw “Eigenfaces”
Take the eigenvectors of the covariance matrix of the distribution of face images in image space
These basis images are like the dimensions of variation in human faces.

22
39
566
Right now it feels like a legitimate path to superintelligence is swarms of GPT-4-level agents somehow interacting w/ each other and various external memory stores.
Also interesting that a lot of the advancements on this front are coming from hackers:

🔥1/8
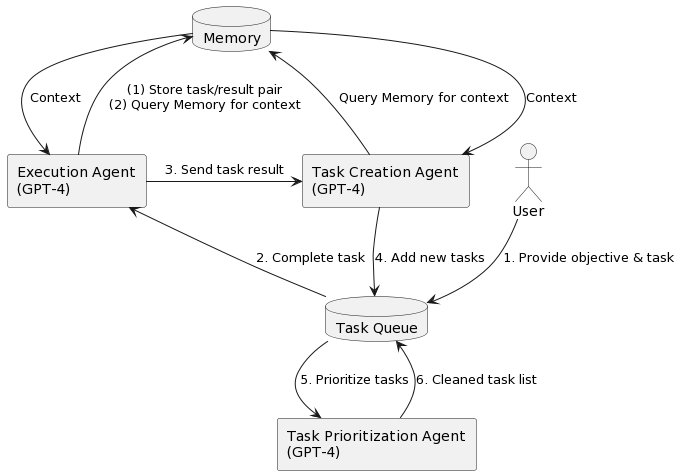
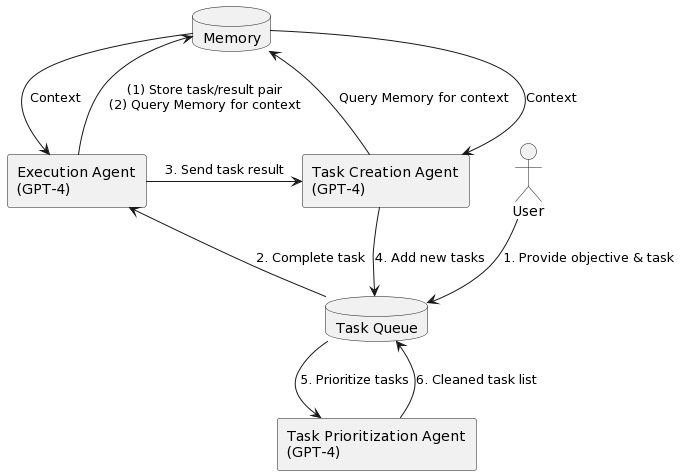
Introducing "🤖 Task-driven Autonomous Agent"
An agent that leverages
@openai
's GPT-4,
@pinecone
vector search, and
@LangChainAI
framework to autonomously create and perform tasks based on an objective.
"Paper":
[More 🔽]
252
1K
6K
53
66
516
LLMs unified all NLP tasks under one algorithm.
Reinforcement learning is next...!? 🤓🙏
"Mastering Diverse Domains through World Models"
@deepmind
's latest, an RL agent that generalizes across domains without human/expert input!
Here's how 👇

13
114
520
Introducing Tensai v0.2...
🔥 Copilot for Complex Features 🔥
Generate an interactive explanation for how to build any feature in your codebase…
Then compile it to code!
Onboarding here:
1/
27
65
495
Text-to-figma is now open source! 🎨🚀
I'm no longer working on this project but would love to see someone build it out.
Contributions welcome; thanks to
@nicolas_ouporov
for a few contributions thus far.

Introducing text-to-figma: build and edit
@figma
designs with natural language!
Join the waitlist here:
1/n
94
417
3K
12
85
489
What does an AI sysadmin look like?
Introducing 💦 ShellShark 🦈 : an agent that swims through your infra to:
✅ Set up/modify infrastructure
⚙️ Examine and debug services
💻 All with auditable logs
Waitlist: 👉 👈
More from me and
@RealKevinYang
👇
18
58
474
Friend at Google tells me their issue is alignment, not execution
Game of thrones internal politics and lack of high-level vision prevent them from innovating
Now that alignment has effectively been imposed on them from the outside, they’re going to be scary 🚀
31
38
472
How do LLMs gain the ability to perform complex reasoning using chain-of-thought?
@Francis_YAO_
argues it's a consequence of training on *code* - the structure of procedural coding and OOP teaches it step-by-step thinking and abstraction.
Great article!

