Explore tweets tagged as #FrontierMath
Introducing FrontierMath Tier 4: a benchmark of extremely challenging research-level math problems, designed to test the limits of AI’s reasoning capabilities.

19
64
558

A fourth problem on FrontierMath Tier 4 has been solved by AI! Written by Dan Romik, it had won our prize for the best submission in the number theory category.

21
115
730

Epoch AI evaluated GPT-5 on the FrontierMath benchmark. It sets a record-setting performance. Of the Tier 4 problems that GPT-5 solved, two had not been solved before by any AI system. GPT-5 was the first model to solve a problem written by one of the FrontierMath Symposium’s 1

1
0
0
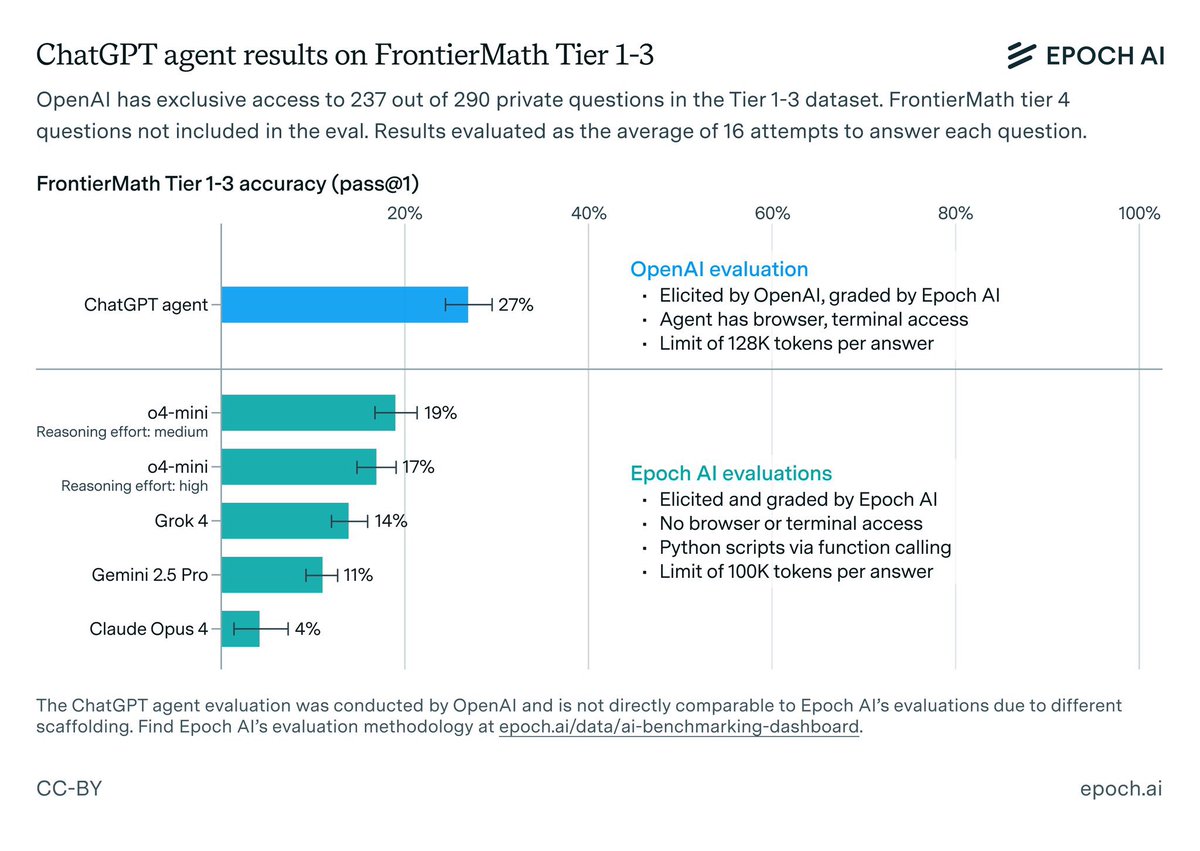
We have graded the results of @OpenAI's evaluation on FrontierMath Tier 1–3 questions, and found a 27% (± 3%) performance. ChatGPT agent is a new model fine-tuned for agentic tasks, equipped with text/GUI browser tools and native terminal access. 🧵
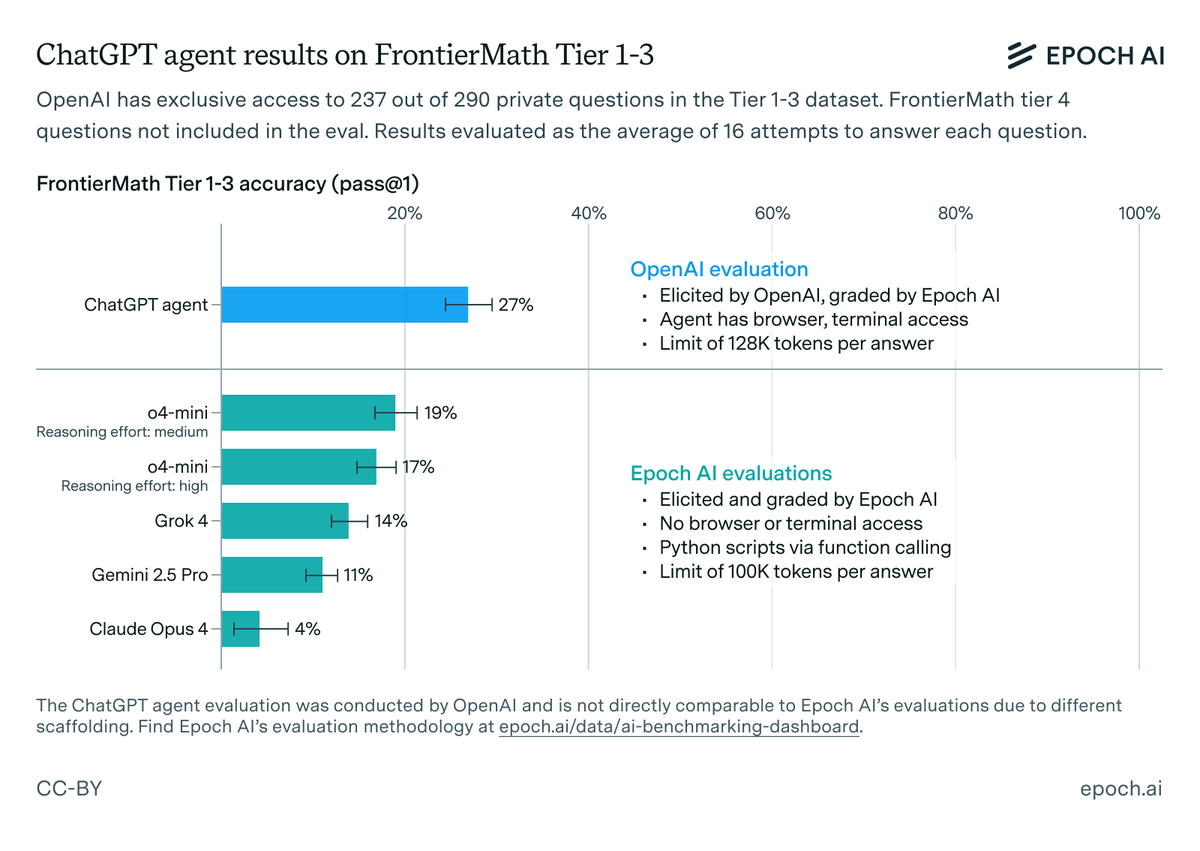
36
151
864

