
Junxian He
@junxian_he
Followers
6K
Following
2K
Media
34
Statuses
249
Assist. Prof @hkust. NLP/ML PhD @LTIatCMU.
Hong Kong
Joined September 2017
🚀We are excited to introduce the Tool Decathlon (Toolathlon), a benchmark for language agents on diverse, complex, and realistic tool use. ⭐️32 applications and 600+ tools based on real-world software environments ⭐️Execution-based, reliable evaluation ⭐️Realistic, covering
6
27
163

New Anthropic research: Natural emergent misalignment from reward hacking in production RL. “Reward hacking” is where models learn to cheat on tasks they’re given during training. Our new study finds that the consequences of reward hacking, if unmitigated, can be very serious.
146
412
3K

While discussing spatial intelligence of "VLMs", wanted to share an interesting finding we have in ICML25 paper: We actually opens the black box of why VLMs fail at even the simplest spatial question "where is A to B" - 90% of tokens are visual, yet they get only ~10% of the

🚀🔥 Thrilled to announce our ICML25 paper: "Why Is Spatial Reasoning Hard for VLMs? An Attention Mechanism Perspective on Focus Areas"! We dive into the core reasons behind spatial reasoning difficulties for Vision-Language Models from an attention mechanism view. 🌍🔍 Paper:
9
87
574

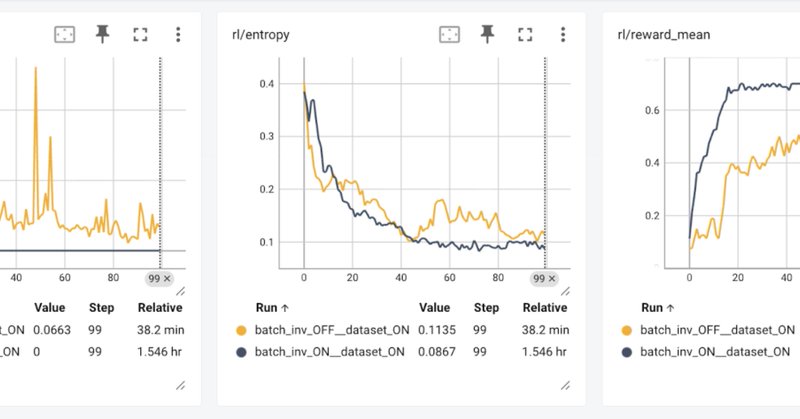
🚀 No More Train–Inference Mismatch! We demonstrate bitwise consistent on-policy RL with TorchTitan (training) + vLLM (inference) — the first open-source run where training and inference numerics match exactly. It only takes 3 steps: 1️⃣ Make vLLM batch-invariant (same seq →
blog.vllm.ai
We demonstrate an open-source bitwise consistent on-policy RL run with TorchTitan as the training engine and vLLM as the inference engine. Built on top of vLLM’s recent work on batch-invariant...
9
63
520

RL is bounded by finite data😣? Introducing RLVE: RL with Adaptive Verifiable Environments We scale RL with data procedurally generated from 400 envs dynamically adapting to the trained model 💡find supervision signals right at the LM capability frontier + scale them 🔗in🧵
12
113
466

Toolathlon:测试智能体处理多样、真实长任务的表现 聚焦于真实世界中的复杂、多步骤工作流程,这些任务往往繁琐、注重细节,并需与多种工具和系统集成。这个基准目标填补现有评估方法的空白,帮助研究者量化不同模型在实际应用中的表现差异、输出准确性和处理模糊任务的能力。 核心概念与工作机制
🚀We are excited to introduce the Tool Decathlon (Toolathlon), a benchmark for language agents on diverse, complex, and realistic tool use. ⭐️32 applications and 600+ tools based on real-world software environments ⭐️Execution-based, reliable evaluation ⭐️Realistic, covering
0
2
7
Very cool