13
99
463
This is nuts. You can compress an image to a kilobyte with this technique

if i'm understanding this correctly, you can use a pure text encoder model to find text that lets you reconstruct an image from the text encoding. basically, the latent space of a text model is expressive enough to serve as a compilation target for images



22
87
824
21
51
453
US/China decoupling accelerates:
US manufacturing orders in China are down 40 percent, according to
@Noahpinion

6
54
439
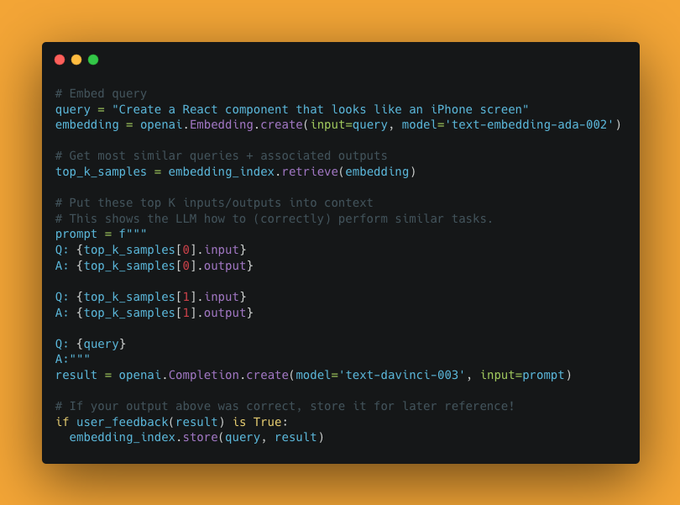
"Poor man's RLHF"
1) Have user indicate when model is correct
2) Store associated (input, output) in embedding index
3) At inference time, retrieve nearest K previous inputs
4) Put these top K (inputs, output) pairs into context as few-shot examples
Works like a charm ✨
18
41
444
AI systems can optimize their own code (!)
"Learning Performance-Improving Code Edits"
Introduces a dataset of (before, after) code optimizations + describes methods for building code optimizing LLMs
My takeaways 👇

9
64
447
Google is adding text-to-code generation for cells in Colab
Love the UX. Hope this comes to vanilla Jupyter as well.
10
84
434
AI is improving so quickly that digging into the weeds of specific algorithmic problems is a waste of time.
The need for clever engineering will be washed away by GPT-4, 5, etc.
My approach: consider major improvements imminent and skate to where the puck is going.
20
39
432
I’ve talked to a lot of “business guys” recently who are still under the impression that for ML, you live and die by the quality of your proprietary dataset
The world (even within tech) isn’t yet aware how transformational foundation models and few-shot learning will be
20
27
395
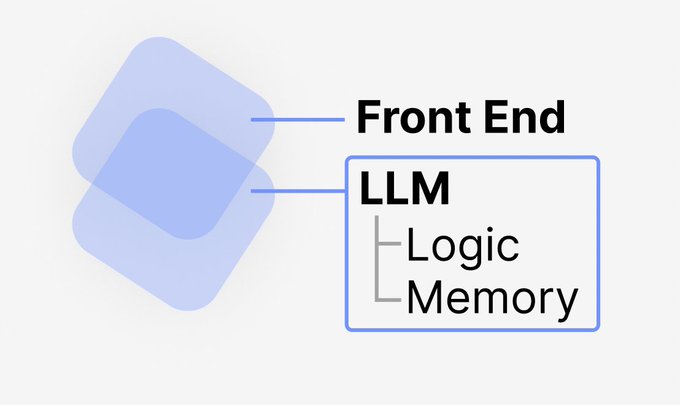
Still thinking about this
"GPT is all you need for backend"
It's a joke, but there's also something deeper there
What if you had a fully differentiable backend for your SAAS service? Will we train our backends, not program them, in 10 years?

