
Kenny Peng
@kennylpeng
Followers
176
Following
119
Media
28
Statuses
78
CS PhD student at Cornell Tech. Interested in interactions between algorithms and society. Princeton math '22.
New York, NY
Joined July 2019

🚨 New postdoc position in our lab @Berkeley_EECS! 🚨 (please retweet + share with relevant candidates) We seek applicants with experience in language modeling who are excited about high-impact applications in the health and social sciences! More info in thread 1/3

7
46
154

1/10. In a new paper with @didaoh and Jon Kleinberg, we mapped the family trees of 1.86 million AI models on Hugging Face — the largest open-model ecosystem in the world. AI evolution looks kind of like biology, but with some strange twists. 🧬🤖
4
9
51
How do we reconcile excitement about sparse autoencoders with negative results showing that they underperform simple baselines? Our new position paper makes a distinction: SAEs are very useful for tools for discovering *unknown* concepts, less good for acting on *known* concepts.


📢NEW POSITION PAPER: Use Sparse Autoencoders to Discover Unknown Concepts, Not to Act on Known Concepts Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵

0
0
2
🌟 HypotheSAEs update: open LLMs now supported for the full hypothesis generation pipeline! Labeling SAE neurons and annotating concepts works very well with Qwen3-8B and larger models ⬇️ (notably, other models didn't work as well). Brief 🧵

2
5
22
One paragraph pitch for why sparse autoencoders are cool: Text embeddings capture tons of information, but individual dimensions are uninterpretable. It would be great if each dimension reflected a concept (“dimension 12 is about cats”). But text embeddings are ~1000 dimensions
0
0
10

