Explore tweets tagged as #AmoebaNet

DARTS: Differentiable Architecture Search. NASNetのような強化学習でも、AmoebaNetのような進化型計算でもない、微分可能なニューラルネット構造探索手法が登場。.予め探索対象となる構造を内包しており、重みの最適化と構造の最適化を交互に行いながら最適な構造を探索。


0
44
136

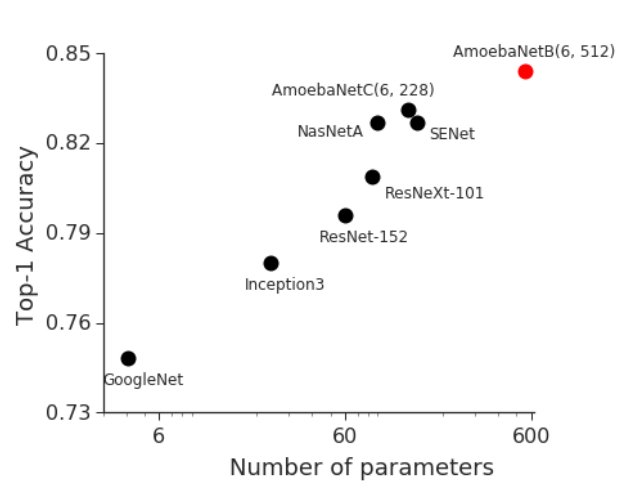
Bigger models are better models so we built GPipe to enable training of large models. Results: 84.3% on ImageNet with AmoebaNet (big jump from other state-of-art models) and 99% on CIFAR-10 with transfer learning. Link:
6
123
365

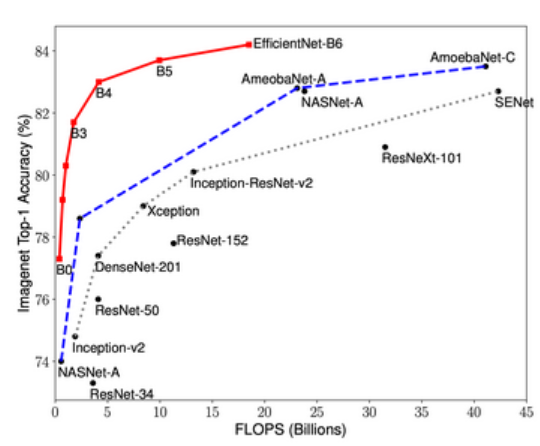
学生と今更EfficientNet輪講していてNASより計算効率の良いモデルになる理由がよくわかりませんでした。。.AmoebaNetは解像度は224でfixしているため、解像度も大きくすることでEffNetは演算効率も改善できてるのかな
0
1
2

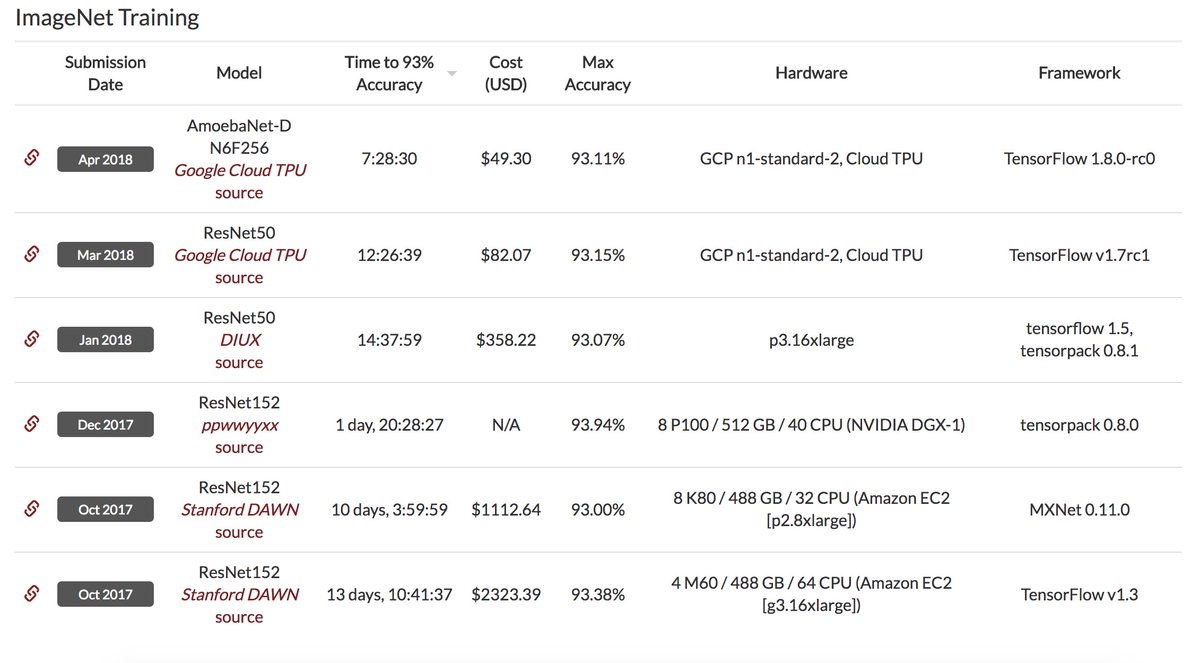
We just posted new DAWNBench results for ImageNet classification training time and cost using Google Cloud TPUs+AmoebaNet (architecture learned via evolutionary search). You can train a model to 93% top-5 accuracy in <7.5 hours for <$50. Results:
6
203
555