The anthropometric validation report of FrontierMath's hardest ever math benchmark has now been officially published on the FrontierMath website. Grateful that we have objectively and impartially confirmed the everlasting superiority of our work. 😇

1
0
17

Re: “At Secret Math Meeting, Researchers Struggle to Outsmart AI” — What Actually Happened. Just saw a news report about the FrontierMath Symposium (hosted by @epochai). While AI is advancing at an incredible pace, I think some parts of the report were a bit exaggerated and could




11
18
93

Reasoning LLMs like o3 and R1 have reportedly solved some advanced math problems, including those from the FrontierMath benchmark. However, we find that they still struggle with pre-college theorem proving. When tasked with proving inequalities from math competitions, both o3 and


🚀 Excited to share our #ICLR2025 paper: "Proving Olympiad Inequalities by Synergizing LLMs and Symbolic Reasoning"!.📄 Paper: LLMs like R1 & o3 excel at solving complex, calculation-based math problems. However, when it comes to proving inequalities in

5
22
165
GPT-5 performs strongly on math benchmarks, achieving a new SOTA on FrontierMath and OTIS Mock AIME 2024-2025.

1
4
73
GPT-5 was the first model to solve a problem written by one of the FrontierMath Symposium’s judges!. Algebraic geometer Ravi Vakil had this to say about the solution to his problem:

1
6
72
The higher the FrontierMath difficulty tier, the lower GPT-5 scored. This suggests a correlation between what mathematicians find difficult and what makes problems harder for AI systems to solve.

1
4
63

GPT-5 sets new SOTA on FrontierMath (22-28% Tiers 1-3, 4-12% Tier 4) and OTIS Mock AIME (83-91%), improves on SWE-bench Verified (57-61%) over o4-mini but trails Claude 4.1, and matches top models on GPQA (83-87%), with positive Cursor user anecdotes.

