

Isabelle Mohr
@isabelle_mohr
Followers
235
Following
124
Media
10
Statuses
63
MLE @JinaAI_ 🤖 Interested in all things Machine Learning!
Joined April 2022
RT @JinaAI_: 2025 could be the year of Deep(Re)Search. Test-time compute and reasoning model are transforming search systems now. With <thi….
0
57
0
RT @bo_wangbo: Great work from MMTEB team! We have 3 contributors from @JinaAI_ ! @michael_g_u @jupyterjazz @isabelle_mohr.
0
5
0

RT @michael_g_u: Our submission to ECIR 2025 on jina-embeddings-v3 has been accepted! 🎉.At the ECIR Industry Day @jupyterjazz takes the sta….
0
4
0
RT @avthars: Stop paying the OpenAI tax. The best AI devtools are actually open-source, free to use, and give you full control over your da….
0
408
0
RT @michael_g_u: We extended our priprint about late chunking, a novel method to make embeddings of chunks context-aware. We added:.- Algor….
0
10
0
Want to learn more about Embeddings, Rerankers and ColBERT? Come to my talk on Thursday at @qdrant_engine's Vector Space Event 😎 more info here ->

luma.com
Vector Space Event The Qdrant team, in cooperation with Jina AI, invites you to our next Vector Space event, where we will discuss the exciting new features…
0
4
10

0
1
0
RT @bo_wangbo: Got my Weaviate👕 here ;) thanks @femke_plantinga and @philipvollet !. This afternoon my colleague @isabelle_mohr and @saahil….
0
5
0
RT @jupyterjazz: Clip your schedules for next week because Andreas and I will present our latest text&image embedding model with advanced t….

jina.ai
Top-performing multimodal multilingual long-context embeddings for search, RAG, agents applications.
0
5
0
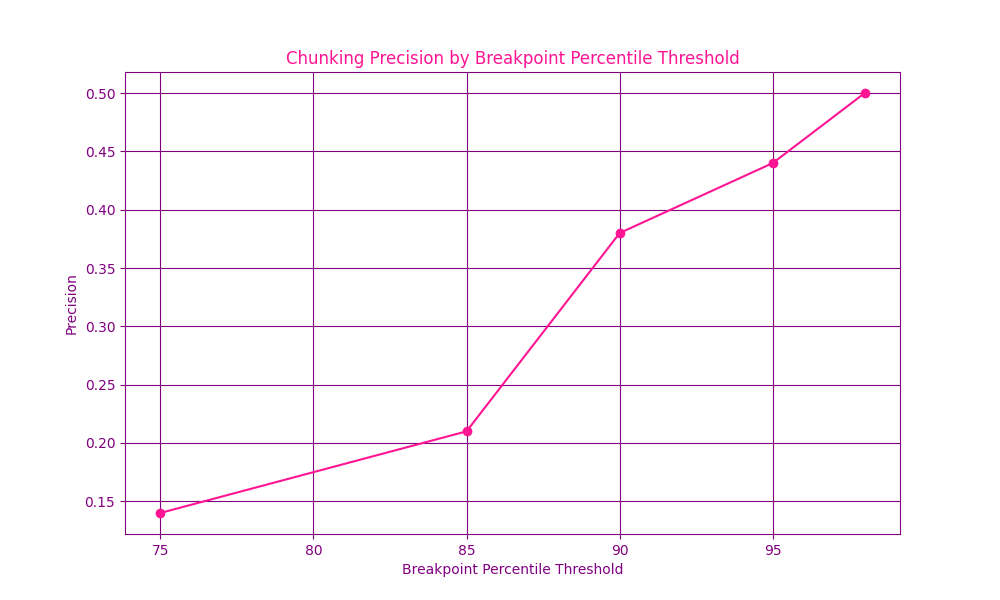
This week I explored chunking methods: the Semantic Chunker from @llama_index on jinaai/wikisections dataset on Hugging Face. Varying the buffer size had pretty much no effect, while increasing the breakpoint percentile threshold increased chunking precision by a lot! @JinaAI_
1
1
11
Last night I had the pleasure of giving a talk together with @jupyterjazz at the Data Meetup Berlin hosted by Netlight! Love the knowledge sharing, and most importantly, to connect with so many passionate and interested people in the field. See you at the next one!. #embeddings