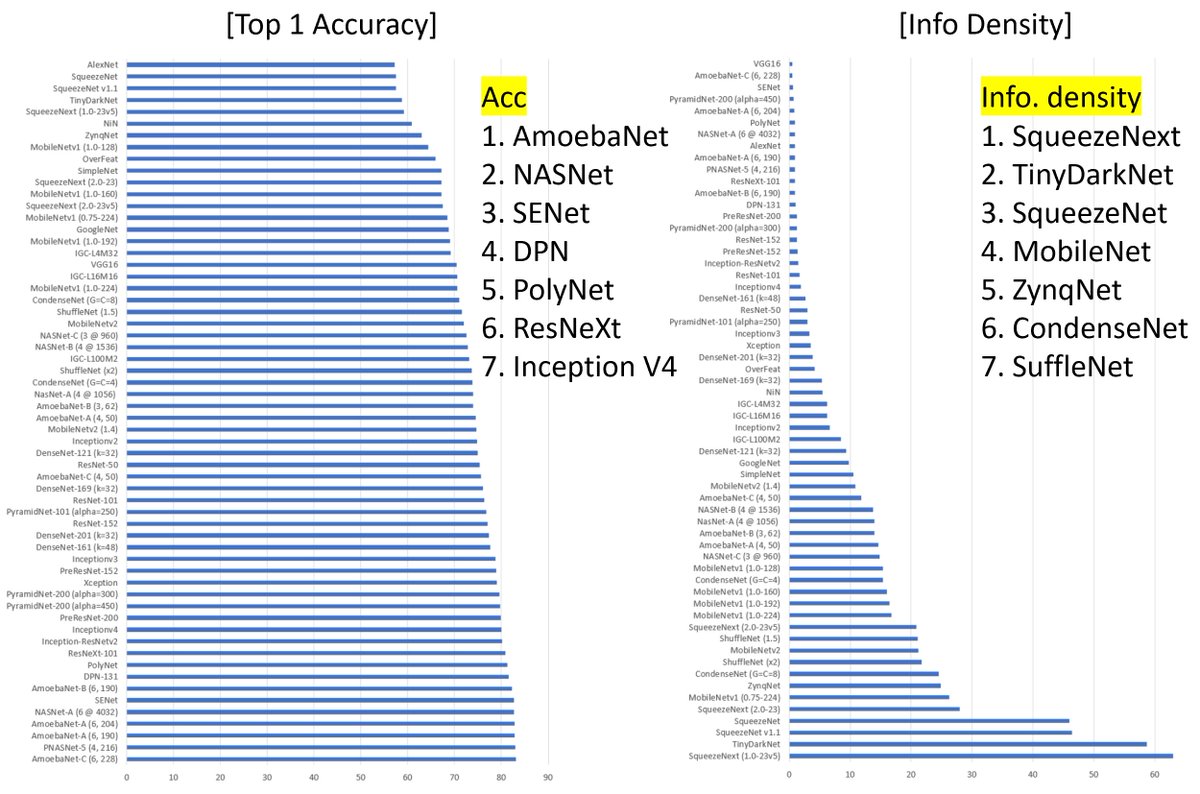
CNN Benchmark (from "NetScore" by Alex Wong, Oct 2018).- Best Acc: AmoebaNet-NASNet-SENet, .- Best Info Density: SqueezeNext-TinyDarkNet-SqueezeNet.
0
5
13

Even bigger DNNs by Google Brain - GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism - "supports models up to 2-billion parameters" and "a new 557 million.AmoebaNet SOTA with 84.3% top-1 / 97.0% top-5 accuracy on ImageNet" -