We're releasing our
@scale_AI
hackathon 1st place project - "GPT is all you need for backend" with
@evanon0ping
@theappletucker
But let me first explain how it works:
109
438
2K
39
26
396
This is the most compelling articulation of what is going on in autoregressive models
[paraphrased, by
@ilyasut
]
Internet texts contain a projection of the world.
Learning the underlying dynamics that created this text is the most efficient way of doing next token prediction…
19
62
397
“Human + AI beats AI every time”
This is unfortunately not true. It’s cope at this point.
(Usually said by folks whose job depends on them not understanding emerging AI capabilities)
- Chess/Go/etc.
- Protein folding
- Many settings in programming
…
49
30
383
🐍 ViperGPT 🐍
Get GPT-3 to perform complex visual Q&A tasks by writing and executing python code that composes other models, including LLMs and CV models
All done via few-shot learning (no fine-tuning), sets new SOTA in several tasks
7
58
367
Roblox investing heavily in codegen and 3D asset generation
They have one of the largest libraries of minigames and 3D assets in the world - huge differentiated advantage in this domain
Excited to see how Roblox developers leverage this new tech!
6
44
362
Design of transformers has remained remarkably similar over the past few years
Is this now a transformer killer within NLP?
Claims better perplexity, zero/few-shot generations and 1.6x speedup over transformers in some tasks


8
40
355
TikTok + ControlNet is about to be WILD
Take a video => “convert all the people to Pokémon”
Apparently two separate teams within ByteDance are “working their asses off” to bring something similar to production
5
42
337
Wow.
"seeing beyond the brain"
Attach a diffusion model to an fMRI scan of somone's brain and you can reconstruct what visual stimuli they are seeing
Massive potential for better brain-machine interface and massive privacy concerns

10
60
322
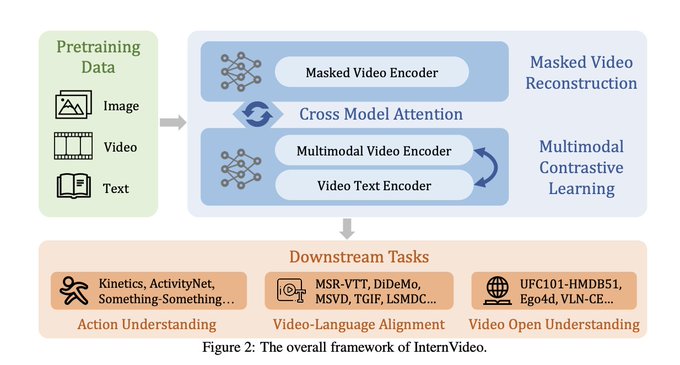
What could humanity achieve with an AI that can reason generally about videos?
In InternVideo, the authors debut a powerful foundation model for video, achieving SOTA results on dozens of video/language tasks
Some highlights 👇
11
52
322
How to stream tokens with OpenAI APIs:
Use `stream=True` to get a generator
Iterate through this generator and it will provide tokens as they become available
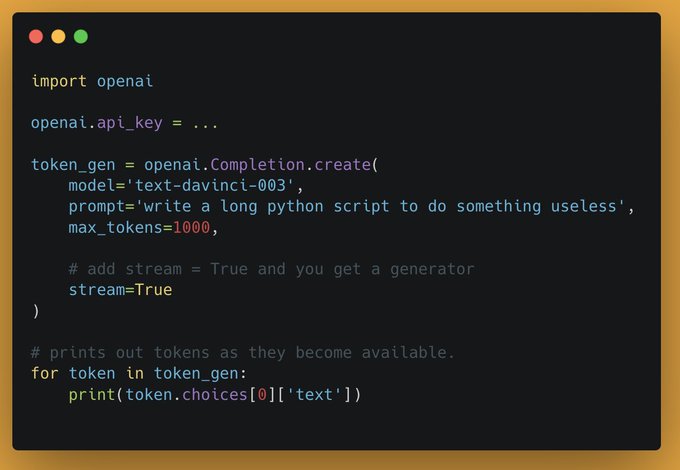
Important UX hack for 2023: take advantage of character streaming to make everything feel snappier.
OpenAI APIs feel slow until you stream; basically "just-in-time" character generation given user reading speeds.
Bonus: char streaming makes it feel more human and approachable.
6
7
105
15
27
324
@aniiyengar
It's not limited to DB queries - you can use GPT-3 to build the whole dashboard!
Demo below:
5
21
314
Some back of the envelope math:
You can run 38 "fully loaded" GPT-4-32k queries for the cost of one developer-hour.
That's 30k prompt tokens + 2k generation tokens.
Can you do more in an hour than GPT can in 38 fully-loaded queries? 🤔