We’ve independently evaluated the GPT-5 model family on our benchmarking suite. Here is what we’ve learned 🧵

0
0
22
GPT-5 sets a new record on FrontierMath! On our scaffold, GPT-5 with high reasoning effort scores 24.8% (±2.5%) and 8.3% (±4.0%) in tiers 1-3 and 4, respectively.
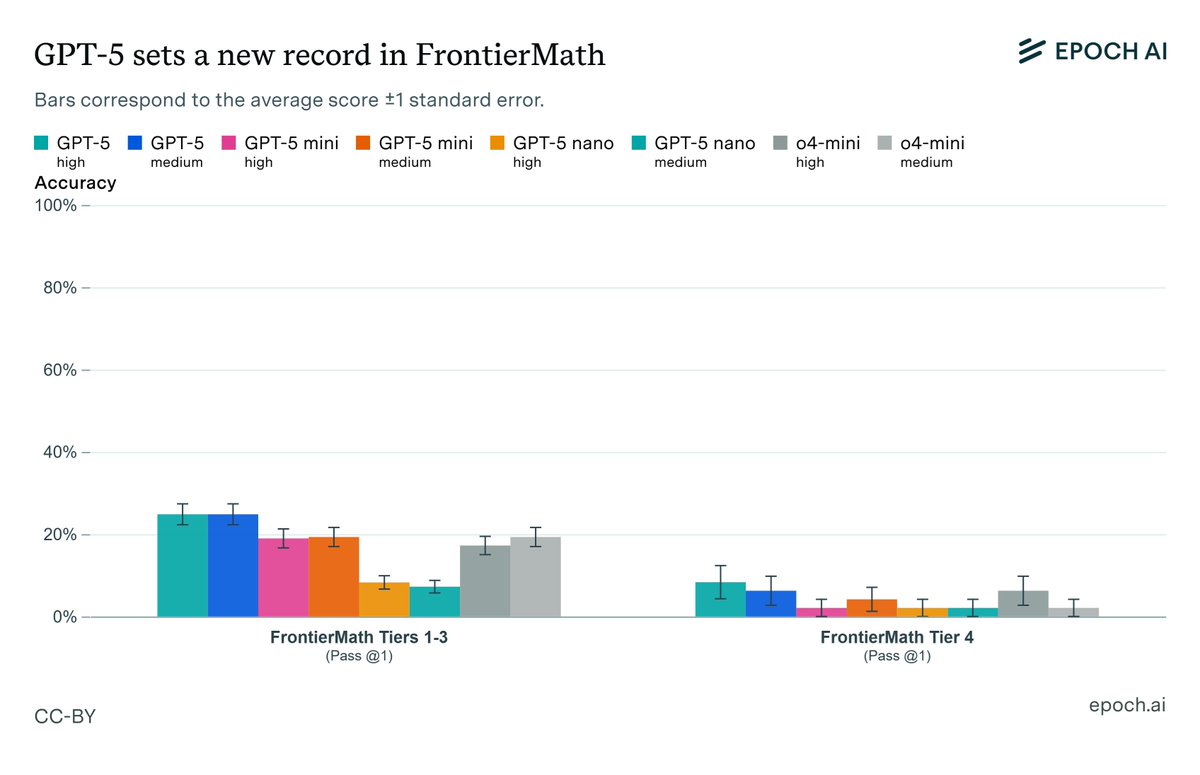
14
37
308

ChatGPT Agent Mode is now the king of math. It just crushed FrontierMath Tier 1–3, problems so hard only elite PhD-level mathematicians solve them. Most humans need a team. The agent did it solo. Autonomous tools, reasoning at scale. This is straight-up insane.
3
5
57

GPT-5 nano crushes the FrontierMath benchmark better than GPT-5 😂.Who makes these numbers up?

6
4
62

GPT-5 Nano is the cheapest reasoning model offered by any lab – $0.05/$0.40. It’s incredibly intelligence dense, with over 54% SWE-Bench and nearly 10% FrontierMath on "high" reasoning. No model of any size had reached either mark as recently as January – it beats o1, DeepSeek

6
6
85



I'm starting to suspect that OpenAI is screwing with us.Coding deception plot: bar heights are deceptive.FrontierMath eval: numbers are wrong.Hallucination benchmarks: hallucinated model label.If those are easter eggs, it's comedy gold



1
0
27

A lot of interesting discussion recently on the implications of OpenAI being a major sponsor of the FrontierMath benchmark. There are two extremes of what this implies:.1) omg OAI is benchmark hacking and leaking test data into training! .2) OAI uses questions in the private

6
6
49
We’ve adopted special scoring rules to evaluate the Gemini 2.5 models, addressing the API issues we faced in previous attempts. Under this protocol, Gemini 2.5 Pro solves 11% (±2%) of FrontierMath, making it the best non-OpenAI model we’ve evaluated so far.

4
4
106

🚨Truth: 2.5 pro is better than full o3 in AIME 2024 and GPQA Diamond. @pass 1. AIME GPQA.2.5 pro | 92% | 84%.o3 | 90-91% |82-83%.(I tried to measure it using a software as accurately as possible).I want to see it on ARC-AGI2 & FrontierMath


10
10
147