

Goku Mohandas
@GokuMohandas
Followers
14K
Following
2K
Media
125
Statuses
953
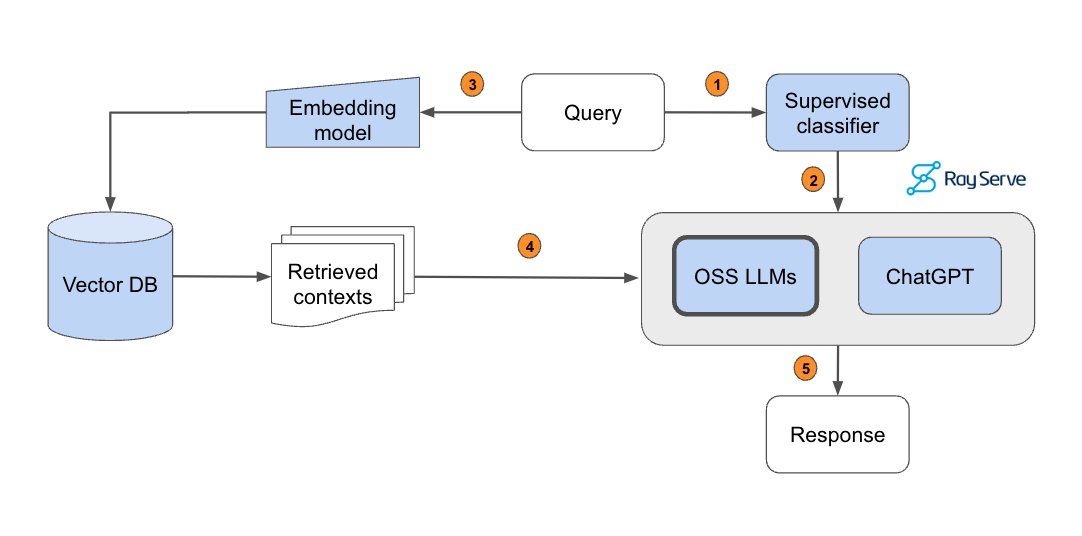
Excited to share our production guide for building RAG-based LLM applications where we bridge the gap between OSS and closed-source LLMs. - 💻 Develop a retrieval augmented generation (RAG) based LLM application from scratch. - 🚀 Scale the major workloads (load, chunk, embed,



31
260
1K
RT @PyTorch: An #OpenSource Stack for #AI Compute: @kubernetesio + @raydistributed + @pytorch + @vllm_project ➡️ This Anyscale blog post by….
0
28
0
You can run this guide entirely for free on Anyscale (no credit card needed). Instructions in the links below:. 🔗 Links:.- Blog post: - GitHub repo: - Notebook:

0
3
11
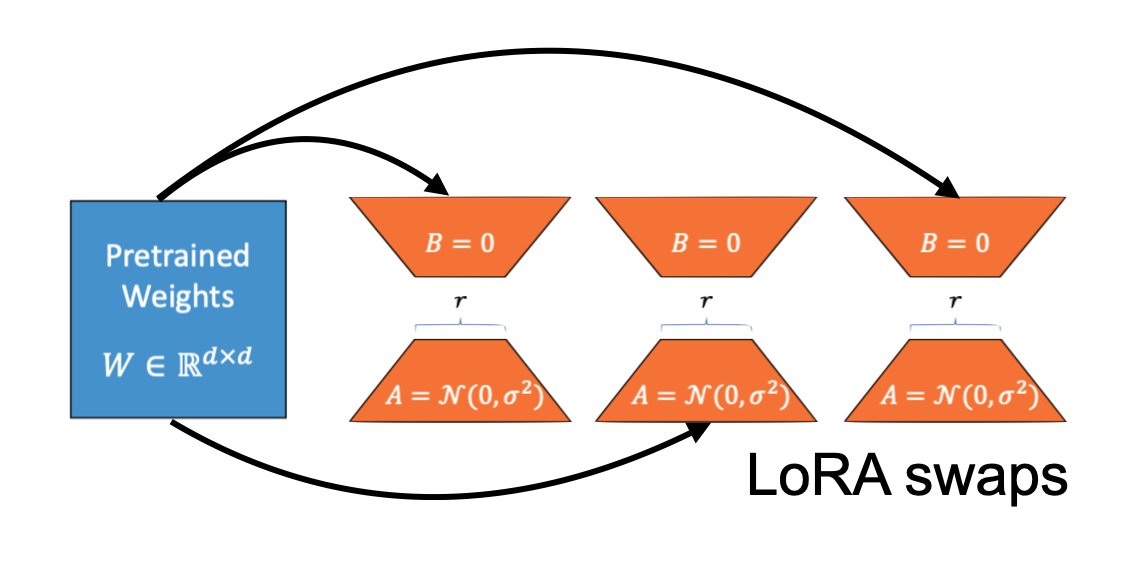
🔄 Swap between multiple LoRA adapters, using the same base model, which allows us to serve a wide variety of use-cases without increasing hardware spend. In addition, we use Serve multiplexing to reduce the number of swaps for LoRA adapters.
1
0
7
🔙 Configure spot instance to on-demand fallback (or vice-versa) for cost savings. All of this workload migration happens without any interruption to service.