0
0
3
I'll be giving a talk together with @jupyterjazz next week in Berlin about our German-English bilingual embedding model. If you wanna know how we trained this model and how to use it in a RAG pipeline, you better RSVP and attend! See ya there 🚀.@JinaAI_.

meetup.com
## Data Meetup Berlin returns in its first 2024 edition! Join us on Thursday, April 11th, at Netlight's Berlin office to hear from our amazing data experts. In this editio
1
4
6
RT @bo_wangbo: A ColBERT variant, but support a bit longer context :). cc @jobergum @lateinteraction @bclavie.

huggingface.co
0
19
0
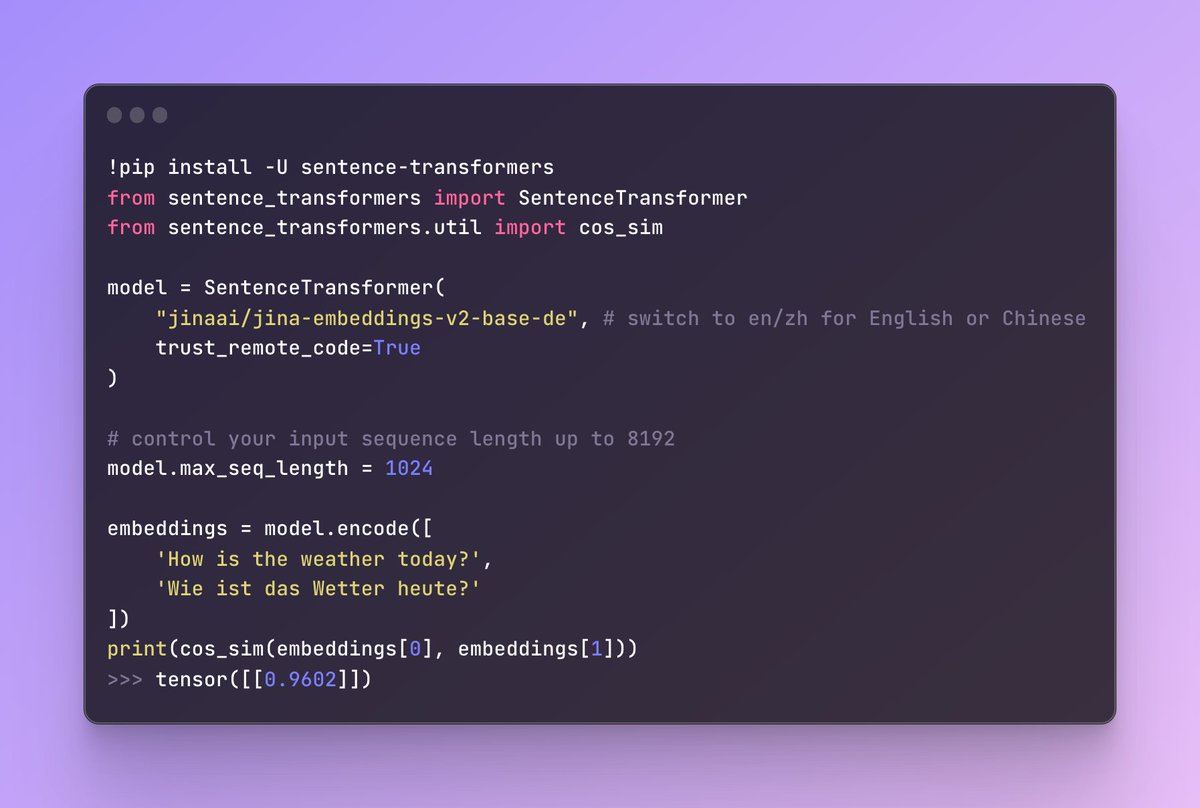
RT @xenovacom: A few days ago, @JinaAI_ released two new bilingual embedding models (German-English & Chinese-English), each supporting a m….
0
8
0
RT @bo_wangbo: We’re finally here with 2 new models, we call it bilingual embedding models, it allows you to perform monolingual and cross-….
0
11
0
RT @michael_g_u: Our German-English and Chinese English embedding models are open-source now 🚀..
0
6
0