1
6
3

Efficient neural architecture search methods used to find better architecture design choices for object detection. Impressive results over YOLOv3, RetinaNet, MaskRCNN, AmoebaNet.
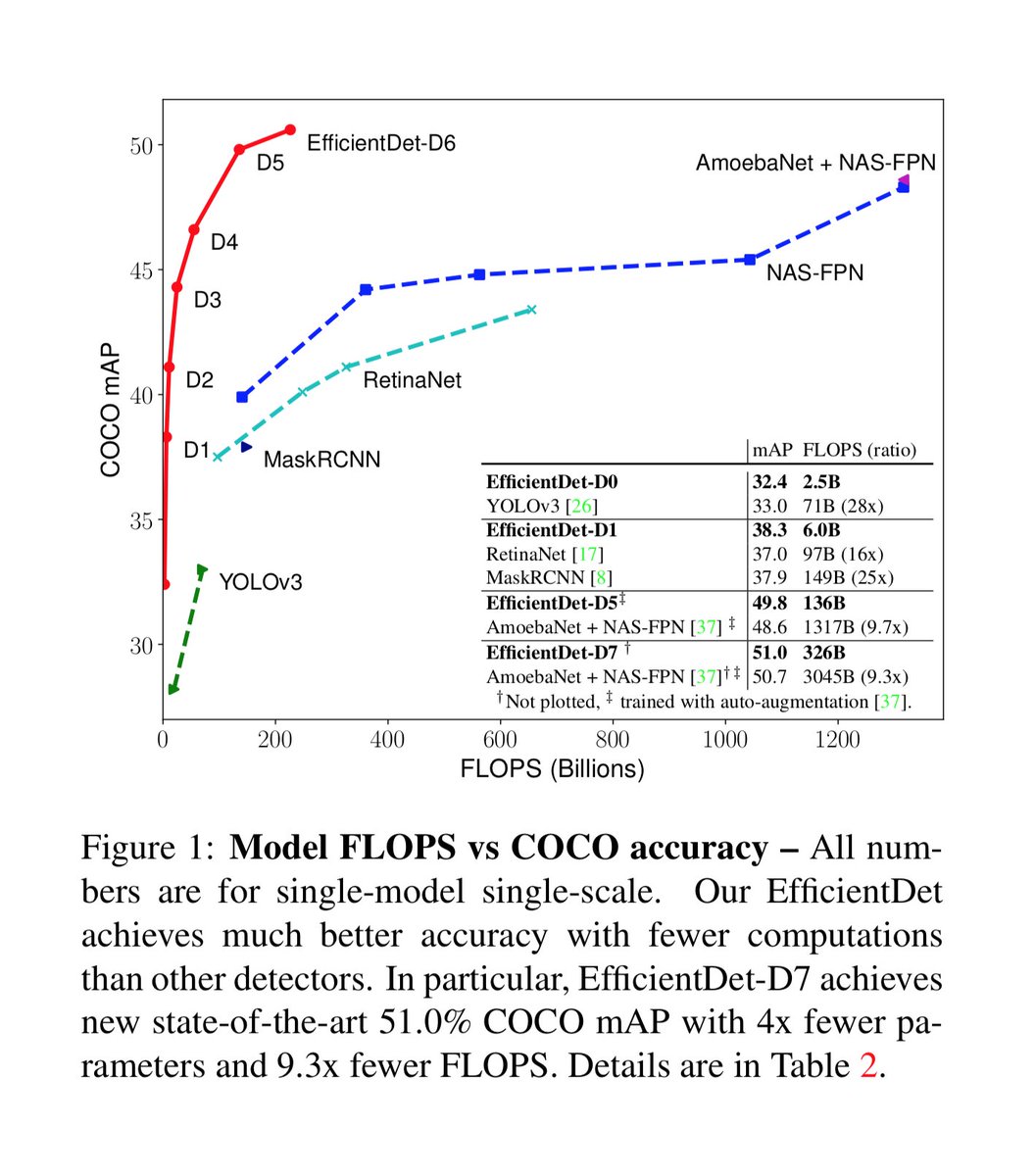