1
0
1
🔋 Execute workloads (ex. fine-tuning) with commodity hardware (A10s) instead of waiting for inaccessible resources (H100s) with data/model parallelism (DeepSpeed, FSDP, DDP) and scheduling, fault tolerance, elastic training, etc. from Ray.

1
0
1
Key @anyscalecompute infra capabilities that keeps these workloads efficient and cost-effective:. ✨ Automatically provision worker nodes (ex. GPUs) based on our workload's needs. They'll spin up, run the workload and then scale back to zero (only pay for compute when needed).

1
0
1
🚀 Serve our LLMs as a production application that can autoscale up to meet peak demand and scale back down to zero, swap between LoRA adapters, optimize for latency/throughput, etc.

1
0
1
⚖️ Evaluate our fine-tuned LLMs with batch inference using Ray + @vllm_project. Here we apply the LLM (a callable class) across batches of our data and vLLM ensures that our LoRA adapters can be efficiently served on top of our base model.

1
0
3
🛠️ Fine-tune our LLMs (ex. @AIatMeta Llama 3) with full control (LoRA/full parameter, training resources, loss, etc.) and optimizations (data/model parallelism, mixed precision, flash attn, etc.) with distributed training.

1
0
3
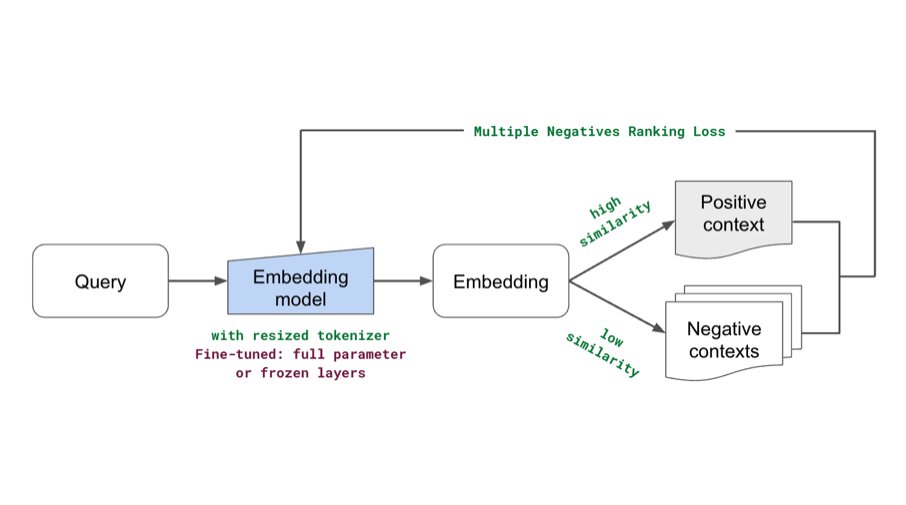
🔢 Preprocess our dataset (filter, clean, schema adherence, etc.) with batch data processing using @raydistributed. Ray data helps us apply any python function or callable class on batches of data using any compute we want.