The mainstream view of AI for science says AI will rapidly accelerate science, and that we're on track to cure cancer, double the human lifespan, colonize space, and achieve a century of progress in the next decade. In a new AI Snake Oil essay, @random_walker and I argue that
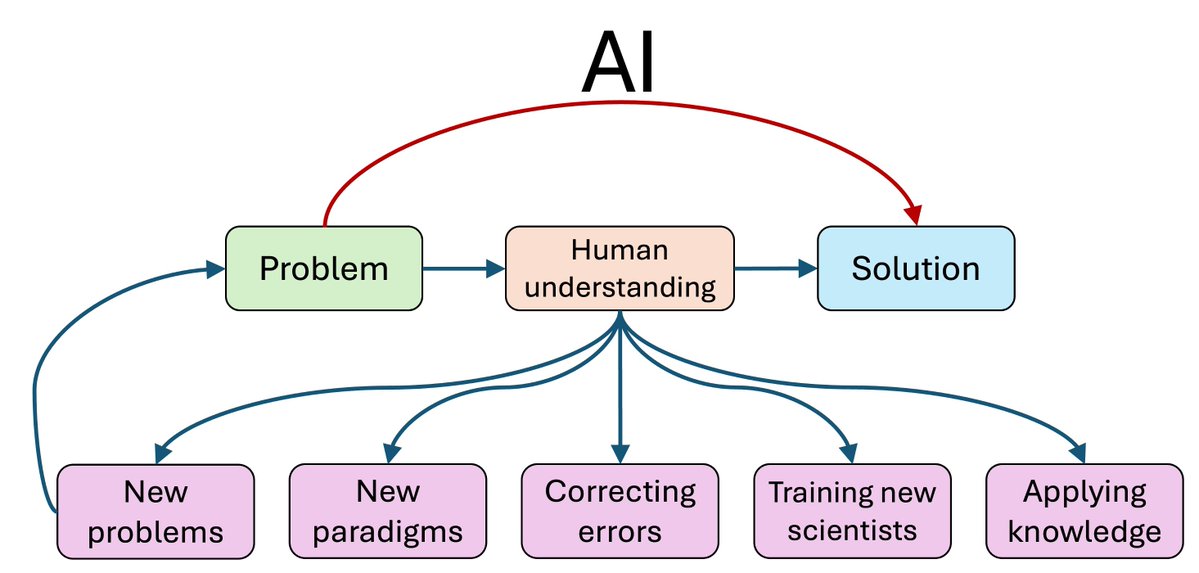
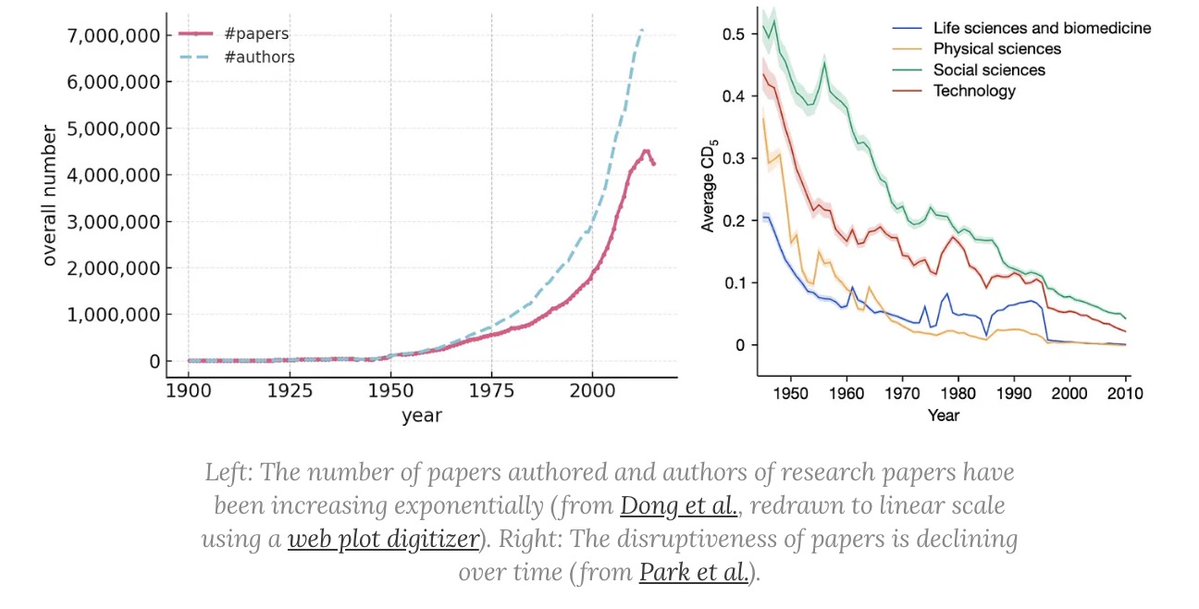
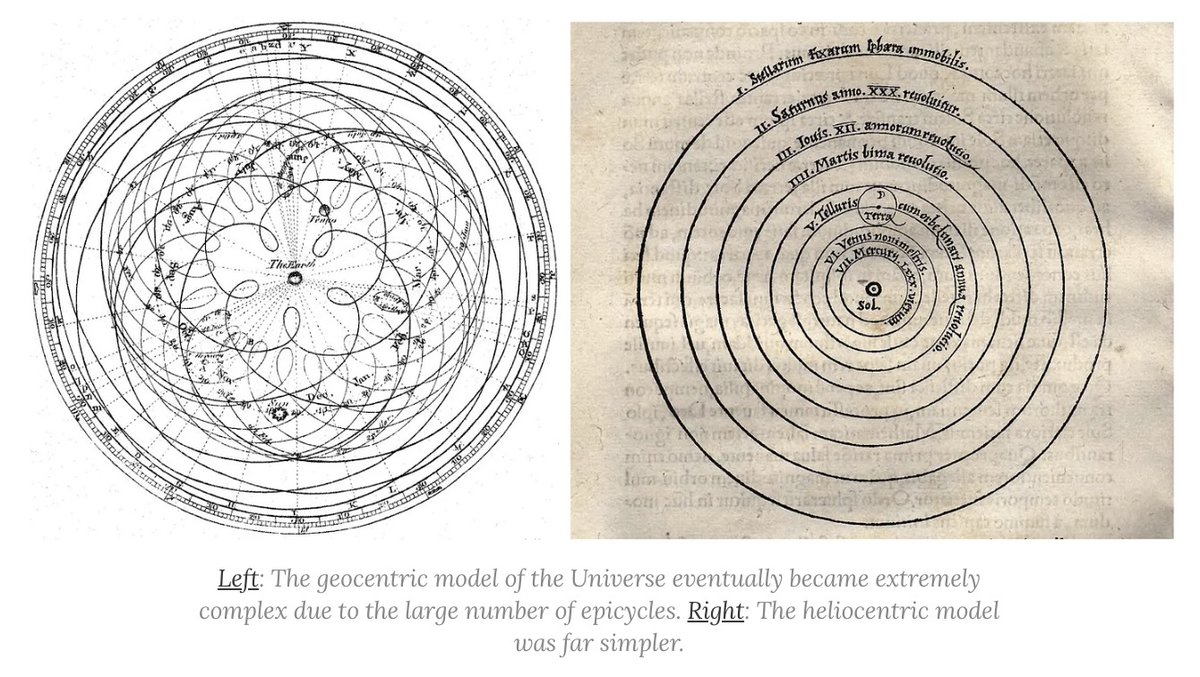
12
65
235
I've resolved this positively: 2 papers convincingly show sparse autoencoders beating baselines on real tasks: Hypothesis Generation & Auditing LLMs SAEs shine when you don't know what you're looking for, but lack precision. Sometimes the right tool for the job, sometimes not.