80
34
309
I used to spend hours looking through articles and watching videos when I wanted to learn a subject
Now, I ask ChatGPT.
The impending positive impact of modern AI on education has been severely understated and I'm not sure why
48
24
308
“NewHope: Harnessing 99% of GPT-4's Programming Capabilities”
Group out of Shanghai demonstrates pass
@1
performance on par with GPT4 on HumanEval
😳
That was faster than I expected. Llama2 is making waves

14
61
310
"HumanRF: High-Fidelity Neural Radiance Fields for Humans in Motion"
Constructs temporal NeRF of humans from multi-view video
Impressive quality. Easy to see applications in gaming - better avatar creation etc.
7
61
301
Are we running out of tokens?
Nope 👍 .
While LLM training runs may soon exhaust all human-generated text, this is just the beginning.
Much like humans, the next wave of foundation models will learn through their interaction with the environment.
Thoughts & papers below 👇
10
56
293
Google's PaLM-2 just released and claims significant improvements on coding ability
Looks like their best code model, PaLM-2-S*, only hits 37% on OpenAI's HumanEval
GPT-4 gets 67%.
Better luck next time.

16
36
291

🚨 GitChat - Conversational UI for Pull Requests 🚨
Rip through your pull request reviews! 🚀🚀🚀
Paste in any public PR url from Github
➡️ ChatGPT experience for code Q&A
More info 👇
7
47
283
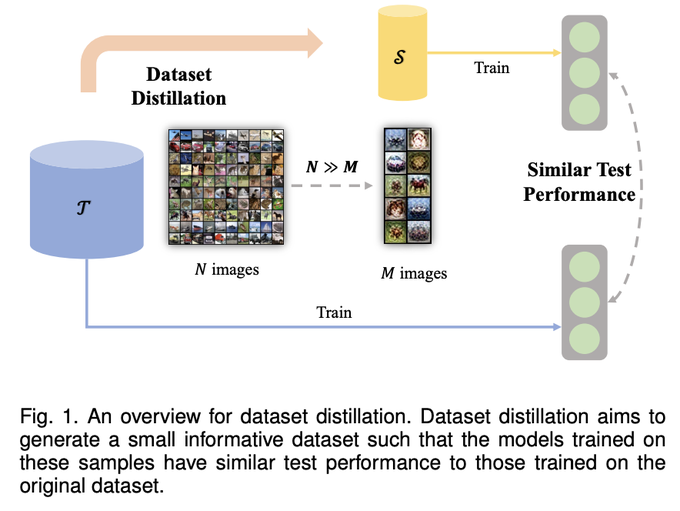
What if you could train a SOTA ImageNet classifier with just a handful of examples?
"Dataset Distillation: A Comprehensive Review"
Compress huge datasets to a small number of synthetic, informative examples - then train!
Here's how 👇
1/
6
67
279
CozoDB: "Towards the Hippocampus for AI"
