

Dillon Laird
@DillonLaird
Followers
557
Following
2K
Media
47
Statuses
205
Working on vision models @LandingAI 🤖 @StanfordEng @uwcse 👨🎓 neovim enthusiast 💻 I help neural networks find local minima 🧠
San Francisco, CA
Joined April 2009
In this new blog we introduce a new version of VisionAgent -- a modular, agentic AI framework that breaks visual reasoning problems into subtasks, chooses the right vision tools, and applies visual design patterns to solve them. Check it out here:
dillonl.ai
Dillon Laird's Personal Website
0
0
2
A lot of VLMs like GPT-4o and Claude-3.5 are great with text but still struggle with vision. We tested them on a simple puzzle -- count the missing soda cans in a box of soda cans and they all struggle to answer correctly.
1
1
1
I’ve made a new personal website and provided a short summary of the ~2 hour lecture with my
dillonl.ai
Dillon Laird's Personal Website
0
0
2
In this lecture, Zeyuan shows that LLMs are capability of learning algorithms to solve problems, which is a much more generalizable form of intelligence. It’s very exciting work that I’m surprised hasn't gotten more attention.
1
0
1
This presentation, The Physics of Language Models, by Zeyuan Allen-Zhu, changed my perspective on LLMs. With a lot of recent research such as the GSM-Symbolic paper by Apple, it’s generally understood that LLMs memorize or find shortcut heuristics to solve problems.
1
0
1
Amongst these papers I've always thought that the Neural Turing Machine used it in the most novel way for solving general problems. Alex Graves gives a great overview of the next iteration of this architecture, Differentiable Neural Computer, in this talk.
0
0
2
A lot of people might not know this but the attention mechanism was developed almost simultaneously in 3 papers in late 2014:. - Neural Machine Translation by Dzmitry Bahdanau.- Memory Networks by Jason Weston.- Neural Turing Machines by Alex Graves.
1
0
3
Thanks for hosting @tereza_tizkova!.

🎙️Speakers. We got really great feedback on the lightning talks. I want to thank all the speakers who made their time on Saturday and presented cool demos. It's definitely worth to follow these founders and AI companies:. 📢 Vasek Mlejnsky (@mlejva) - Founder and CEO of @e2b_dev


