

Kevin Frans
@kvfrans
Followers
4K
Following
785
Media
149
Statuses
488
@berkeley_ai @reflection_ai prev mit, read my thoughts: https://t.co/7CZsOTrKRA
Berkeley, CA
Joined August 2013
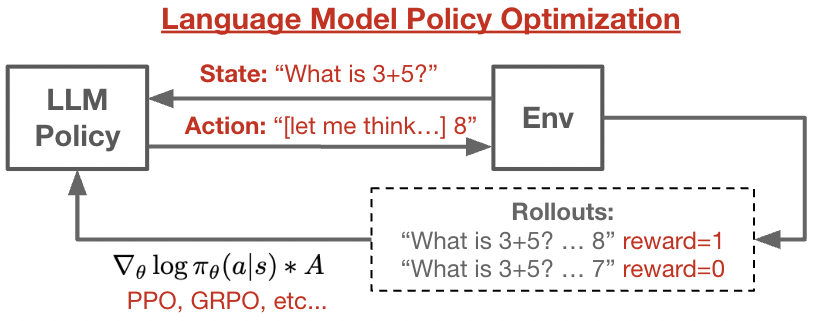
LLM RL code does not need to be complicated! Here is a minimal implementation of GRPO/PPO on Qwen3, from-scratch in JAX in around 400 core lines of code. The repo is designed to be hackable and prioritize ease-of-understanding for research:
11
44
446
Code understanding agents are kind of the opposite of vibe coding -- users actually end up with *more* intuition. It's also a problem ripe for multi-step RL. Contexts are huge, so there's large headroom for agents that "meta" learn to explore effectively. Exciting to push on!.

Engineers spend 70% of their time understanding code, not writing it. That’s why we built Asimov at @reflection_ai. The best-in-class code research agent, built for teams and organizations.
3
6
74
RT @seohong_park: Flow Q-learning (FQL) is a simple method to train/fine-tune an expressive flow policy with RL. Come visit our poster at….
0
65
0
This is a great investigation, and it answers the itch that often comes up when using gradient accumulation -- why not just make more frequent updates? The answer is that you need to properly scale the b1/b2 settings too!.

🚨 Did you know that small-batch vanilla SGD without momentum (i.e. the first optimizer you learn about in intro ML) is virtually as fast as AdamW for LLM pretraining on a per-FLOP basis? 📜 1/n

2
0
15
There's a small section in the README giving an overview of typical LLM RL systems. In general, it's the same as a classical RL loop, except we need to put extra care about policy sampling since that's the main compute bottleneck.
0
0
2
- Everything is JIT compiled, so training is decently fast, but probably not quite as efficient as e.g. vllm sampling backend. - Multi-host and FSDP sharding works out of the box (single-host works fine too). - Only bandit environments for now.
1
0
3
The main goal here was to minimize external dependencies, so the model + sampling code is all there to read. The only thing I couldn't figure out how to replicate is the HF tokenizer, if anyone knows how, please let me know. .
1
0
3
RT @kevin_zakka: We’re super thrilled to have received the Outstanding Demo Paper Award for MuJoCo Playground at RSS 2025!.Huge thanks to e….
0
21
0
RT @N8Programs: Replicated in MLX on MNIST. S+ is an intriguing optimizer that excels at both memorizing the training data and generalizing….
0
6
0
Thanks to my advisors @svlevine and @pabbeel for supporting this project, that is not in my usual direction of research at all. And thank you to TRC for providing the compute!. Arxiv: Code:
github.com
Contribute to kvfrans/splus development by creating an account on GitHub.
2
2
34
We tried out best to make SPlus easy to use, so please try it out! You can swap from Adam in just a few lines of code. The JAX and Pytorch implementations are single-file and minimal. Let me know how it goes :). Repo:
github.com
Contribute to kvfrans/splus development by creating an account on GitHub.
3
1
54
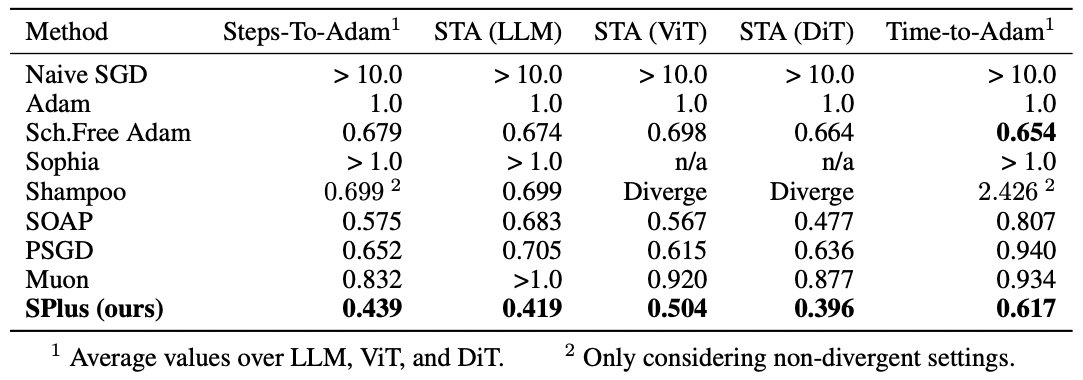
We ran an extensive comparison to previous optimizers. Focusing on a common transformer backbone, we trained on three objectives (language modelling, diffusion, image classification), and examined performance at different training stages. SPlus outperforms across the board.
5
2
35
The techniques we used in SPlus are simple, but they work! We intentionally focused on empirically practical ideas. The overall SPlus algorithm is stable to use, and generally works out-of-the-box for training transformers.