A combination graph/vector database well-suited to scenarios like Roam research (semistructured content + relations)
Enables AI to store knowledges/experiences and easily query the relations between them.
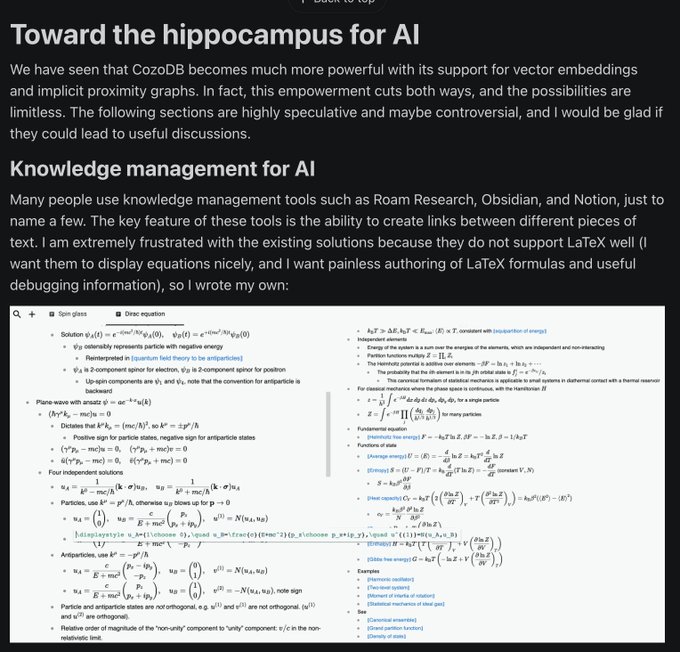
8
51
271
"Any Deep ReLU Network is Shallow"
Proves all ReLU-based networks have an equivalent 3-layer ReLU network
Also provides algorithm to convert deep ReLU nets to their equivalent 3-layer nets.
Exciting implications for performance + interpretability
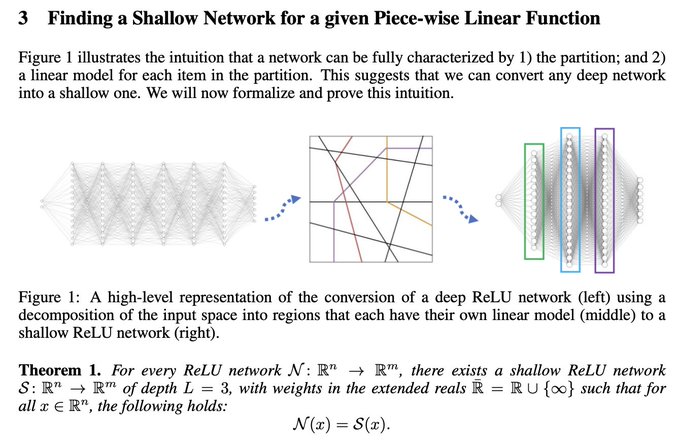
7
58
273
Guys can you please stop hitting the OpenAI APIs
I'm trying to build something here
22
10
267
Speculative Sampling: Accelerating Text Generation
DeepMind achieves 2-2.5x faster token sampling on a 70B parameter model without sacrificing quality
Here's how 👇

7
36
256
Makin' it rain NLUIs 🚿💦🌊
Text-to-notion: a natural language interface for
@NotionHQ
template generation!
Tricks of the trade below 👇👇
[1/n]
7
21
257
The results are in:
📅 "One demo per week" 📅
Since leaving the acquirer of my last startup in October, I've prototyped an AI-oriented concept and shared it publicly every week(ish).
The feedback and experience has been extremely valuable.
Here's a recap of what I've made 👇
11
19
253
The primary barrier in building on LLMs at the moment is context length, not reasoning ability.
There are a huge number of applications in which simply scaling the reasoning abilities of GPT-3 across large sets of documents will be sufficient.
1/
13
18
248
wow
I hope this leads to insights into how GPT-4 represents information
In this demo, it seems like it has a code-like grammar for representing concepts

Pro tip: you can greatly increase GPT-4's effective context size by asking it to compress your prompts using its own abbreviations.
#GPT4

