
말러팔삼
@mahler83
Followers
14K
Following
22K
Media
9K
Statuses
74K
배우는 것과 가르치는 것을 좋아하는 골수이과. 트위터에서의 인격과 현실에서의 인격은 별개입니다. 연구자를 위한 LLM 강의: https://t.co/Ex6kLgbR9T LLM파이썬 강의: https://t.co/dVOghJIa3F
부산
Joined November 2009
2025년 목표.- 번아웃 되지 말기.- 논문 10편.- 유튜브 영상 1달에 2개씩.- 빅데이터분석기사: 필기(4/5) 실기(6/21).- 듀오링고 365일.- 샐러드, 운동 기록하기.- LLM 활용한 자동화 기능 만들어보기.
7
12
204


Opus가 멍청해진 것 같다는 트윗을 좀 봤었는데 진짜였을 줄이야. inference stack이라는거 보니까 routing을 하거나 최적화(quantization) 시킨걸 적용했던거 아닐지. API endpoint를 변화를 허용하는 것과 그렇지 않은 것으로 나눠주는 건 안되나

1
10
24

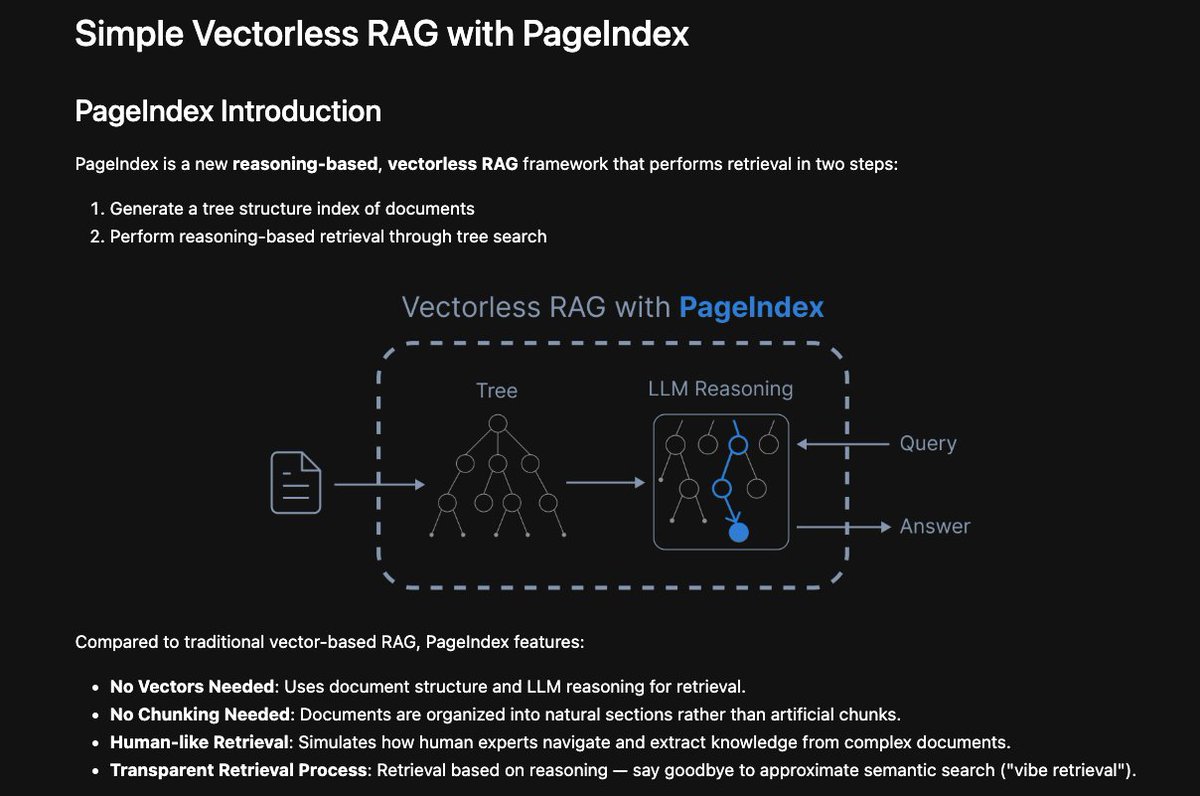
우리 연구실에 knowledgebase를 만들면서 이런 방식을 도입할까 고민중. 기존의 RAG는 문서를 조각내서 벡터 유사도를 이용해 관련 내용을 가져오는데, similarity≠relevance라는 한계가 있음. 여기는 문서 구조 기반으로 추론해서 관련성 있는 내용을 가져옴.