1
0
5
Excited to share our end-to-end LLM workflows guide that we’ve used to help our industry customers fine-tune and serve OSS LLMs that outperform closed-source models in quality, performance and cost. 1/🧵.
1
45
238
RT @smlpth: I’ve read dozens of articles on building RAG-based LLM Applications, and this one by @GokuMohandas and @pcmoritz from @anyscale….
0
11
0
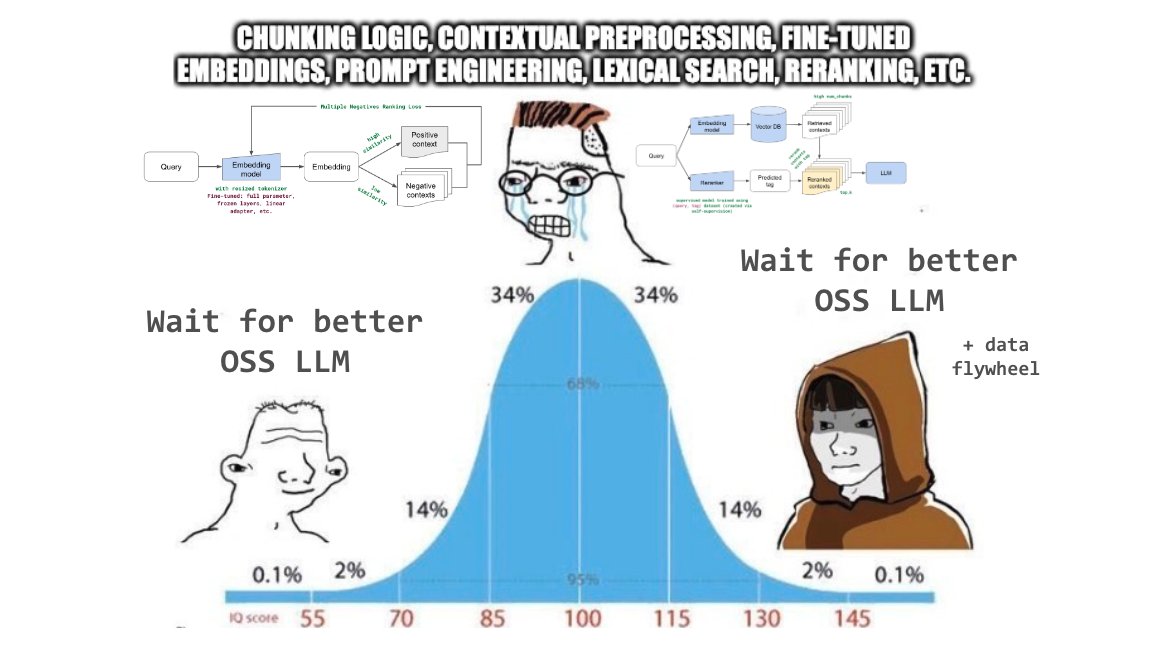
It's been nice to see small jumps in output quality in our RAG applications from chunking experiments, contextual preprocessing, prompt engineering, fine-tuned embeddings, lexical search, reranking, etc. but we just added Mixtral-8x7B-Instruct to the mix and we're seeing a 🤯