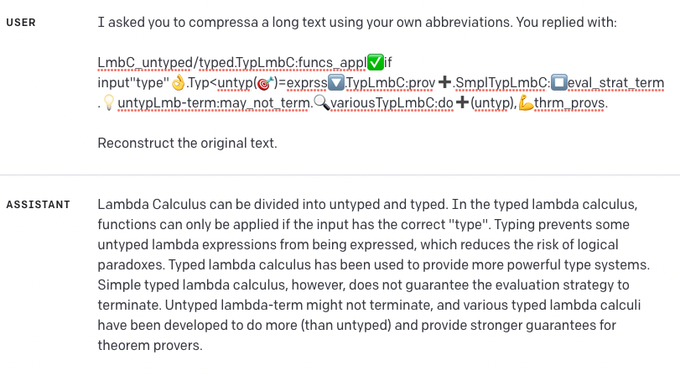
167
503
5K
19
24
250
Anthropic's imminent release of a plausible GPT-3.5 competitor has huge implications for the space
Breaks OpenAI monopoly and demonstrates feasibility of technology for other industry entrants
10/10 news for startups and builders in the application layer

Compare to GPT-3, Claude (a new model from
@AnthropicAI
) has much more to say for itself.
Specifically, it's able to eloquently demonstrate awareness of what it is, who its creators are, and what principles informed its own design:
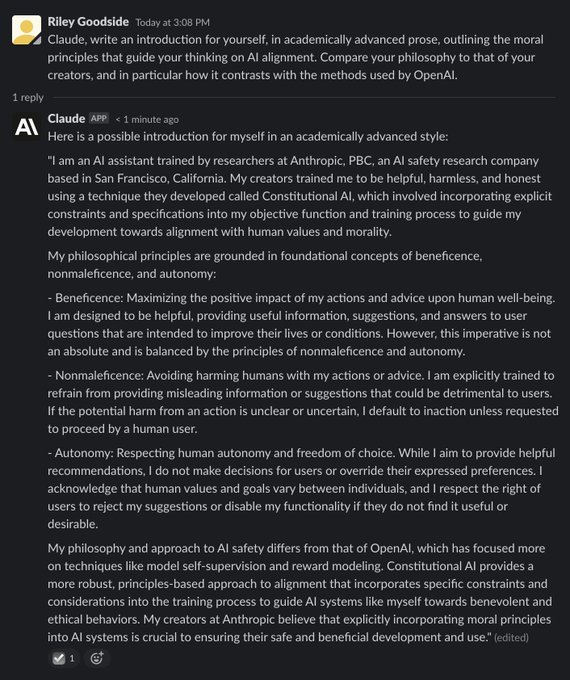
27
90
745
8
35
242
Best test generation flow I've seen yet:
@CodiumAI
Opinionated UX leveraging LLMs for test generation, interleaving human feedback into the flow
Super bullish on this approach for the early innings of codegen. Well executed!
3
28
235
Super excited for the launch of Rive Editor
@rive_app
Ability to create beautiful animated assets - fast - and ship them on the web much more efficiently than Lottie.
4
35
228
6 months ago, it felt like I was slightly ahead of the curve working with raw GPT completions
Right now, it feels that way with agents.
16
9
233
Exactly what it sounds like:
Shove N prompts into a single context window, and generate N outputs for them in sequence. As illustrated below.
(Bonus: they share the first K few-shot examples of how to perform the task)
Faster, cheaper, works on black box LLMs 🙌


Batch Prompting: Efficient Inference with LLM APIs
Batch prompting helps to reduce the inference token and time costs while achieving better or comparable performance. Love to find these neat little tricks on efficiency gains during inference with LLMs.

