

joana da matta
@joanadmff
Followers
37
Following
146
Media
7
Statuses
42
computer science student and undergradute researcher @dipucrio / @umontreal aspiring computational linguist
Rio de Janeiro
Joined September 2024
if anyone needs a resident carioca to show them around the city i volunteer!!!.

ICLR 2026 will take place in. 📍Rio de Janeiro, Brazil.📅 April 23–27, 2026. Save the date - see you in Rio! #ICLR2026

0
0
5
i'm grappling with the fact that the area i want to do research on (tokenization) has the goal of ceasing to exist. like i'm putting hours into something to make it go away, and it will be great if it does, but then what?.
0
0
2


good news! @Cohere_Labs ML summer school was a blast!.bad news! it's over :(.i'd like to thank Cohere's Open Science community for always giving us opportunities to grow. this is only the beginning 🚀

1
2
29
@Cohere_Labs also, i'll be writing all of my notes on this notebook, if you'd like to check it out c:.
jodamatta.notion.site
02/07 - ML Math Refresher - Katrina Lawrence
0
0
2
first day of the ML Summer School organized by @Cohere_Labs, everytime I join an event organized by them I'm reminded just how much I value this community 🤞.
2
0
9
RT @MorePerfectUS: Elon Musk's xAI has been poisoning Memphis' air with no permit and no oversight. Now the people of Memphis are fighting….
0
5K
0
washing my hands with detergent after a rough climbing session must be the closest i've been to god.
0
0
1

"first genuinely serious AI safety issue" is one hell of a statement in 2025, but other than that i completely agree.

This is the first genuinely serious AI safety issue I've seen and it should be addressed immediately, model rollback until they have it fixed should be on the table.
0
0
1
RT @sarahookr: Lol why does every open ai media — whether videos of model launches or photos of devs excited about the technology have almo….
0
12
0
RT @CohereForAI: Nossa integração com o WhatsApp agora inclui os recursos de interpretação de imagens do Aya Vision! Experimente agora incl….

cohere.com
Available in 23 languages, Aya Expanse is the best multilingual AI in the world. Now available on WhatsApp, text Aya in your language, for free.
0
1
0
RT @MatthewBerman: Is Chain-of-Thought (CoT) reasoning in LLMs just. for show?. @AnthropicAI’s new research paper shows that not only do A….
0
246
0
RT @jacksonkekhw: What can we learn from LLaMA 4's 10M token context length? .1. Full attention is O(n²) — at 10M tokens, memory & compu….
0
44
0
seeing everyone discussing very long context and NoPE + RoPE today is so fun, I just spent the last two weeks reading infinite stacks of papers on this topic for my thesis.
0
0
3
RT @cloneofsimo: it looks like meta's new model's "Key innovaton" : "interleaved no-RoPE attention" for infintie context, is actually the….
0
55
0
10M tokens seems like such a huge jump from where we were yesterday, excited for my long-context friends but still skeptical. i hope it can at least perform with >256k.

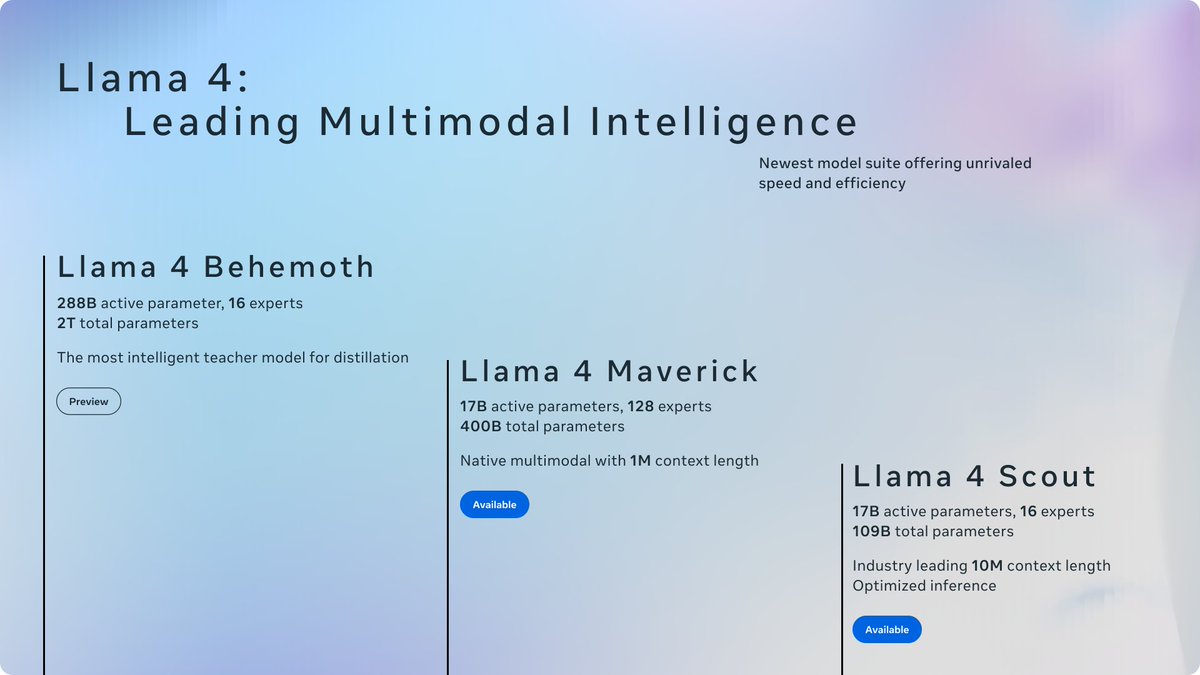
Today is the start of a new era of natively multimodal AI innovation. Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality. Llama 4 Scout.• 17B-active-parameter model
0
0
1
aaron swartz lives forever.

Libgen shutting down is genuinely a disaster for poorer researchers.
0
0
1
this video is mandatory viewing for anyone who cares about women in tech, specially the last 10 minutes.
0
0
1
It is such a pleasure to work with this community!.

0
0
6