Explore tweets tagged as #DataLoader




ML GRIND DAY 7.> finished the "Build a LLM from Scratch" book 💪.> LLM classification and instruction fine-tuning.> diving deep into some PyTorch basics. - PyTorch Dataset and DataLoader. - log-sum-exp-trick for CrossEntropyLoss. one book down! .Let's gooo.




10
21
391

New NanoGPT training speed record: 3.28 FineWeb val loss in 3.95 minutes. Previous record: 4.41 minutes.Changelog:.- @leloykun arch optimization: ~17s.- remove "dead" code: ~1.5s.- re-implement dataloader: ~2.5s.- re-implement Muon: ~1s.- manual block_mask creation: ~5s

13
24
302

VAE dataloader building. not bad for only train/eval on 10 images
1
0
0

If you are confused what `num_workers` to be used with your PyTorch dataloader, it is good idea to just profile it. I just did for my own dataloader and found 24 workers to be most performant while earlier I was using 29 workers.

0
0
3

🚀 cuik-molmaker swaps Chemprop’s Python/RDKit dataloader for lean C++—the step that used to hog ~50% of every training batch is now a blip. Ongoing work will generalize to other GNNs. Try it out today as a pip installable or at
0
5
22

Wait!!! So this DataLoader thing existed to reduce gpu utilisation!!! And make my model train

6
3
54

改変されたDataLoaderによりSalesforce上のデータが抜き取られる事件. DataLoaderが動かなくなったときに、動作するVerのDLリンクをコミュニティ等で知らない人に聞いたりするのちょっと危ないかも。Salesforceアカウント持ってる人全員がリテラシー高いわけじゃないし、、.
0
2
25


とてもよかった。Dataloader、キューに関数呼び出しとその引数をつめたうえでdebounceして適当なボリューム感で投げて、返ってきたもので満たせるpromiseをresolveするということか。面白い。手間かからなさそうだから、RSCやるならゼロイチの開発でも入れたら良さそう.
1
5
33

Scalable and Performant Data Loading. "We present SPDL (Scalable and Performant Data Loading), an open-source, framework-agnostic library designed for efficiently loading array data to GPU.". "Our benchmark shows that compared to the PyTorch DataLoader, SPDL can iterate through

2
24
146

One of my favorite patterns that doesn't get enough love is dataloader. It allows you to fetch data like normal, but it automatically batches & caches the calls. This allows you to fetch data from completely different locations in your app with the speed of one call

5
3
28

Visualizing how labels (bottom) correspond to the "response"s in the input_ids (top) for a QA dataset finetuning dataloader

0
0
1

15-16) Set max_workers and pin_memory in DataLoader. PyTorch dataloader has two terrible default settings. Update them according to your config. Speedup is shown in the image below 👇

1
0
24

TIL: If you write a custom collate_fn, don’t forget to set pin_memory=True in your PyTorch DataLoader. It can halve your training time and actually make the GPU go brr (violet = before, yellow = after)

0
0
6

This is some seriously high-quality analysis on which open dataloader to use for your multimodal workflows. It's definitely going to save you months of time!.

Ever wondered how large-scale multimodal training worked?.How ~petabytes of data are loaded from the cloud to accelerators?. Here I benchmark 4 frameworks (WebDataset, Energon, MDS, LitData) on data prep efficiency, cloud streaming perf, & fault tolerance. TL;DR: Try out LitData

0
1
18

AI/ML rants:. Python isn’t a great language for machine learning. It doesn’t support real parallel threading, so data loaders end up slow and awkward. There’s also this PyTorch DataLoader problem if you don’t set things up exactly right, it looks like there’s a memory leak. I

2
0
4


Stop by poster #596 at 10A-1230P tomorrow (Fri 25 April) at #ICLR2025 to hear more about Sigmoid Attention! . We just pushed 8 trajectory checkpoints each for two 7B LLMs for Sigmoid Attention and a 1:1 Softmax Attention (trained with a deterministic dataloader for 1T tokens):. -
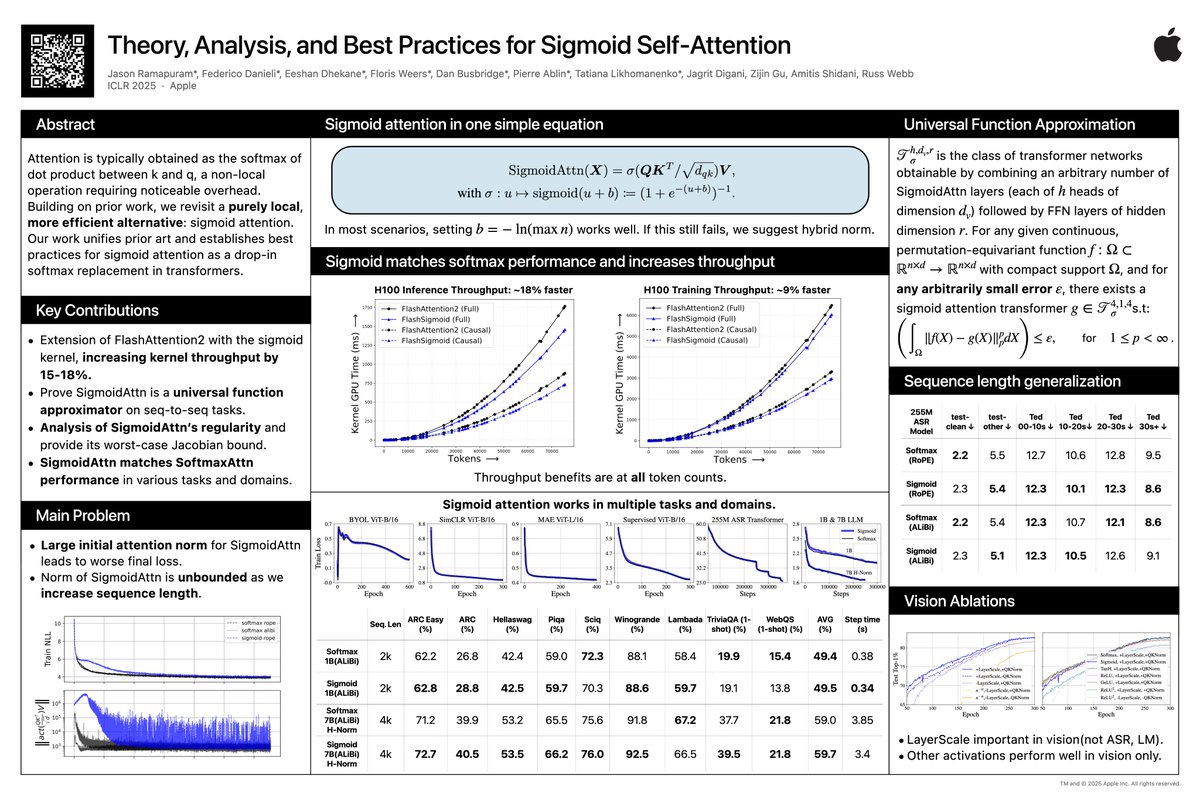
Small update on SigmoidAttn (arXiV incoming). - 1B and 7B LLM results added and stabilized. - Hybrid Norm [on embed dim, not seq dim], `x + norm(sigmoid(QK^T / sqrt(d_{qk}))V)`, stablizes longer sequence (n=4096) and larger models (7B). H-norm used with Grok-1 for example.

1
14
45