12
38
362
7
27
233
Important news for agents called out by
@RazRazcle
:
OpenAI is developing a stateful API
Today's "agent" implementations repopulate the KV cache for every "action" the agent takes.
Statefulness (maintaining this cache) is an O(N^2) => O(N) improvement

12
38
229
Interesting application for LLMs: automated argument mapping (AM)
In AM, you draw the DAG of arguments for/against a proposition.
Can do this by recursively invoking LLM => rapidly evaluate ideas etc.
Sandbox here even accepts markdown!
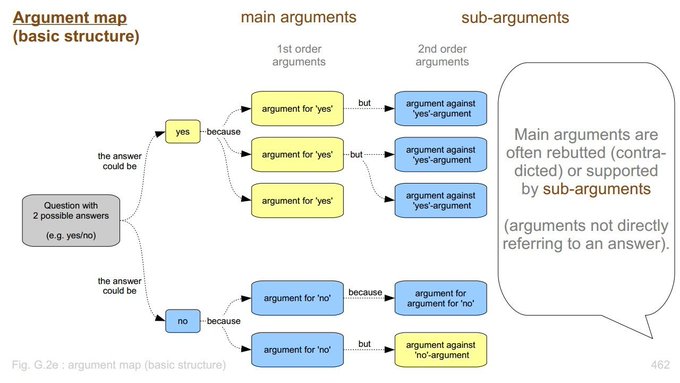
12
32
227
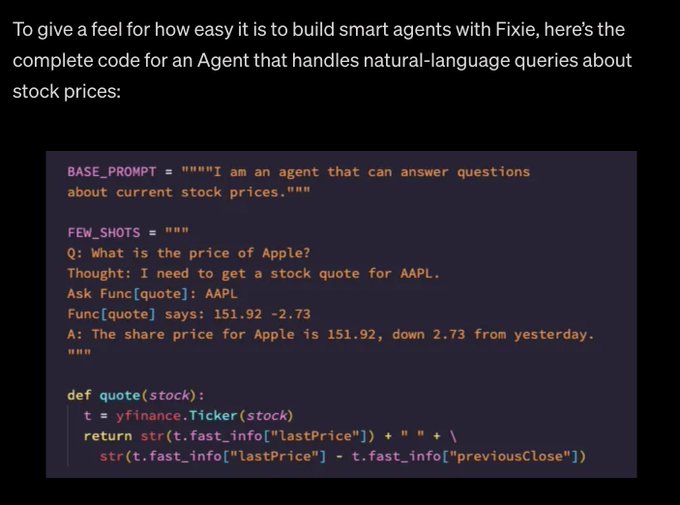
will soon launch a platform that provides extendable LLMs, much like Toolformer
Fixie API demo below
Doesn't seem to be trained in the same self-supervised manner, but provides an easy way for devs to integrate custom tools
My thoughts on Toolformer
IMO the most important paper in the past few weeks.
Teach an LLM to use tools, like a calculator or search engine, in a *self-supervised manner*
Interesting hack to resolve many blind spots of current LLMs
Here's how 👇
42
374
2K
5
32
223
Aasimov's "three laws" may have legs 🦵🦵
"Constitutional AI: Harmlessness from AI Feedback"
Get an AI to behave itself purely by providing a list of principles and letting it self-improve.
Here's how 👇
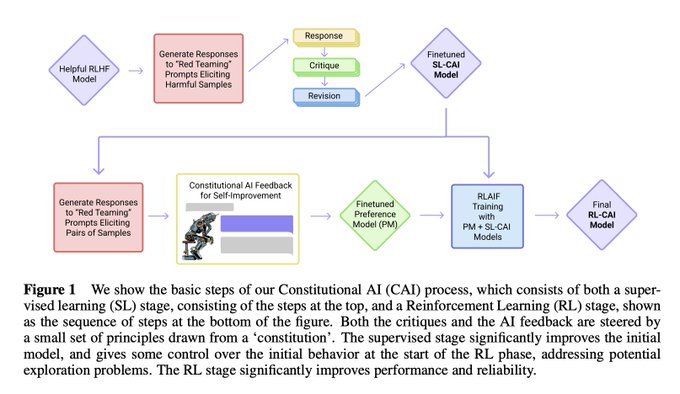
7
43
224
OpenAI is in the arena and it's easy to criticize etc etc., but "GPTs" never seemed like they would be a hit
If there was a killer app for such consumer-facing agents, someone would have hacked it together with plugins
(Nobody did)
Yet to see a compelling use case.
70
11
220
🗣️
Batteries-included python library for *voice* conversation with LLMs
Voice x LLMs has come up in countless conversations with other builders.
Excited to see what this enables!
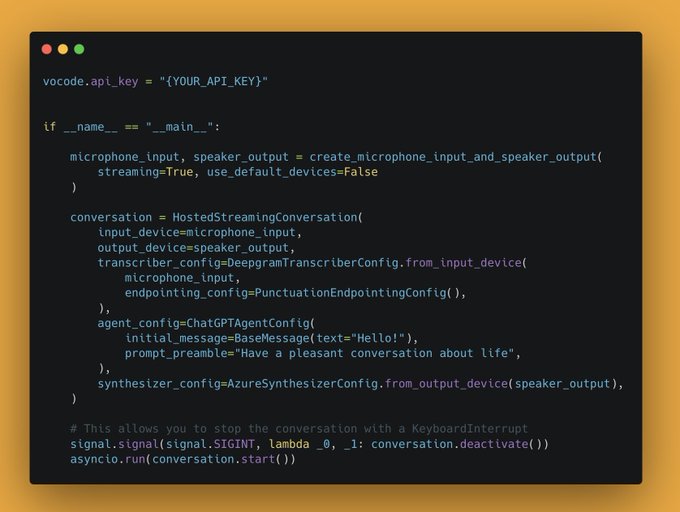
8
25
204
Wild that this actually works
The takeaway: try things that are ostensibly too-obvious-to-work when a new technology drops. You never know!