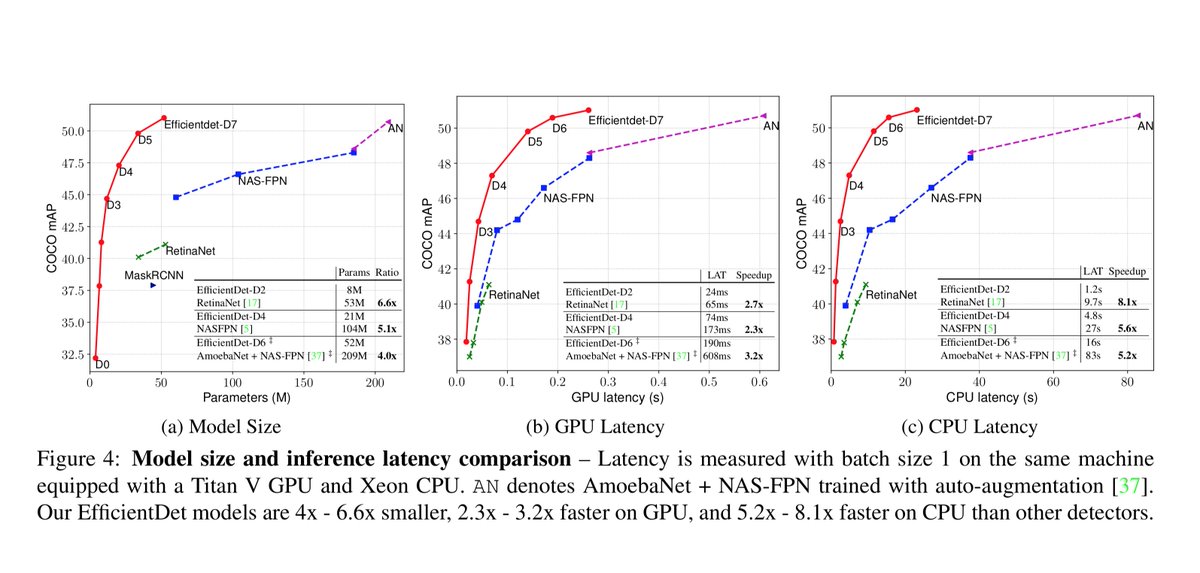

EfficientDet: Scalable and Efficient Object Detection
3
34
160
従来の4倍くらいのparamなGPipeのAmoebaNet-B(6, 512)で+1%~+2%程度なあたり、パラメータ数増やす方向性は有効なんだけど計算機的に辛そう.

0
0
2

A fun series of “AutoML” papers to go through with corresponding code:. AmoebaNet MnasNet NAS-FPN .Auto-DeepLab
0
10
30
BERT、BigGAN、GPipe.前期も含めればAutoAugment、AmoebaNetあたりの大規模手法で岐路に立った人は多いんじゃないかと思う2018年。.
1
7
34
構造探索系手法.CIFAR-10 Top1 Error比較. NASNet(-A): 3.41% (3.3M).500GPU 3-4日. PNASNet: 3.63% (3.2M).100GPU 1.5日. ENASNet: 3.54% (4.6M).1GPU 0.45日. AmoebaNet(-A): 3.34% (3.2M).450GPU 2-5日. (new!)AlphaX ? (?).17GPU 5日.
1
8
26
ResNet以降。ResNetが優秀すぎてResNetを強くする方向(preact、ResNeXt、SENet等)か、良い構造自体を自動探索する(NASNet、AmoebaNet、DARTS等)に振り切っちゃってて難しい。.ResNet以外の構造の提案(DenseNet、FishNet等)もあるんだけど、そっちは余り重視されてないみたいだし。.
0
7
42
人「1万時間取り組めばプロになれる」.NASNet「4.8万GPU hoursなのでプロ」.AmoebaNet「8.6万GPU hoursなのでプロ」.
0
2
9

AmoebaNet by the way is really interesting. Its architecture itself has been computer-generated. This post compares various approaches to architecture search: evolutionary algorithms, reinforcement learning and handcrafting:
1
4
6
More info about AmoebaNets:. Open source AmoebaNet implementation:.
0
35
68
Regularized Evolution for Image Classifier Architecture Search、更新が入ってますね。AmoebaNet-B以外の結果が増えてる…まさか今も回してるのか。.
0
3
8
単純な数値列挙比較なので、あまり正当性がない。なお、AmoebaNetとAlphaXの下2つは他と方式がちょっと違う(はず)。. NASNet. PNASNet. ENASNet. AmoebaNet. AlphaX.
0
2
6

AmoebaNetってグーグル検索すると、英語と中国語の記事しか見つからないな。NASNetとかPNASNetとかAmoebaNetとか、この辺の発展(に限らず、機械学習全般)に対して、日本が完全に出遅れてることが目に見えて分かる。もう100周ぐらいは遅れてる。.
1
3
6