2
2
30
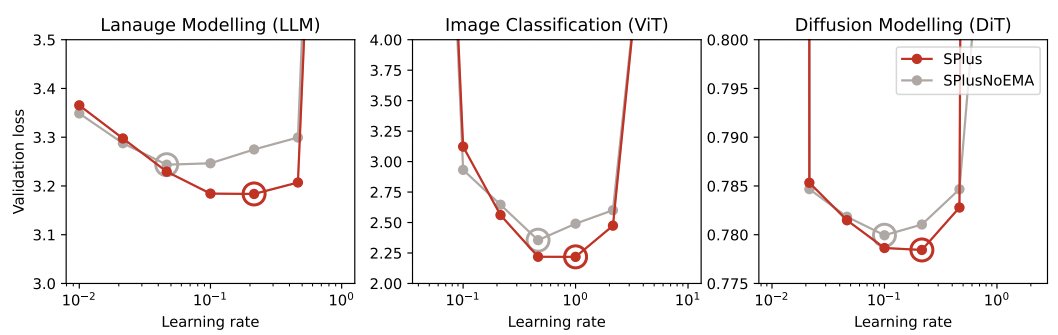
Whitening-based optimizers introduce nontrivial parameter noise, which harms validation loss. To reduce the harmful effects on performance, SPlus employs a simple iterate-averaging scheme. This lets us use a higher LR without degradation.
3
2
24
Optimal learning rates for SPlus can transfer across width (like muP). We achieve this through a symmetric scaling factor which we found to perform better than directly bounding the spectral norm.

1
2
28
We found that naive Shampoo is quite brittle, and diverges easily, especially when factors are cached for > 10 steps. In contrast, SPlus updates remain stable at 100+ steps, which is crucial for getting faster wall-clock time than Adam.

1
2
28
SPlus builds on the Shampoo family of algorithms, which can be seen as performing gradient descent on a "whitening" distance metric. Adam does this too, but uses a diagonal approximation. Using a full whitening scheme allows for faster learning.

1
1
39
Very excited for this one. We took a cautiously experimental view on NN optimizers, aiming to find something that just works. SPlus matches Adam within ~44% of steps on a range of objectives. Please try it out in your setting, or read below for how it works.

36
88
637
I really liked this work because of the solid science. There are 17 pages of experiments in the appendix… . We systematically tried to scale every axis we could think of (data, model size, compute) and over 1000+ trials found only one thing consistently mattered.

Is RL really scalable like other objectives?. We found that just scaling up data and compute is *not* enough to enable RL to solve complex tasks. The culprit is the horizon. Paper: Thread ↓
0
3
39
Cool ideas from Yifei, who generally has great sense on building these self-improving systems.

📢 New Preprint: Self-Challenging Agent (SCA) 📢. It’s costly to scale agent tasks with reliable verifiers. In SCA, the key idea is to have another challenger to explore the env and construct tasks along with verifiers. Here is how it achieves 2x improvements on general
1
3
23