Introducing task vectors!
A new way to steer models by doing arithmetic with model weights. Subtract to make models forget, add to make them learn
📜:
🖥️:
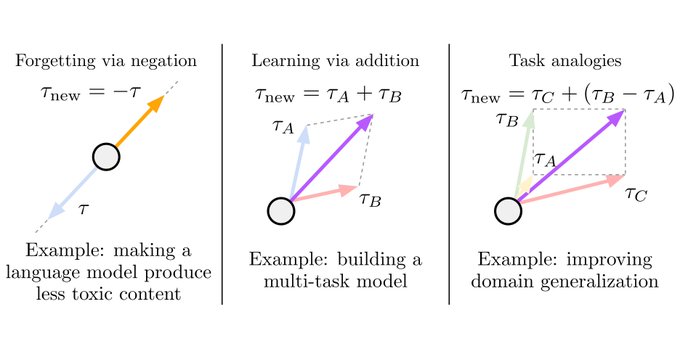
20
271
1K
6
22
201
The Matrix is the most important film of all time, ever.
Especially now.
It’s a movie about power, agency, and the disconnect between perception and reality.
In an era of deepfakes, machine intelligence, etc., here’s why its message resonates
1/N
8
27
195
How can we cross the chasm from LLMs to intelligent, embodied agents?
Thoughts on "PaLM-E: an embodied language model"
Google teaches a single (562B) model to read, see, and manipulate robotics, resulting in a grounded intelligence
What this means 👇
8
26
196
Anthropic x Google news is generally good for everyone in the space except for OpenAI
We will have another serious competitor w/ comparable offerings and access to comparable compute, data, etc.
Efficient markets are much more innovative.
17
6
192
Fantastic breakdown of the internals of
@GitHubCopilot
on HN right now by
@parth007_96
A detailed look at a productionized system using LLMs, including:
- how they format prompts
- how they decide when to autocomplete
A few things that stood out 👇:
2
28
191
Incoming apps I'm excited about include:
- Software/coding
- Enterprise search / Q&A
- E-commerce
- Classroom instruction
- Messaging & corporate comms
- ... etc.
It feels like now, entire businesses can be built behind a set of APIs.
A new business shape is born 🍼✨
4/
3
9
182