0
0
4
RT @AndrewYNg: A decision on SB-1047 is due soon. Governor @GavinNewsom has said he's concerned about its "chilling effect, particularly in….
0
481
0
🧵- 55:13 I cover new research adding an orchestrator agent that can chat with the user and managers other agents as well as future direction for the agentic framework.
0
0
0
🧵- 31:22 Shankar Jagadeesan showcases how to use/prompt VisionAgent including a cool use case tracking badminton players total distance traveled during a game as well as current areas of improvement.
1
0
0
🧵- 29:25 Dan Maloney talks about the customer need for VisionAgent, why are we working on it and who does it serve?.
1
0
0
🧵- 00:00 Andrew Ng introduces VisionAgent with a video demo, covers main architectural components of the agentic framework and ends with a live demo using the UI on his iPhone.
1
0
0
🧵Here's our VisionAgent talk from last Wednesday. We cover everything from architectural overview to how best to utilize VisionAgent to future research directions!
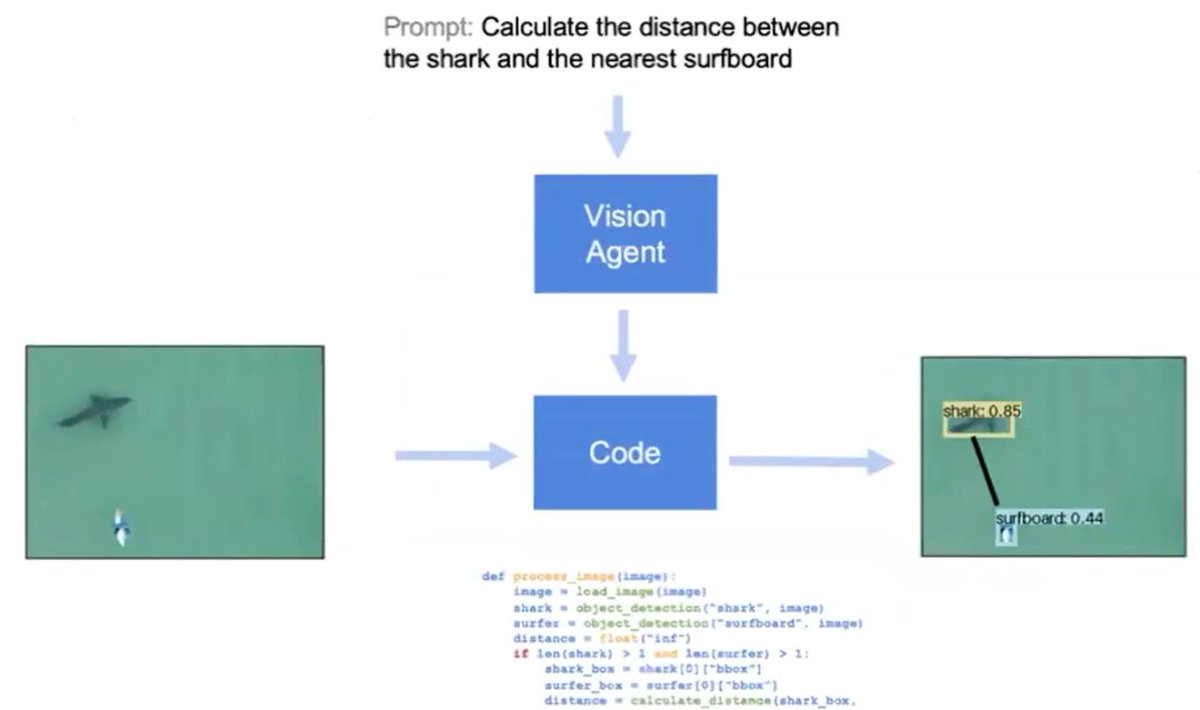
1
0
0
🧵The internal output layer is closest to the token “hood”, which probably doesn’t mean much here because the internal output layers are likely not on the same manifold as the final output layers. You can find the code here

github.com
A simple repo for viewing attention maps of llama 3.1 - dillonalaird/llama-attn-maps
0
0
0
🧵You can see in the example below I’ve asked “Alice and Bob are siblings. Who is Bob’s sister?” and when predicted the ‘s after Bob, it focuses on the 20th output layer of the 45th token which is “sister” in the context “Who is Bob’s sister”.
1
0
0
🧵 I’ve been playing around with the new Llama 3.1 models and built a simple script to help you visualize the attention maps over the predicted tokens (using the final output layer to predict them, sometimes called a logit lens).
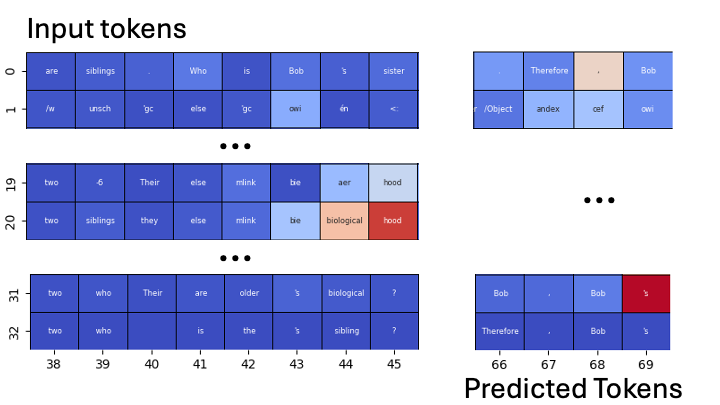
1
1
2
RT @AIatMeta: Introducing Meta Segment Anything Model 2 (SAM 2) — the first unified model for real-time, promptable object segmentation in….
0
1K
0
RT @PascalMettes: Vision-language models benefit from hyperbolic embeddings for standard tasks, but did you know that hyperbolic vision-lan….
0
54
0
RT @mervenoyann: Forget any document retrievers, use ColPali 💥💥. Document retrieval is done through OCR + layout detection, but it's overki….
0
111
0