
Josh Albrecht
@joshalbrecht
Followers
2K
Following
310
Media
1
Statuses
82
Helping machines learn. CTO at Imbue (formerly Generally Intelligent)
Joined April 2009
RT @imbue_ai: Writing code is just the start. To move beyond prototypes, we need agents that plan, write specs, run tests, follow style gu….
0
2
0
Guess what isn't subject to the same rate limits? The slack web client. Maybe time to start scraping the data you need and make an unofficial API library?.

1
0
2
Largely correct, though the stochastic parrot people also seem to be taking the (weird) position that billions of dollars and thousands of smart people working on something will be insufficient to make significant improvements in that thing.

The correct take:.- “stochastic parrot” is a top notch turn of phrase that does accurately convey something about what LLMs do.- stochastic parrots can be smarter than most of the people who like that phrase think.- but not as smart as the people who don’t like that phrase think.
1
0
3
Had a great time at the AI Engineer World's Fair — thank you @swyx and @LatentSpace for hosting.

How can we use AI not just to vibe-code, but to build robust software systems?. Last week, @joshalbrecht gave a talk at the @aiDotEngineer World's Fair on how to use AI tools to detect and fix problems in generated code. Listen to his full talk here:
1
0
3
RT @imbue_ai: Try to answer the question below. Confused? You’re not alone. 🍓🫐. When combing through LLM evaluation sets, we found many am….
0
7
0
This was such a fun conversation with @swyx and @jefrankle . I'm really proud of the work our team did, and it was great to get a chance to share some of the details.

🆕 State of the Art: Training >70B LLMs . We are excited to deep dive into @imbue_ai's incredible new releases with @joshalbrecht (CTO of Imbue). AND with the best return GUEST COHOST possible for the job: @jefrankle (Chief AI Scientist of @DbrxMosaicAI

0
4
15
Today we're releasing:.- Cleaned up (and extended) versions of 11 public NLP benchmarks.- An open source method for automatically discovering scaling laws.- A guide to bringing up a 4000 GPU cluster from bare metal.- . and more, see below!.
Early this year, we trained a 70B model optimized for reasoning and coding. This model roughly matches LLAMA 3 70B despite being trained on 7x less data. Today, we’re releasing a toolkit to help others do the same, including:. • 11 sanitized and extended NLP reasoning

1
2
15
RT @hedra_labs: Introducing the research preview of our foundation model, Character-1. Available today at (on deskt….
0
173
0
Finally, someone making it easy to interact programmatically with browsers!. I've really been enjoying using Browserbase recently. Kudos to Paul for making such a nice product.

Happy to share Browserbase with the world today. We help AI applications browse the web. And we just raised $6.5 million to do it. Now, we're opening signups to developers everywhere. I can't wait to see what you 🅱️uild.
1
0
9
If you're sad about not getting into NVDA years ago, go work with this team--they're great, and we're very excited to use their chips as soon as they're ready.

Introducing MatX: we design hardware tailored for LLMs, to deliver an order of magnitude more computing power so AI labs can make their models an order of magnitude smarter. Our hardware would make it possible to train GPT-4 and run ChatGPT, but on the budget of a small startup.

0
2
12
RT @imbue_ai: “We want to make it much easier for relatively technical people to make software. And then much easier for non-technical peop….
0
7
0
RT @imbue_ai: 🎙️ New Generally Intelligent podcast episode!. We interviewed @tri_dao (author of FlashAttention & Chief Scientist @togetherc….
0
13
0
RT @imbue_ai: We’re honored to join the new AI Safety Institute Consortium led by @NIST and @CommerceGov. AI agents that take actions in t….
0
7
0
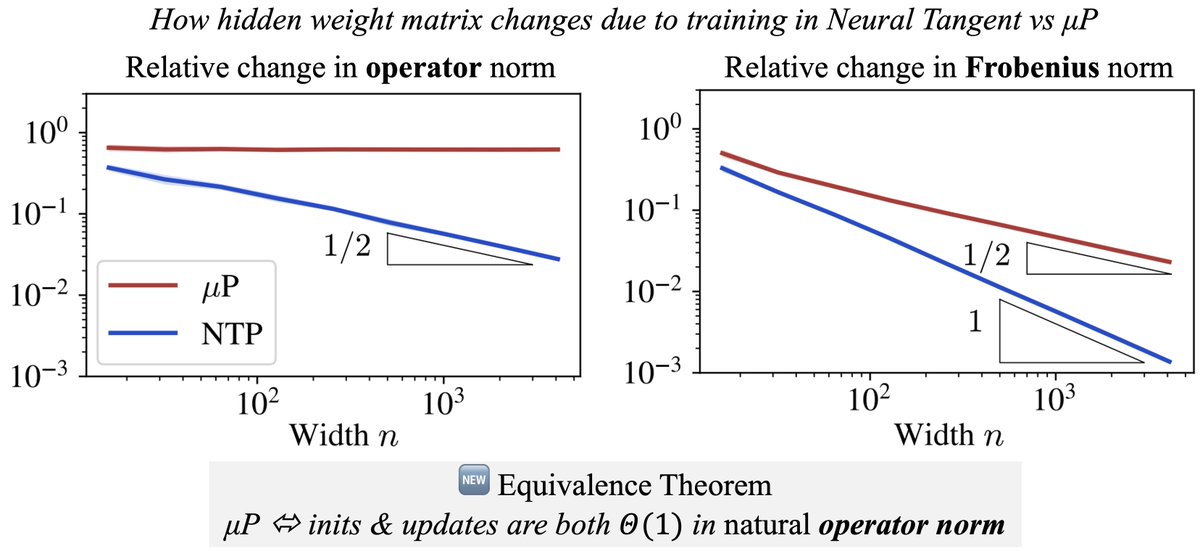
This is exactly the kind of work I mean when I say "practical theory". Neural networks are not magical black boxes, and actually understanding what they're doing lets us waste a lot less time fiddling around. Very happy to be able to share this work by our very own Jamie Simon.

1/ μP is optimal scaling rule of learning rate & init as network width → ∞. Been confused?. 🆕μP = holding the "natural" (I'll explain) operator.norm constant for every weight W & its updates ΔW:. μP <=> ‖W‖_nat = Θ(1) = ‖ΔW‖_nat. 🆕Frobenius norm is the wrong norm to measure!
0
5
34
RT @RohdeAli: The great speakers continue tomorrow, as @joshalbrecht and I talk all about alignment with our friend @RichardMCNgo. Richard….

lu.ma
Doors will open 6:30PM. Fireside begins at 7:00PM. Food and drinks will be provided. Join us for a fireside chat with Dr. Richard Ngo. Richard works on the…
0
2
0
Would certainly be nice to see compute become more of a commodity!.

We're happy to announce the world's first compute auction site is now in beta. Bid on time on our 23,000 Nvidia H100s. Per-hour access for any AI project!
0
0
3
RT @arram: My friend @joshalbrecht just announced his company raising $200M. I’ve long considered Josh the most talented person nobody know….
0
7
0
RT @kanjun: I'm excited to share our $200M Series B at a $1B+ valuation to develop AI systems that reason!. We believe reasoning is the mai….
0
208
0