12
68
447
RT @bhutanisanyam1: The definitive guide to RAG in production! 🙏. @GokuMohandas walks us through implementing RAG from scratch, building a….
0
90
0
Added some new components (fine-tuning embeddings, lexical search, reranking, etc.) to our production guide for building RAG-based LLM applications. Combination of these yielded significant retrieval and quality score boosts (evals included). Blog:
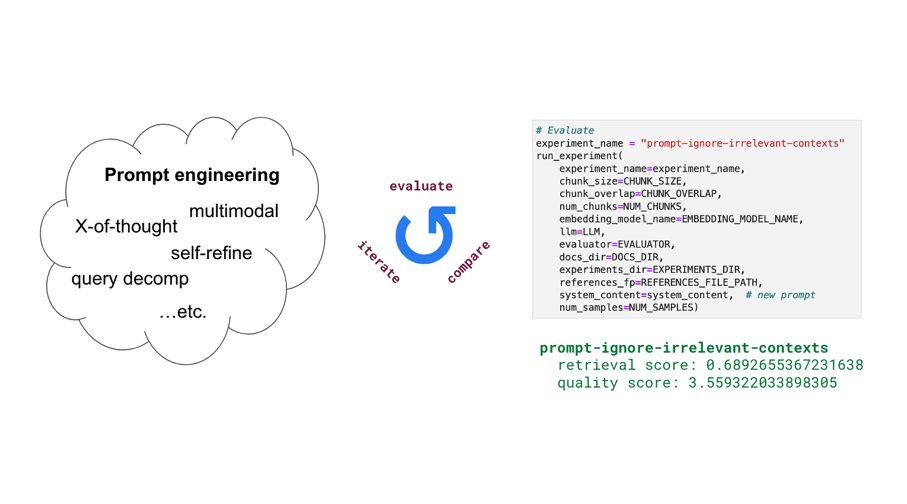
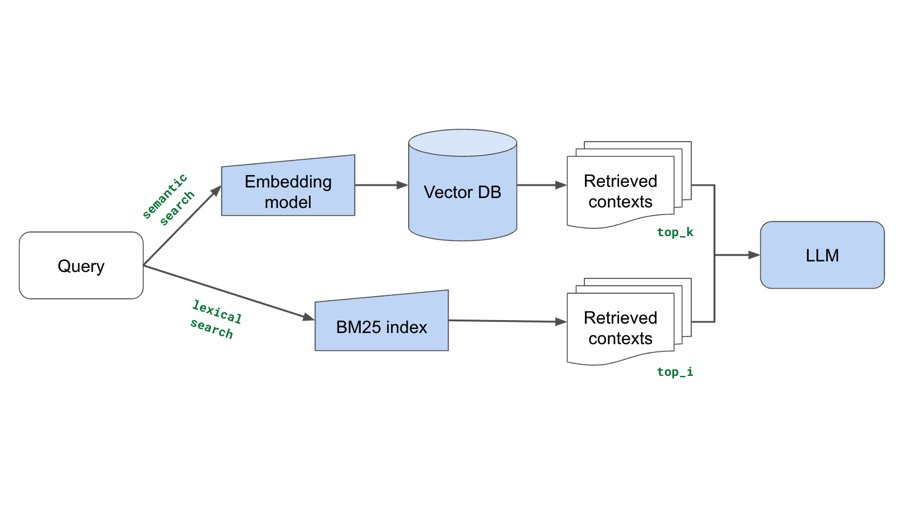
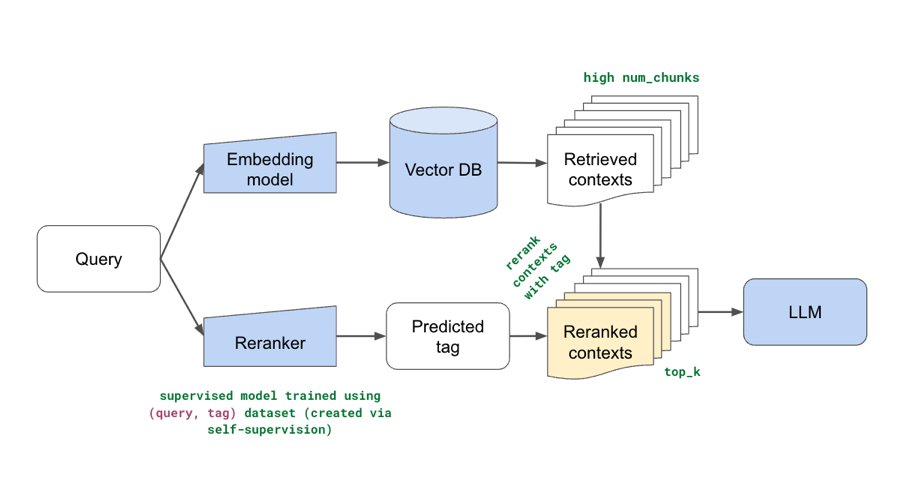
Excited to share our production guide for building RAG-based LLM applications where we bridge the gap between OSS and closed-source LLMs. - 💻 Develop a retrieval augmented generation (RAG) based LLM application from scratch. - 🚀 Scale the major workloads (load, chunk, embed,
7
48
205
RT @chipro: New blog post: Multimodality and Large Multimodal Models (LMMs). Being able to work with data of different modalities -- e.g. t….
0
191
0
RT @LangChainAI: looking for a good read with your weekend ☕ or 🍵?. This series on RAG from @anyscalecompute is full of great stuff!.
0
19
0
RT @bhutanisanyam1: The best guide I’ve read on RAG based LLM Applications! 🙏. It’s a crispy code first tutorial that starts from scratch,….
0
51
0
RT @hwchase17: This is an incredible resource on building RAG-based LLM applications. 45 minute read!!!! Lots to learn.
0
40
0