🚀Excited to share our new work! 💊Problem: The BF16 precision causes a large training-inference mismatch, leading to unstable RL training. 💡Solution: Just switch to FP16. 🎯That's it. 📰Paper: https://t.co/AjCjtWquEq ⭐️Code: https://t.co/hJWSlch4VN
0
0
9
While SOTA LLMs start to saturate on traditional tool-use benchs such as tau-bench and BFCL, we bring tool use evaluation to real-world software environments and tasks
🚀We are excited to introduce the Tool Decathlon (Toolathlon), a benchmark for language agents on diverse, complex, and realistic tool use. ⭐️32 applications and 600+ tools based on real-world software environments ⭐️Execution-based, reliable evaluation ⭐️Realistic, covering
0
2
15

tool-use complexity isn’t just the number of apps, it’s the richness of the data they hold (e.g., an empty inbox ≠ a real email account with thousands of threads). realistic data makes for challenging and useful tasks. toolathlon tackles this 👇 38.6% pass@1 to 90% when?
🚀We are excited to introduce the Tool Decathlon (Toolathlon), a benchmark for language agents on diverse, complex, and realistic tool use. ⭐️32 applications and 600+ tools based on real-world software environments ⭐️Execution-based, reliable evaluation ⭐️Realistic, covering
1
3
45
This project is co-led by @lockonlvange Wenshuo Zhao, Jian Zhao, @AndrewZeng17 @HaozeWu7 , and a wonderful collaboration from all the collaborators from HKUST, @OpenHandsDev , CMU, and Duke: Xiaochen Wang, Rui Ge, @SArt_Maxine @yuzhenh17 @WeiLiu99 @junteng88716710 @SuZhaochen0110
0
0
8
Finally, check out our eval toolkit! https://t.co/buVE0z2qn4 We support parallel, containerized evaluation and running full evaluation of Claude 4.5 Sonnet takes 70 minutes. Our website ( https://t.co/bhpiBOc3gd) also allows to explore all the tasks and trajectories!
1
0
3
The cost-effectiveness of models is also very important. Claude is generally more expensive, whereas GPT-5 offers better cost efficiency among proprietary models. Among open-source models, DeepSeekv3.2 is the most affordable while achieving the highest performance.
1
0
1
Long context is a clear challenge for language agents. When tool returns are overlong, the success rates are generally lower than the tasks without overlong tool returns.
1
0
1
What fails the SOTA LLMs? We first analyze the tool call errors, some models just hallucinate non-existing tool names, for example Gemini2.5
1
0
1
Each task in Toolathlon is based on real-world environments with dedicated state init (such as a prefilled email inbox and real-world financial google sheets), and is verifiable to ensure reliable eval. Most tasks require interleaving multiple applications to complete. The tasks
1
0
3
Performance of different models. Claude-4.5-Sonnet leads the race with 38.6% pass@1 accuracy, GPT-5 and Claude-4-Sonnet are following with similar performance. Toolathlon reveals a clear gap between open-source and proprietary models. DeepSeek-V3.2 is the best-performing
1
0
5

We just built and released the largest dataset for supervised fine-tuning of agentic LMs, 1.27M trajectories (~36B tokens)! Up until now, large-scale SFT for agents is rare - not for lack of data, but because of fragmentation across heterogeneous formats, tools, and interfaces.

arxiv.org
Public research results on large-scale supervised finetuning of AI agents remain relatively rare, since the collection of agent training data presents unique challenges. In this work, we argue...
27
173
1K

We’re open-sourcing MiniMax M2 — Agent & Code Native, at 8% Claude Sonnet price, ~2x faster ⚡ Global FREE for a limited time via MiniMax Agent & API - Advanced Coding Capability: Engineered for end-to-end developer workflows. Strong capability on a wide-range of applications
125
858
2K
Check out Shiqi's work on how self-play and world modeling as a warmup phase can boost agentic RL training!
Want to get an LLM agent to succeed in an OOD environment? We tackle the hardest case with SPA (Self-Play Agent). No extra data, tools, or stronger models. Pure self-play. We first internalize a world model via Self-Play, then we learn how to win by RL. Like a child playing
1
6
52