RAG is not dead!. However, we are in an interesting phase of exploring unique ways to index and retrieve information. This vectorless RAG framework uses a tree structure index in place of vectors. Reasoning models will enable methods that mimic human-like search. Early days!
1
10
36
36/20 오늘 양자컴퓨팅 관련 웨비나를 듣고 궁금한거 찾아본 내용을 바탕으로 챗봇을 이용해 리뷰아티클을 만들고 그걸로 AO생성. 머신러닝을 경험한 의과학 연구자 입장에서 딱 궁금한 범위까지 확장한거라 들으면서 조깅하는데 황홀하다는 느낌까지 받았다. 양자쪽도 손을 대볼까 싶어지네


0
0
0

그런데 이런 추세가 이미 변곡점을 지나버려서 예전처럼 virtue에 의존해 굴러가는 건 불가능할텐데. 내가 죄인도 아닌데 왜 이런 고민을 하고 앉아있어야 하나 좀 억울하다.
0
1
11
의사과학자 과정에 4~5명씩 학��을 교수님들이 맡아서 학기 내내 지도해야 하는데 보통 10~15분 정도 지원하고(교육업적 높음) 나머지는 주위에 읍소해 인원을 채워왔다. 그런데 이번에 2학기 시작하면서 모집했는데 지원자가 1명. 나도 부책임 안 맡고 싶다🫠🫠🫠 모든 책임을 지고 물러나는 걸로.
2
2
27
orcid에 대해 문득 궁금해서 검색해봄. 2012년 10월에 개시되었네. 생각보다 얼마 안 됐음. 그 즈음에 유행처럼 연구실에서 다들 만들었던 기억이 난다. 생긴지 얼마 안 된 시기였구나.
1
0
4

sklearn 라이브러리 이용한 초식 몇 개만 알면 논문 쓸 수 있는 것처럼, 파울리게이트가 뭔지 몰라도 오늘 소개된 qiskit 라이브러리 예제 보고 공부해서 클라우드로 연습하고 있으면 기회가 올지도? ML 막 유행할 때 예측모델 만들어서 정확도만 보여도 논문이 되던 시절처럼.
0
1
0
의생명 연구자 입장에서는 ML모델이 어떻게 돌아가는지 몰라도 데이터 클리닝하고, 변수선택하고, nested cross validation 같은거 잘 설계하고, hyperparameter tuning좀 해주고, XAI 좀 적용해주고 하면 논문 쓸 수가 있었는데, "양자컴퓨팅" 활용 연구도 마찬가지 아닐까 싶다.
1
2
1
디지털 데이터의 차원수가 올라가면(multi-omics 같은거) 이걸 가지고 고전ML 모델을 돌리면 matmul같은게 연산수가 너무 많아짐. Qbit으로 변환해서 양자연산을 하는게 더 효율적일 수 있음(하드웨어 구현이 제대로 된다면) 내 이해가 맞다면 수백개 입력변수 정도는 굳이 양자컴 안 써도 됨.
1
0
0
training: 디지털정보 → 엠베딩 → 큐빗 representation → 양자연산 노가다로 학습 → 양자 예측모델이 만들어짐.inference: 디지털정보 → 엠베딩 → 큐빗 → 학습된 양자모델로 연산 → 출력은 관측하면서 양자상태가 깨지며 0-1 probability 형태로 나타남.
1
1
1
퀀텀정보는 n개의 Qbit이 있으면 2^n차원 힐버트공간(청춘돼지 시즌2 7화)이 만들어짐. QPU에 큐빗숫자 하나 올라갈때마다 다룰 수 있는 정보 크기가 제곱으로 커짐. 정보 해상도가 높아지는걸로 이해하면 되려나?.디지털 입력정보는 보통 벡터/행렬일텐데, 이걸 Qbit으로 엠베딩하는 과정이 필요.
1
0
2
양자컴퓨팅은 2진수 비트가 아니라 퀀텀상태 Qbit을 이용해서 중첩/얽힘/간섭 기반의 연산(뭐시기 게이트 하는 것들)을 하는 시스템. 데이터 형태가 다르기 때문에 디지털 입력 정보를 Qbit으로 변환하는 선과정이 필요. 그 퀀텀 연산들을 이용하는 모델을 학습시켜서 예측을 잘하게 만드는 건 동일.
1
0
1