Manifold Market: Will Sparse Autoencoders be successfully used on a downstream task in the next year and beat baselines? Stephen Grugett asked me for alignment-relevant markets, this was my best idea. I think SAEs are promising, but how far can they go? https://t.co/LW9hUUmD1p
6
18
207
In Correlated Errors in Large Language Models, we show that LLMs are correlated in how they make mistakes. On one dataset, LLMs make the same mistake 2x more than random chance. (w/ Elliot Kim, Avi Garg, @NikhGarg)

0
1
2
In Sparse Autoencoders for Hypothesis Generation, we show that SAEs can be used to find predictive natural language concepts in text data (e.g., that "addresses collective human responsibility" predicts lower headline engagement), achieving SOTA performance and efficiency. (w/

1
1
3
We're presenting two papers Wednesday at #ICML2025, both at 11am. Come chat about "Sparse Autoencoders for Hypothesis Generation" (west-421), and "Correlated Errors in LLMs" (east-1102)! Short thread ⬇️


1
3
6


The empirics here also add nuance to theory. While less correlated models can be more accurate together through a “wisdom of crowds,” this effect doesn't hold when newer, more correlated models are adopted in our simulations: gains from individual accuracy outweigh losses from

1
1
5
However, in equilibrium, increased correlation—as predicted by past theoretical work—actually improves average applicant outcomes (intuitively, of the applicants who receive a job offer, more correlation means they will get more offers). For the theory, see

1
0
7
Since LLMs are correlated, this also leads to greater systemic exclusion in a labor market setting: more applicants are screened out of all jobs. Systemic exclusion persists even when different LLMs are used across firms. (4/7)

1
1
9
A consequence of error correlation is that LLM judges inflate accuracy of models less accurate than it. Here, we plot accuracy inflation against true model accuracy. Models from the same company (in red) are especially inflated. (3/7)

1
1
10
What explains error correlation? We found that models from the same company are more correlated. Strikingly, more accurate models also have more correlated errors, suggesting some level of convergence among newer models. (2/7)

1
1
11
Are LLMs correlated when they make mistakes? In our new ICML paper, we answer this question using responses of >350 LLMs. We find substantial correlation. On one dataset, LLMs agree on the wrong answer ~2x more than they would at random. 🧵(1/7)

8
48
210
We'll present HypotheSAEs at ICML this summer! 🎉 We're continuing to cook up new updates for our Python package: https://t.co/iShDUUNxld (Recently, "Matryoshka SAEs", which help extract coarse and granular concepts simultaneously without as much hyperparameter fiddling.)

github.com
Hypothesizing interpretable relationships in text datasets using sparse autoencoders. - rmovva/HypotheSAEs
💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets. Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
0
4
34